OODML.How
Chapter 1 - An Overview of OODML
By Alan. A. Katz, CEO, dBASE Inc.
(c) 1998 All Rights Reserved. This material may not be reprinted except for personal use without the explicit permission of the author.
A New Data Language
The very first question has to be: why bother? Why toss out one of the most successful and popular DMLs (database manipulation language) ever created, replacing a well-proven language with a complex, obscure new syntax that takes twice as long to type and months to learn? Why give up:
SELECT Mytable
SKIPin favor of:
this.parent.parent.parent.Query1.rowset.fields["myfield"].next() ?Good question. All that hard-earned expertise down the tubes in a single stroke! In return for what? For dramatically enhanced power, scalability, control, consistency with industry-wide standards, significantly enhanced productivity courtesy of an object-oriented, fully inheritable data language (OODML).. have I forgotten anything?
The new Object-Oriented language is a trade-off. Better software, better connectivity, more sophisticated solutions in return for an (admittedly) steep learning curve and probably more typing than we'd like.
OOP
But even disregarding the many benefits of the new data classes, Borland had no choice but to ditch the old procedural DML. Since dBASE went OOP the language has suffered from a messy conflict between object-oriented forms and procedural data. Any developer who's worked with earlier versions of Visual dBASE hit this wall and hit it hard. The first time your child form trashed the datalinks on your parent form, you became a victim of the unholy alliance of forms and workareas. Who hasn't wrestled with CREATE SESSION? Not to knock the developers (who did their best in an impossible situation), but CREATE SESSION turned out to be a really strange mechanism for publicly-scoped workareas to jump up and attach themselves to the next passing form. Fortunately, the data classes have done away with CREATE SESSION.
I don't want to come off as an OOP purist here. The fact that the Xbase DML isn't object-oriented is not sufficient justification for tossing out a language that's done the job well for more than a decade. The fact of the matter is that the old procedural DML commands just plain do not work with an object-oriented language - no matter how hard the developers tried to integrate the two.Scalability
The second major issue that drove the move to OODML is Scalability. Times have changed. We live and work in a world that's more connected every day. With LANs, WANs, Extranets, Intranets and the Internet exploding all across the landscape, the days of the stand-alone application are rapidly coming to a close. At some point in the not-too-distant future (if you haven't already), you'll be asked to connect to something: a back-end accounting solution, a remote server, a Web server, a Palm Pilot or POP server. Or your client's request might be as simple as exporting or importing data between your application and someone else's.
If you're a corporate developer, this is yesterday's news. Your applications already communicate with departmental servers, corporate databases and the head office in Chicago. You independent developers and consultants writing applications for the small business market may be skeptical, but scoff at your own peril! Believe me, within a few years, everything will talk to everything - desktops to LANs, LANs to WANs, Cell phones to the Web and on and on down the line to the TV in the den and the toaster in the kitchen.
All of this communication will be data. And there's only one lingua franca, one universal language shared across databases, platforms, languages and applications. And that's SQL (also known as Structured Query Language). If we're going to connect, it's SQL we'll be using. Which makes SQL very, very important to the dBASE developer.
Both Visual dBASE and its predecessor, dBASE 5.0 for Windows, supported either pass-through SQL ( SQLexec() ) or embedded SQL (as of Visual dBASE 5.5), but neither offered a tight enough integration to provide serious scalability. SQL was one of the other languages in the box. Code written for local tables ( DML) ran well enough against remote DBMS servers, but failed to leverage their unique capabilities. Code written for dataset-oriented remote servers (SQL) was not only slow against .dbf tables, but essentially incompatible with their record-based architecture. As a result, the only way for one application to talk to both types of databases effectively was to write the application twice. Make that "write, test, tweak and deploy" twice.
The new Visual dBASE 7 OODML marries SQL, DML and OOP into a single set of common data-access classes. These classes can be used (and re-used and inherited from) to access every major database format from .dbf to DB2 with a high level of integrity and performance. This is the essence of true scalability - one single set of source code that runs with equal aplomb on a single-user PC, against an NT server running Interbase or against a Digital server running Oracle. The new data classes in Visual dBASE 7 provide code-free scalability. Write once, connect to anything. Scale your applications by changing an alias in the BDE Administrator. No recoding, recompiling or redeployment required.
Programmability
The most compelling reason for the shift to OODML is us - the dBASE developers. For years we've begged for more and more control over the data environment. In Visual dBASE 5.5, we got access to the record buffer (BeginAppend()/SaveRecord() ). Not a bad start. But not even close to Visual dBASE 7 in which we get almost complete control of just about everything. The Visual dBASE 7 development team surfaced a huge number of the low-level database operations formerly hidden behind the DML. They wrapped them in programmable, inheritable classes and graced them with properties and methods that deliver power and flexibility beyond anything ever before contemplated in dBASE.
Now you can program data. Your own code can sit between the datalinked control and the field it's linked to. Can't do something easily in the Grid? No problem, write the code in the data objects linked to the Grid! Need to store data formatted for indexes, yet you want the user to type it the normal way? Great! Use beforeGetValue and canChange to morph the field - make it look one way to the user, another to the database. Want to automatically look up one value based on another? Piece of cake - it's built right in. How about this one: every time an inventory stock number is changed, have your data object look it up, validate it, store the description, cost and unit price in the appropriate fields, update quantities, post the transaction and recalculate LIFO, FIFO or average cost. Not just in this one application, but in every application that uses this query from this day forward.
Wow. Scalability, programmability and portability in a single set of classes. If the conflict between objects and workareas or the dramatically improved scalability that springs from the unification of SQL and DML are not enough to justify a whole new data-manipulation language, the stunning power of the properties, methods and events of the data classes certainly is! At least for developers who want to create more and better applications and be more productive developing them. The old DML is still there (with a few limitations), so those of you who just want to port 16-bit applications to 32-bit without taking advantage of the dramatic 32-bit enhancements can still do so. But I can't imagine why you'd want to.
Tip: About the old DML. Although it wasn't removed, it was rewritten, and rewritten in such a way that I don't recommend using it unless there's a particular operation you need that's not directly supported by Visual dBASE 7's first-generation data classes. The procedural DML (USE, GO TOP, SKIP, SEEK) is no longer a native language. These legacy commands are mapped to the new data layer that underlies the data classes. As such, DML commands have to undergo translation before they execute, resulting in slower execution than the native Database, Query and Rowset classes for many operations. Batch operations like Scan and Replace All (neither of which are supported in the data-access classes) are not mapped, and therefore match or exceed their performance in earlier versions of Visual dBASE.
Another Tip: About SQL. For those of you who have little or no experience with Structured Query Language, don't panic. Aside from a single SQL statement required to load data into your data objects, you don't need to know much (if any) SQL to work with dBASE or Paradox tables. Almost all of the familiar DML commands from days gone by have equivalent properties and methods in the new data classes. For example, SET RELATION is now MasterRowset and MasterFields. SKIP is rowset.next(). GO TOP is rowset.first() and SET KEY TO is rowset.setRange(). For more information on equivalent commands and methods see the "Xbase/OODML Equivalents" chart at the end of this chapter.
Yet Another Tip: Again, about SQL. Even if you have the need (or desire) to use more robust SQL statements (for DBMS engines, reports, joins, etc.), don't panic! Visual dBASE 7 provides a really neat visual SQL Query Builder tool. It writes your SQL statements for you. It's also a terrific way to learn Structured Query Language on-the-fly.
Data Layers
There's two ways you can learn a development language. You can memorize syntax and program by rote; or you can master the technology that underlies your language and understand what you're doing while you do it. I'm a strong proponent of the latter. It's the old adage "if you teach a village to fish, they'll feed themselves forever". If you understand what's going on underneath the data classes you'll avoid hundreds of hours of flailing around in syntax trying to get your applications to work.
In that spirit, before we introduce you to the new Data Access classes, we need to take a few moments to discuss layers. It's been a long, long time since any application consisted of a single layer (since assembler days?). dBASE is no exception. In fact, even in its earliest incarnations, dBASE data was accessed through layers. Back then, the layers were buffers, but were essentially no different from the much more sophisticated data layers of today's dBASE.
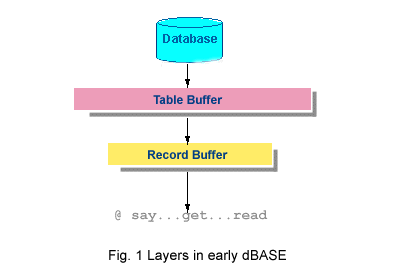
In figure 1 above, you'll see that there were two major layers between your application and the operating system (which, by the way, had its own buffers, but we'll skip that for the moment in an effort to avoid unneccessary complication). The lower layer, the Table Buffer, was a small chunk of data (generally around 4-16 KB in size) loaded from the hard disk or LAN server into the memory of the workstation.
The table buffer represented a small, manageable segment of your working data - the subset of records reflecting the constraints you applied to the table with filters, ranges, deletions, relations and the like. Or, if you applied no constraints, your set consisted of all the records in the table. This working data set is called a cursor and is still the underlying architecture of all major databases, including Visual dBASE 7. Ever wondered why you need GO TOP or some other record-pointer movement to enforce a SET FILTER or SET KEY command? To refresh the cursor, which is "requeried" only by record-pointer movements. Therefore, a filter doesn't do a darned thing until dBASE goes and gets a new set of records (a new cursor). After all, who's to say that the current cursor contains the rows that meet the conditions of the filter or that it doesn't have rows that violate the condition of the filter?
Note: If we want to get really technical about it, the "working set" of records to which we refer above should more properly be called by one of its common names: answer set, return set, data set or row set. When that "chunk" of rows and columns is assigned a "handle" with which to grab it and a pointer to move through it's rows it becomes a "cursor". The term "cursor" derives specifically from the presence of the row pointer.
The second data layer was the record buffer. This was a copy in memory of the currently selected record. This copy was created whenever you edited a record with @...say...get....read. As a dBASE developer, you had little control over this data layer except by forcing "saves" through record pointer movements, closing tables or exiting a READ.. You had no direct control whatever. You couldn't freeze the screen while you went and did a lookup, you couldn't decide to abandon the user's entries programatically. You simply didn't have access to the "get" process except through Picture and Valid statements.
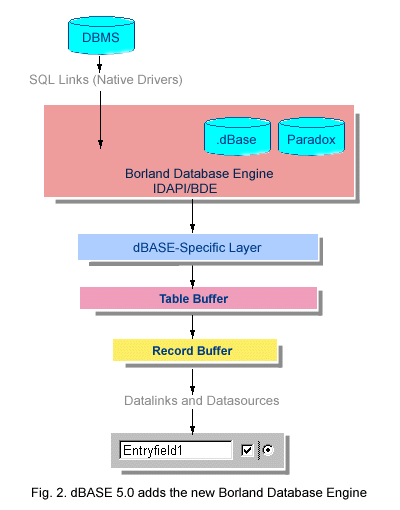
All hell broke loose in dBASE 5.0. In what would turn out to be a brilliant move, Borland de-bundled the data engine from the language. Up to this time, all versions of dBASE were single, integrated products comprised of interpreter, language and database engine. With the introduction of the Borland Database Engine, the language and its virtual machine engine became one component, the database engine another. The primary purpose of de-bundling was to make all of Borland's database technology available to all its languages and products (which it did) while offering a stand-alone data layer for resale (unfortunately, it didn't sell very well). The BDE rapidly became the backbone of all of Borland's tools. It performed the real database work for local tables (updating, indexing, cursors) and passed on commands to (and fed back data from) remote servers. Each development team at Borland wrote a language-specific interface to communicate with the BDE. The dBASE-specific layer was optimized (on top of the BDE's optimization) for the unique record-oriented architecture of the traditional Xbase DML.
The neatest thing about the BDE (and the most significant to those of us developing in Visual dBASE 7) is that it allows applications to access the built-in data engines (dBase and Paradox) or remote servers like MS SQL Server, Oracle or Interbase - transparently. The BDE performs any adjustments or optimizations required to get the most from the rich assortment of database engines supported by the BDE and its set of native drivers, SQL Links.
Note: Just a point of information: One of the first products to use the BDE was, of course, Borland's unsung hero, dBASE. dBASE 5.0's runtime was built atop a portable byte-code conversion layer instead of a built-in P-Code interpreter (semi-compiled code, like Clipper and FoxPro). This technology was dubbed the "Virtual Machine Engine". Hmmm, how many years before Java did the same?
One more extremely important layer was added in dBASE 5.0 for Windows: the datalink. User-interface data-entry controls could now be linked to fields of the record buffer, supplying automatic display, editing and updating. Not only did this save a huge amount of DML coding (making @say...get obsolete in the process), it made access to the database event-driven, without which the Windows interface would be almost unmanageable. However, this datalink process, in keeping with the philosophy of dBASE up to that time, was automated and masked - it was outside the control of the programmer. The result was some pretty hairy problems refreshing Browses and getting forms to stop repainting every time you moved the record pointer. dBASE 5.0 was infamous for flashing screens (some screens flashed literally for minutes before stabilizing) and uncontrollable refreshes. Nice start, but not quite there yet. This inaccessible datalink layer was quite a bit too automatic.
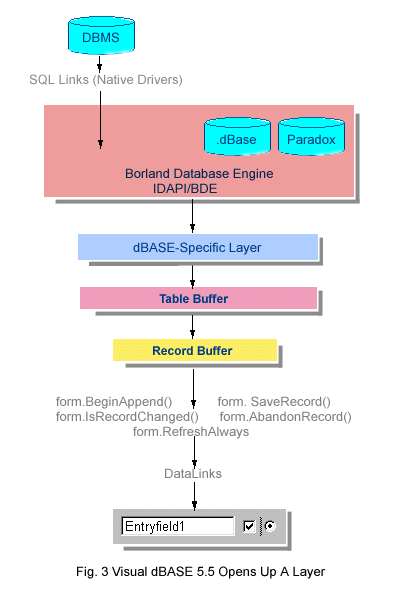
Visual dBASE 5.5 marked the beginning of a major change in dBASE. At the behest of dBASE programmers (who have never been known to be reticent in their requests), Borland opened up the record buffer layer in Visual dBASE 5.5 and surfaced significant control to the developer. The three new data-entry methods: BeginAppend(), SaveRecord() and AbandonRecord() and the "state" method, IsRecordChanged(), gave explicit access to the "get" process with substantially improved control over validation, navigation, appending and editing. The new RefreshAlways property allowed us to detach the datalinked controls (at the form level only) from the table temporarily so that the form would not endlessly repaint as we navigated through records. This was a major improvement in dBASE data programming, and an overall change in dBASE philosophy. As the ultimate high-level language, dBASE had always hidden its underpinnings as much as possible from the user. Visual dBASE 5.5 demonstrated a 180 degree change in attitude, surfacing a major piece of the inner workings of dBASE to the developer. My choice of words wasn't accidental. Earlier versions of dBASE targeted the user. More recent versions, reflecting the changes in Borland (now Inprise) itself, were aimed squarely at the developer.
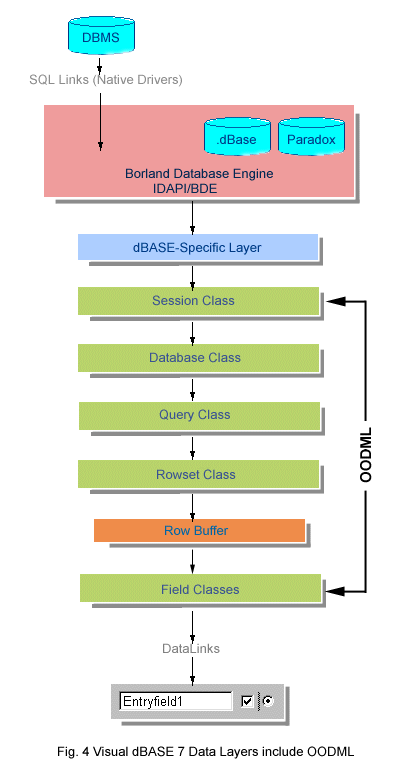
We finally come to Visual dBASE 7, which sports the most radical changes in database manipulation in the history of dBASE. Talk about layers! There were more layers added in Visual dBASE 7 and more programmability surfaced than in all the previous versions combined. Not only is the core of automated functionality that lay beneath dBASE explicitly exposed, additional layers were built in to provide access to the links between the layers.
Note the five layers rendered in green in Fig. 4: Database, Session, Query, Rowset and Field. Each of these layers represents a level of data manipulation and management functionality that was formerly hidden beneath the covers of dBASE. For the sake of consistency, productivity and reusability, they are surfaced as classes. These classes, taken together, constitute the core of the Visual dBASE 7 OODML.
These new classes represent an unprecedented level of flexibility and control for dBASE developers. Using them, you can directly invoke database operations by calling an object's methods, automatically trigger actions in response to data-related events, validate, accept or deny changes at the data level (formerly, this was only possible at the user-interface level), set up rules and specify queries using their properties, and last (but perhaps most important), add your own custom methods and properties to each of them to tailor their capabilities to your needs, your clients' needs and the needs of your application.
Note: I must admit that I thought it might be cheating to include Session and Database as new layers. Although it's true that Sessions and Databases existed in earlier versions of dBASE, "Create Session" and "Set Database To" were such primitive and limited constructs that they bear almost no resemblance to Visual dBASE 7's Session and Database classes. You couldn't program a session or database - they had no events or methods. "Set Database" couldn't even pass on a password, and neither had a handle or object reference you could use to create or destroy them. So, although they existed, I don't think anyone would suggest that they were "surfaced" to the developer. Well, let's say they were "barely surfaced" and now they're "really surfaced".
These five classes are not the only objects in the OODML. There are many intermediate objects, some of which have methods and some of which don't. You'll find that several of the data classes create nested objects, reflecting the many new strata of containership in Visual dBASE 7. For more on this, see the section in the following chapter entitled "OOP Data". Suffice it to say that the five classes: Database, Session, Query, Rowset and Field are the primary classes with which you'll work when creating, editing and manipulating data.
Let's take a quick general overview of these five classes, and what they're used for.
The Session Class
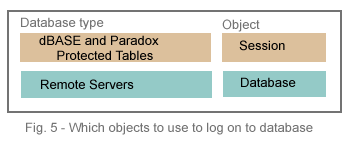
The Session is the highest-level OODML class. As an object representation of the user, its main purpose is security.
The term "database" has an entirely different meaning in the context of dBASE and Paradox tables than it does when applied to remote DBMS servers. A dBASE or Paradox database is just a collection of tables referenced by the folder in which they reside. Any of these tables can be opened and accessed individually. DBMS databases, on the other hand, are usually a single disk file which requires a username and password before you can get at the tables within. When a dBASE or Paradox table is protected, it too requires a username and password. But dBASE and Paradox tables have no central structure through which access may be acquired or denied. Therefore, Visual dBASE 7 provides login capabilities in two different classes, the Session class and the Database class, to accomodate the architectural differences between local and remote databases. dBASE and Paradox security is Session-based. Security for DBMS servers is database-based.
To access .dbf and .db tables using a Session object, call its password() method to add a new password to the current list. Call its login() method to log the user on.
The syntax for creating a new session is :
s1 = new session()
A note about syntax. Even though the session is logically the top level OODML object, it is not syntactically the top level object. Theoretically, you might expect the syntax that represents a session and a database within that session to be:
_app.session.database[1]
But it's not. The session is a stand-alone object which is attached to other objects as needed. For example:
_app.database[1].session = s1
or
form.customer1.session = s1
The Visual dBASE 7 object model is significantly more complex than earlier versions. Containership has become a major issue (since there are many containers in Visual dBASE 7, and only two: form and menu in Visual dBASE 5.6). This is an issue with which you'll have to come to grips sooner than later. Though the session includes all databases attached to it, it's not a formal container in and of itself. Therefore, though databases may be "under" a given session, database objects are not contained within session objects. The reason is simple: the Session object may be shared by any number of databases and queries - even queries without their own explicit databases.
When do you create Session objects? Almost never. Visual dBASE 7 provides a default, built-in session that's already attached to the default built-in database object. You can reference that session using the following syntax:
_app.databases[1].session or
_app.session
Unless you have a compelling reason for hosting two users in the same application on the same machine at the same time, there should be no reason to ever create a new session.
Important: The original Visual dBASE 7 documentation may be misleading in this regard. It suggests that you need two sessions to support two instances of the same form open on the same user's desktop at the same time. For example, if you have two customers simultaneously displayed in two instances of a customer form, each customer would require its own session to protect it from the other. That was true in Visual dBASE 5.5/6 but is not true in Visual dBASE 7 (at least as of 7.01, when locking was moved from the Session class to the Query class). The data objects are objects, and are thus already encapsulated and entirely protected from each other. Unless you explicitly share data objects across two forms, each one is totally independent and protected from each other at all times. No additional sessions are needed. I believe the new documentation has been updated to reflect this.
One remnant of the old session-based locking remains in the current Session class: lock configuration. You can set the retries (the number of times a lock will retry before it complains to the user) and the interval between retries courtesy of the lockRetryCount and lockRetryInterval properties of the Session Class.
The Database Class
The Database provides most of the capabilities you'll need to manage your databases, tables and security.
Security If you're using a remote DBMS engine, the database class serves as the front door to your file server. If a loginString is specified, the database class automatically attempts a login as soon as its active property is set to true. This class is not just for remote engines - any configuration that uses a BDE alias to manage its database (including any collection of .dbf or .db tables) requires a database object in order to open the alias in the BDE. The BDE returns a "handle" property to the Database object, which is helpful if you do any direct BDE calls.
Management The management features of the database class include control of table-level operations that used to be executed as commands. You no longer ZAP a table, you:
_app.databases[1].emptyTable('Customers.dbf')
Similar method calls exist for copying tables (copyTable), packing tables (packTable) and even deleting tables (dropTable). The Reindex() method of the database class replaces the REINDEX command of earlier versions of dBASE.
There are some unique scoping issues that you should keep in mind when using the methods of the database class. Being an object, it is encapsulated - hidden and protected from all other database objects. Which means that you can only reindex, pack or drop tables that exist within the current database. Make sure you're in the right database object for the tables you wish to work with. If you haven't specified a BDE alias and your .dbf tables are just hanging around in their respective folders, use the built-in default database object,
_app.databases[1]
to manage those tables.
You'll note from the syntax above that the default database object is an array element. That's true only for the default database and any other databases opened in the interactive environment using the Navigator. All other databases have their own programmer-defined object reference like most other Visual dBASE 7 objects:
oDb = new Database()
oDb.databaseName := 'Mycompany'
oDb.active = trueDatabase objects have one other critical mission - transaction management. There are two ways you can isolate multiple rows to ensure that everything gets updated (or nothing gets updated) in the original tables: the cacheUpdates property and the trasaction methods (beginTrans(), commit(), rollback()) of the database object. Your ability to leverage these properties and methods depends to a great extent on the capabilities of the engine you're using. CacheUpdates is new to dBASE. It allows you to save all "writes" as in memory until you specifically call the applyUpdates() method to send them back to the database or their respective tables. If you decide the transaction should be cancelled, call abandonUpdates().
Tip: One of the most important properties of the database class is "share". I recommend that you always set this property to 1 (share all). The "share" property causes the database object to share its connection to the server with other database objects accessing the same database. To the developer using local tables, this doesn't mean a thing, but to developers with remote servers, it's absolutely critical. Remote engines are licensed per user. If you don't set share to 1 (share all), you'll use up another license every time you open the database! You could conceivably run out of licenses with only a single user connected! By setting share to 1, the user only logs onto the database the first time you connect. From then on, all database objects linked to the same database use the existing connection. By the way, don't confuse the share property of the Database class with the share property of the DataModRef class - they're entirely different things and totally unrelated.
One other tidbit. The database class provides an executeSQL() command for sending pass-through SQL statements to your file server. This is important as new iterations of each DBMS engine add new features and proprietary extensions to SQL which may not be supported in the standard ANSI implementation in Visual dBASE 7.
The Query Class
Our user has logged on (Session), we've opened our database (Database). Now it's time to obtain some real data to use in our applications. That's exactly what the Query class does. It defines the rows and columns that make up your working dataset. The Query object tells Visual dBASE what records you want, what fields you want, what table to get them from and in which order. It does this with a single SQL statement stored in the Query's sql property:
select firstname, lastname, address, city, state, zip from "customer.dbf"
where city = 'New York' order by lastnameThe simple statement above contains all the information needed to define your cursor:
- Select is the SQL command to "go get me some data".
- firstname, lastname, address, city, state is the list of fields you want as columns in your new cursor.
- from "customer.dbf" tells dBASE (or your DBMS server) where to find the data.
- where city='New York' specifies the filter conditions (if any).
- order by determines the order in which the rows will be presented.
To be honest, it just doesn't get much simpler. The old Visual dBASE procedural DML required much more code to do the same:
Use Customer Order LastName in Select()
Select Customer
Set filter to City = "New York"
Set Fields to customer->firstname, customer->lastname, customer->address, customer->city, customer->state
Go TopYou'll note that the SQL statement is significantly more economical than the equivalent DML code. This concise, industry-standard syntax is executed automatically when a Query object's active property is set true. When you set "active" back to false, the cursor is lost. The next time you set it true, a whole new query is executed and a new cursor obtained from the server or hard disk.
Tip: The sql property of a query object can be changed at runtime. Setting active false, then true to enforce the new sql string is a like swatting a fly with a sledgehammer. A change in the value of the active property fires events that you might not want to fire when you're just changing the constraints on your Query. Instead, use Query.refresh() to obtain a new live cursor that reflects the changes in your sql string, or Query.requery() when you change the value of a variable used in your sql string, but not for changes to the string itself.
The SQL language supports wildcards that can make specifying fields even simpler than the example above. If you want to include all the fields in a table in your Select statement, substitute an asterisk for the fields list:
select * from "customer.dbf" where city = 'New York' order by lastname
Important: Always keep in mind that you don't go out and get your data - the Query object does. Therefore, you never actually execute the SQL statement. You tell the Query object the code you want it to execute and the Query object does the job. Which means that the sql property of a Query object is not really a SQL statement - it's a string! That's an important distinction because you've got to exercise great care when you combine SQL commands with variables or properties. If you don't, you may end up with surprising, unexpected or even disastrous results.
Let's look a little closer look at this since this is an area that often trips up even experienced Visual dBASE programmers. Building a SQL string with variables requires some real planning. The "timing" of the variable (when it's declared and when it's used) can make a critical difference in the results you obtain. A variable may be used when a query is instantiated (created) or when the query is activated. To differentiate the two, let's call the former constructor and the latter runtime.
Constructor If you use a variable in the constructor of your Query object, it's evaluated when the SQL string is built, not when it's executed. Therefore, the value stored in the variable gets linked to the string, not the variable. Here's an example:
// Declare variable in VdB application.
cCustno = 'SmithCo'// Here's the generic SQL statement we're trying to get
// the Query object to execute for us:
// Select * from "customer" where custno = :cCustno// Here's the SQL statement above converted to a string,
// with "cCustno" evaluated in the constructor of the Query
// object:
this.Query1 = new Query(this)
with (this.Query1)
sql = 'Select * from "customer" where Custno=' + "'"+cCustno+"'"
endwithWhy is "cCustno" in doublequotes and quotes and concatenated on to the end of the first half of the SQL string? Because "cCustno" is evaluated when the Query is created. By the time the Query is activated, "cCustno" may no longer exist. It sees SmithCo instead. Furthermore, you need the single quotes to indicate that it's a string (SQL uses single quotes to delimit strings):
Select * from "customer" where Custno = 'SmithCo'
Tip: Be careful. If the variable "cCustno" is not declared before you instantiate your form or report, Visual dBASE will return an "undefined variable" error. Remember, cCustno will be evaluated when the Query object is "constructed", which means that your variable has to be declared and in scope before the form or DataModule is instantiated.
You may not run up against the "constructor" model for building SQL strings all that often. It represents a relatively static way of setting your data selection criteria. On the other hand, I can think of at least one really good case. I've written reports, on many occasions, that get fed a single name or value before they're rendered. All the data on the report is filtered by that preset name or value. Since the selection criteria for the report are fixed in advance, this "constructor" syntax works just fine (The Visual dBASE 7 drill-down report Wizards work this way). Just be sure to use either a public variable or a global "_app" property to ensure that your variable is in scope and accessible when the Query instantiates:
// declare global _app property:
_app.cSearch = 'SmithCo'// Reference the custom property during the
// constructor of the Query objectwith (this.query1)
sql = 'Select * from "Customer" where custno = '+"'"+_app.cSearch+"'"
endwithHot Tip: Writing the string is pretty simple stuff - except for the delimiters. You may want to simplify your expression by using square brackets (the three delimeters in Visual dBASE are: single quote, double quote and square brackets). If you ever get stuck trying to decide what gets quotes or doublequotes or what gets included in the main string or gets concatenated, there's a simple rule-of-thumb: make believe it's a macro!! Makes sense. A macro takes a string just like the Query's sql property does - and executes it later, just like the Query. If you're an experienced dBASE programmer, you've wrestled with macros before and you can leverage this experience into a quick start on the Query class
Runtime The runtime model is the one in which the variable or property used in your SQL statement is evaluated late - when the Query object activates. This is, by far, the more common model, since you often don't know your selection criteria until runtime. This is true of all queries based on user-selection or user-input. It's a much more dynamic approach to the SQL statement. Unfortunately, it also presents a host of potential problems - especially when you're basing your selection criteria on object properties or the values of fields in other queries. Among the possible obstacles are keywords (SQL doesn't like the term "value", for example) and massive scoping and syntax confusion:
form.query1.sql = 'Select * from "customer" where custno = '+; "'"+this.parent.query2.rowset.fields[Custno'].value+;
"'"See what I mean? Fortunately, Visual dBASE 7 provides a wonderful, easy way to dynamically set the selection criteria of a sql string.
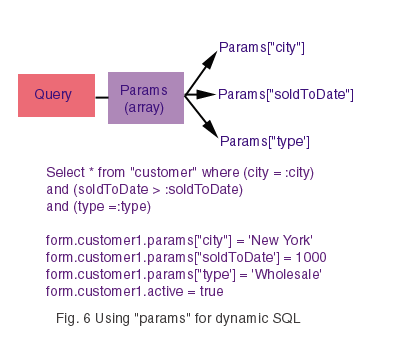
The params property of the Query class is another associative array (elements are referenced by name, not by numeric subscript) that's generated automatically from the "where" statement of your sql string. All you have to do is define each parameter with a colon:
form.query1.sql = 'select * from "customer" where custno = :cCustno'
In the expression above, Visual dBASE 7 automatically adds a new 'cCustno' element to your params[] array. This element is just sitting there waiting for you to assign it a value from an object on your form, a custom property, a variable or data from another query. Just one caution - you must not activate your query before you assign a value to "form.query.params['cCustno']" or you'll get an "undefined variable" error. So, always be sure to set the "active" property of a Query to false if you're going to use the params property of a Query object:
this.query1 = new query()
with (this.query1)
// note the colon before cCustno -
// that defines it as a parameter
sql = 'select * from "customer" where custno = :cCustno'
active = false
endwithThen, when you want to select data to match user-input:
function pushbutton1_OnClick
with( this.parent)
// set the value of the "cCustno" parameter
customer1.params['cCustno'] = form.entryfield1.value
// turn the query on
customer1.active = true
endwith
return trueTip: The Query class has a canOpen event that fires when you set the Query's active property to true, but before the sql string is evaluated. Query.canOpen is the perfect opportunity to set default parameter values.
Another Tip: Sorry. In our enthusiasm to demonstrate the powerful features of the Visual dBASE 7 Query class, we've gotten just a bit ahead of ourselves. We haven't yet defined rowsets, but it's impossible to discuss queries without using the term. So here's a quick definition: A rowset is the set of data returned to your application when a query is activated. It's your "working set of data", your cursor. For more detail, see the section immediately following this one: The Rowset Class.
Parameterized Queries There's an interesting sidelight to Visual dBASE 7's support for parameters in sql strings. You can use parameters in combination with the Query's MasterSource property to create a special type of paramaterized query in which a child cursor gets automatically updated whenever the value of a "link" field in a parent is changed. The change can be the result of a row-pointer movement, a programmatic change in the field's value or data input by the user. This is a SQL-based method of defining one-to-many relationships between a rowset and a table. To create a "MasterSource" parameterized query you need only set two properties:
First, set the MasterSource property of the child query to the parent rowset:
form.invoice1.masterSource = form.customer1.rowset
Second, write a SQL string (also in the child) that includes a parameter with the same name as the field in the parent rowset that will be used to link parent and child:
form.invoice1.sql = 'Select * from "Invoice.dbf" '+ ;
'where Custno = :CustomerNumber'To paraphrase the statement above: Give me all the fields from the invoice table where invoice->Custno = Customer->CustomerNumber. We've assumed that the parent rowset has a column called "CustomerNumber" which corresponds with the column "Custno" in the child rowset. All you do is write the "where" segment of the SQL string to include the parent column name preceded by a colon to tell dBASE that this is a parameter, not a variable. Whenever CustomerNumber changes, either through edits or row pointer movements, dBASE will requery the table using the new value of :CustomerNumber.
Tip: There's an apparent bug in Visual dBASE 7.01 that prevents you from using a fieldname that has spaces in it with "MasterRowset". Check the Visual dBASE Newsgroups for a workaround.
Note: If you're using .dbf or .db tables, don't use parameterized queries. Stay away from MasterSource. Let me qualify that: use them only if the child table is very small. In all other cases, performance is truly terrible. Each time the parent rowset moves, an entirely new SQL Select is executed against the child table. If your table has thousands of records, you might want to take a coffee break before moving the row pointer again. On the other hand, remote DBMS servers are optimized to do exactly this kind of on-the-fly requery and can achieve excellent results even with huge tables.
Tip: The rationale behind using SQL for row selection is inescapable - some language had to be used to define your working dataset, there are no comparable inline commands or functions in dBASE, SQL is a universal language, and it runs against all kinds of engines. Why reinvent the wheel? One other benefit to using SQL as the definition language for the cursor is the Join. You can create a single dataset from more than one table, explicitly specifying inclusive and exclusive selection criteria (Give me all of the customers in the Customer table who do not appear in the BadCheck table; or, give me all of the customers in the BadCheck table plus all of the customers in the Overdue table, but only list each once). The resulting data appears as a single rowset. It's like creating a new ad-hoc table on-the-fly from existing data. Visual dBASE 7 even supports heterogenous Joins - you can combine an Oracle table with an Interbase table and work on the resulting cursor. There is a downside, however, to all this cross-platform connectivity. No two engines support the exact same feature set. For instance, joins of .dbf tables amost always result in "read-only" rowsets, since the dBASE engine in the BDE doesn't have much capability to deconstruct complex Joins and return the values of changed fields to the right tables. Only the simplest .dbf Joins result in "updateable" rowsets. On the other hand, almost all joins using Interbase tables result in rowsets that distribute any changes you make to all the appropriate tables and fields in the original database.
Another Tip: Complex SQL commands can be stored in a disk file (*.sql). Instead of defining a string for the sql property of the Query, Visual dBASE 7 gives you the ability to link directly to this disk file. When specifying the sql property, just type in the name of the file preceded by "@":
form.query1.sql="@myStatement.sql"
This is the easiest way to get SQL commands generated by the Visual dBASE 7 SQL Query Designer into your Queries.
OnOpen, OnClose The primary purpose of the Query class is assembling your working dataset. However, the Query class has two very handy events that give it another major role in OODML: onClose and onOpen. The presence of two such standard events may not seem to be of earth-shaking significance. But, in fact, it is. That's because the Query class is one of only two data access classes that feature onOpen and onClose events (the other is the storedProc class, which, under certain conditions emulates the Query class. More on this later in the chapter). Need to set a property, read a field or call a method (such as BeginAppend()) when a form opens? Or when you reQuery? This is the only place you can do it from within a data-access object.
Tip: The onOpen of the Query is not the same as the onOpen of the form. The Query's onOpen fires after it has successfully executed its SQL "Select" statement, not when the form opens. OnClose fires when you set the Query object's "active" property to false or destroy the query (which sets its "active" property to false). However, there is a coincidence that allows you to use the onOpen of the Query pretty much as you'd use the onOpen of the form. Most queries are instantiated with active=true (that's the default), which means the query is instantiating almost simultaneously with the form. That being the case, you can indeed build a beginAppend() into the Query's onOpen and your form will open with a brand new empty row buffer waiting for user input.
The Query class has a few more interesting properties such as requestLive, unidirectional and updateWhere that determine the type and behavior of the cursor generated by the Query object. For more on these, see the following chapter, Using OODML.
The Rowset Class
Of all the new data layers in Visual dBASE 7, the Rowset is the most significant. It requires the most "rethinking" because it represents a sea-change in the way dBASE looks at data. It's the end of the "hidden cursor". No more make-believe that we're dealing with a single record among all records. SQL servers don't work that way, Paradox doesn't work that way, dBASE doesn't even work that way. They all work on subsets of rows and columns (also known as datasets, answer sets, return sets or rowsets ).
The cursor is surfaced in the new Visual dBASE 7 OODML as the Rowset class. Rowsets are objects representing copies of "chunks" of table records whose range you define using a SQL Select statement. It's that simple.
At first glance, the concept of "rowset" may look suspiciously like an unneccessary restriction to a dBASE programmer used to working with "entire" tables. However, that's another of our dBASE fictions. No one works with two hundred thousand records at the same time. That's data, not information. To be meaningful, data has to be reduced to a summary set that the mind can grasp and use for making business decisions. A report of 200,000 records, even assuming one line per record, would occupy more than four thousand pages. No one works with four thousand pages of data. The rowset is a much more realistic approach to delivering meaningful information to the user. This is where the learning curve kicks in. The most important hurdle you'll face in moving to the Visual dBASE OODML is deciding which subsets of data to work with - balancing performance against flexibility. To help you in that effort, Borland kindly added a series of methods that allow you to limit your dataset after the rowset is already defined and the data retrieved from the table. Methods like setRange() and applyFilter along with properties like Filter allow you to further tailor your initial dataset to match a condition or a value.
Tip The only way you'll learn to optimize your rowsets is trial and error. Native dBASE tables will often do better if you select all records and then refine your selection with the Rowset methods. Remote server engines are performance-optimized toward engine-level "filtering" - in the initial "sql" statement that selects the working rowset. It depends on how many records there are in your table and what you intend to do with them. Reports, which don't require instant scrolling from the first to the millionth row, are perfect candidates under all engines for SQL selection. A grid with a speedsearch, on the other hand, may be significantly faster using the rowset methods. Another major consideration is network bandwidth. SQL doesn't require that you work with all the columns in a table any more than it requires that you work with all the records. Therefore, the data for a five-column report will be fed significantly faster over the network if you select just the five columns you need instead of asking for all 254 columns in the table.
Note: Even though you get to define your working data set, dBASE still buffers tables the way it always did. If, for example, you define your rowset with 'Select * from 'Customer.dbf"', you've told the BDE to give you all of the records and fields from your customer table. Assuming you've got 200,000 customers, that's simply too much information to read into memory at one time. Therefore, dBase buffers your data, feeding information to your customer rowset in "chunks". As a result, an unqualified 'select * from "Customer.dbf"' statement run against a .dbf table has exactly the same effect that 'USE Customer' had in Xbase DML. It opens the table and dBASE buffers the rows just like it used to buffer records in earlier versions.
Most remote RDMBS engines will do the same, only their buffers are called "pages" and can often be user-defined. The bottom line is that the internal buffering is not of much concern to you except for wringing final performance improvements from remote data engines. You should be thinking about rowsets as your personal, "working chunks" of data and program accordingly.
Recno() When the record gave way to the row, dBASE lost the eminently useful "recno()". There are no meaningful row-numbers in Visual dBASE 7. For good reason. The entire concept of "record numbers" exists only in dBASE and is imposed by the software, not the architecture. Even in a .dbf disk file, records are neither numbered nor absolute. They are offsets of a specific length from a specific starting point in the file. Record numbers are a fiction of dBASE. Today's most powerful data engines use primary keys to tag individual rows. A primary key uses meaningful data (phone number, customer code) or just a programmer-controlled sequence number to ensure a unique "handle" for each row with which to identify and retrieve it. Bookmark() still works, but only within the rowset. If you requery (resulting in a new cursor, or rowset), the bookmark is lost. It's time to think seriously about Primary Keys. Ultimately, it's not that big a deal, since virtually all dBASE programmers have been indexing on unique key fields in almost every table in every application. The Visual dBASE 7 rowset class just formalizes the process while gaining compatibility with every other major database engine used today.
There's one subtlety to the rowset class that you might want to spend a few minutes considering. The SQL Select statement in the rowset's parent query defines the subset of data with which you'll be working from among all the records in the table. The rowset's methods, on the other hand, work only on that resulting dataset, not on the table. If for example, you use the following SQL statement to define your rowset:
Select * from "Customer" where Firstname = 'Alan'
you'll get a data set that includes only "Alan" rows. Now, if you invoke the setRange method:
r.setRange('Katz')
or a similar filter command, it'll be executed only against the already-selected "Alan" rows, not the entire set of records in the table. It's important that you distinguish between the SQL statement that represents the "query" and the rowset methods that work locally only on the results of the SQL query.
Tip: There is one hard and fast rule you can follow in optimizing the performance of your applications: don't use both SQL and rowset methods on the same query if you can avoid it. ( Do what I say, not what I do - for purposes of demonstration, I broke my own rule in the preceding example.) In other words, if you're going to use the rowset methods to define your working subset, don't use "Where" in your query's SQL statement. If you do, you'll be doing the same job twice - once when the query goes out to get your data and a second time when you use applyFilter, Filter or canGetRow. This is the worst of all possible worlds. If you're going to use rowset.filter, rowset.applyFilter or even rowset.setRange, use "Select * from "customer"' without qualifications or field lists.
Navigation The navigation syntax of the old Xbase DML has been replaced with the methods of the Rowset class in OODML. Where you once issued commands like GoTop and skip, you'll now issue method calls:
form.query1.rowset.first() // GO TOP
form.query1.rowset.next() // SKIPIf you're an experienced dBASE programmer, you may find this a bit awkward at first. Rest assured that the Visual dBASE 7 OODML supports equivalent methods to all the old navigation commands - and then some! Certain methods will seem familiar, such as goTo(), beginAppend(), bookMark(), flush() and unlock(), count(). Others perform the same operations on rows that their Xbase equivalents performed on records: First() replaces "GO TOP", last() is GO BOTTOM; Seek() is now findKey(); findKeyNearest() is a Seek() with "near" set on and setRange() replaces SET KEY TO.
The Filter Property Filters have been both changed and enhanced in Visual dBASE 7. There are now two different approaches to filtering rowsets: the filter property and Filter Mode. The former echoes the old Xbase SET FILTER command by constraining the rowset according to a filter condition set in the rowset's filter property:
form.query1.rowset.filter = "Custno = 'Katz'"
Like the Query's sql property, the filter property takes a string that must evaluate to a valid SQL expression. Unlike the Query's sql property, the filter is executed immediately upon any change to the filter property, or upon activation of the query, which results in a new rowset. This combination of "triggers" for a filter condition offers a surprising level of control:
Constructor You can set the rowset's filter string the constructor of your form. This is the case if you use the Form Designer and the Inspector to define your filter conditions. Visual dBASE 7 generates code similar to the following:
with (this.ITIN1.rowset)
filter = '"' + "Custno" + '"' + " = 'SmithCo'"
endwithQuery Activation If the filter property of a rowset is set before the query is activated, the constraints will be enforced when the query's "active" property is set true:
with (form.query1)
active = false
// Set filter condition - note the use of square
// brackets to simplify the expression
filter = ["custno"='Smithco']
active = true
endwithProgrammatically Any change in the filter property of an active query's rowset causes the new filter to be evaluated and executed:
function saveButton_OnClick
// set filter
form.query1.rowset.filter = ;
["custno" = ]+"'"+form.custnoField.value+"'"
return nullThe Filter property of the rowset takes a SQL string, not a dBASE expression, which imposes some limitations on the rowset filter. SQL has no idea what a Visual dBASE UDF (user-defined function) is, nor will it scope methods of your form or data objects. Therefore, if you have more complex filter requirements than can be met using SQL expressions, use canGetRow to "manually" filter your rowset. (See the section that follows this one for more information on canGetRow.)
Tip: It can't hurt, at this particular juncture, to remind you that the Filter property of the rowset works on the rowset, not on the table. The filter will constrain your working dataset to reflect the conditions you impose; It will not requery the table for new records to match your filter criteria.
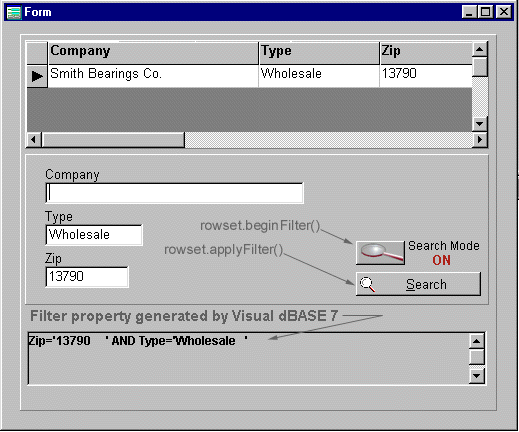
Filter Mode. Filter mode is a wonderful new form-based functionality that lets your users activate filters automatically. It uses datalinked controls to set the conditions of the filter and a group of rowset methods: beginFilter, applyFilter and clearFilter to define, enforce and cancel the filter.
Filter mode is exactly what its name implies - a mode, a state in which you "turn on" filtering for your user. Once beginFilter() is called, any datalinked editing control on your form becomes a potential end-user-defined filter. Let's look at the process:
Assume that you have a form with an entryfield datalinked to the Custno field of your customers table:
- Turn on Filter mode for the datalinked rowset:
form.query1.rowset.beginFilter()
- The user types "SmithCo" into the Custno-datalinked Entryfield
- The user clicks on a "Search" button underneath which lies the following code:
if not empty(form.custnoField.value)
form.query1.rowset.applyFilter()
endif
- Visual dBASE 7 automatically builds and executes the following rowset filter:
form.sql.filter=["Custno"="SmithCo"]
If the user typed data into more than one of the editing controls datalinked to the rowset, Visual dBASE automatically generates and executes a filter for all of them (click on Fig. Thumb1 below for a larger view of a Filter mode form.)
Fig. Thumb1 A Filter Mode Form
In real life, you'll probably use Filter mode for end-user search forms. One good way of employing Filter mode is to open a modal lookup form with beginFilter() in its onOpen event. Be careful, when you design your form, to include only those datalinked fields on which you want the user to be able to search. ApplyFilter() looks at all the fields that are datalinked to the rowset at the time of beginFilter() and builds the SQL string based on all values that have changed.
Tip: Filter mode gives you an extremely flexible seeker-style functionality with almost no cost. There's no SQL filter strings to write - dBASE generates them automatically. However, keep in mind that this is not an indexed search, so it doesn't give you instantaneous movement from the top to the bottom of the rowset. It's a filter, and should be used for obtaining groups of rows. Expect to wait a few seconds for a response on all but the smallest rowsets.
Note: The Rowset class a method (applyLocate()) which is similar to beginFilter, but locates only the first row that matches the user-input filter criteria instead of the entire group of matching rows. BeginLocate() and applyLocate() work in exactly the same fashion as beginFilter and applyFilter. However, Locate mode features locateNext(), a method that automatically finds the next matching row. Use applyLocate() to find the first instance; use locateNext() to "skip" through the rest of the rows.
The Xbase DML used a number of environment settings - in particular, SET EXACT - to determine the behavior of SET FILTER or LOCATE FOR. The Visual dBASE 7 Rowset class replaces environment settings with its much-more-encapsulated and accessible filterOptions property. The available options are:
0 Match length and case
1 Match partial length
2 Ignore case
3 Match partial length and ignore caseFilterOptions applies equally to Filter mode or Locate mode.
Note: One of the major, unheralded benefits of the Visual dBASE 7 OODML is that it resolves ambiguous issues like SET EXACT. Is it case? Is it length? What about case but not length? What about length but not case?. Explicitness is devoutly to be desired and OODML provides it in spades.
CanGetRow The canGetRow event provides yet another approach to filtering your rowset. Get events are new in Visual dBASE 7. They fire when requests are issued, before any event actually takes place. In the case of canGetRow, the request is to "read a row". A request can come from a programmatic call to a rowset method, from datalinked navigation or from a grid, combobox or listbox refreshing its rows.
"Can" events always fire before their namesake event and let you permit the action (by returning "true") or deny it ( by returning "false" ).
As a "Get" event, canGetRow fires when a request comes in to read the row - but before it's passed on to datalinked controls or calling function. As a "Can" event, canGetRow passes the row to its calling object or function only if the event handler returns true. Otherwise, it hides the row. You can use this extremely powerful new event (powerful because it gives you access to the formerly hidden "read" process) to roll your own filter:
////// function canGetRow ///////////////////////////
////// Purpose: filters out records of those who
////// have no balance due and those who
////// are not members of any special
////// organization entitled to discounts.function rowset_canGetRow
// Show row if the amount in this row is greater than 0 and
// the person in this row isMember()
return( iif( this.fields["amount"].value > 0 and ;
this.parent.isMember(this.fields["CustNo"].value), true, false)////// function canGetRow /////////////////////////
////// Purpose: custom method of the
////// transaction query object that determines
////// if a "name" is a memberfunction query_isMembert(cCustno)
// lookup up in the "organizations" query
// to see if this member is there.
return iif( this.parent.organizations1.findkey(cCustno), true, false)Tip: CanGetRow is functionally identical to SET FILTER, with one exception: SET FILTER is executed by the BDE, which uses SpeedFiltering technology to optimize the process. Unfortunately, you don't have access to that optimization technology, so your performance with canGetRow will not be as fast. Not so good. You may, however, be able to accomplish a certain degree of optmization yourself, depending on your data model. The key is to ensure that the dataset encountered by your filter is as small as possible and that it includes the fewest possible non-matches. Which probably means we're gonna break my rule, once again, and use the Query's SQL Select string in combination with Rowset methods to wring the best performance out of canGetRow.
CanGetRow's unique value lies in the fact that it's the only criteria-based filtering method that uses dBASE syntax instead of SQL. So, if you need to constrain your data using a UDF or a method, by all means use canGetRow(). Just don't expect instantaneous results.
NotifyControls Aside from its filtering and navigation capabilties (roughly equivalent to the old dBASE DML), the Rowset class surfaces a number of new methods and properties that dramatically expand and enhance the control the developer has over his or her data.
Never before has the dBASE developer been able to selectively freeze or refresh the controls on a form. Yes, we've had "form.RefreshAlways" since Visual dBASE 5.5, but that particular method froze all the controls on a form. And they stayed frozen only until the current function or procedure completed its operations, at which time the datalinked controls were automatically refreshed (except the Browse which sometimes refreshed, and sometimes didn't!). NotifyControls is a new property of the Rowset class that lets you specify whether controls datalinked to this Rowset get updated as you move through rows, add rows, delete rows or change the data in a row. This property lets you hide operations that go on "under the hood" from the sight of the user. Set notifyControls to false, and the user won't see even a flicker in a Grid when you go searching for duplicate entries.
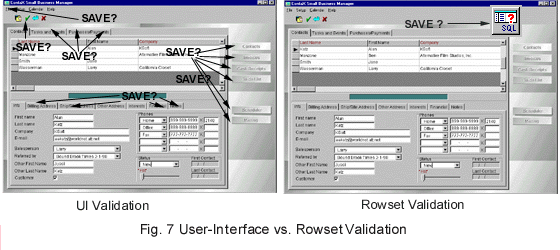
"Can" and "On" Events. The act of appending, saving, deleting and abandoning has become much more accessible. A whole set of new events that fire before and after each of these operations supports validation at the data level - not the user-interface level. Why is this important? Because moving your validation code to the Rowset ensures that your rules are applied everywhere in your application (See fig.7). In the past, we've had to code individual methods (or calls to a shared methods) for: savebutton_OnClick events, onSelChange events (page changes), canClose events (user clicks the big black X) and sometimes even when creating another document ("Document is open... save document?"). For the first time, the Visual dBASE programmer doesn't have to waste precious time (usually in beta-testing, in front of the customer) determining all the possible events that might potentially allow the user to save without validating, delete without intending or abandon a key entry. All this code moves up to one single location, a rowset event, where it's triggered every time a data event takes place. Truly elegant, truly time-saving.
Edit Events. Yet another layer of control. In previous versions of Visual dBASE, you could prevent editing of datalinked components only in the user-interface using the "enabled" property of the component class. This led to major coding in each form or a library of custom controls to manage edits. In Visual dBASE 7, you can control the entire process with the canEdit and onEdit events of the Rowset class. The onEdit event fires the minute the user "touches" any editing control datalinked to the rowset. Major improvement! Now you can turn "save", "abandon" and "delete" buttons on automatically after the user has attempted to change anything linked to the rowset. Up till now, the only way to accomplish this was to build a key event into every data-entry control on your form! By the way, the Visual dBASE 7 Rowset class sports a new method that should be dear to every dBASE programmer's heart: beginEdit(). Using BeginEdit() you can turn datalinked forms "on" or "off" for editing. Your forms can now be completely protected from accidental edits. Add an "edit" button to your toolbar and your data is safe until such time as the user really wants to change it.
Modified Replacing the earlier Visual dBASE 5.x "form.IsRecordChanged()", the modified property of the Rowset is set to true when the row buffer no longer matches the original row - meaning that something has changed, either programmatically or by a datalinked control. "Modified" lets you manage a graceful exit from a data-entry screen on which data has been altered or added (Save, Abandon, Delete?). Unlike "IsRecordChanged()", you can programmatically set the value, ensuring or cancelling the next automatic row save.
One last comment on rowsets before we move along to the next data class. The Rowset class is one of those new Visual dBASE 7 classes that doesn't exist on its own. It's created by its parent query and is addressable only through its parent query. There is, however, one exception: the StoredProc class. The StoredProc class calls a procedure that's created and stored on a remote server. Usually, the return value of the procedure is a boolean (logical), character or numeric value. Sometimes, however, a server can return an entire rowset (a stored procedure can be a SQL Select statement). In that case, you can use a StoredProc object to reference the resulting rowset exactly as you would a query object. For example, just as you can call:form.query1.rowset.first()
you can also call:
form.storedproc1.rowset.first().
Be careful to make sure that your stored procedure is really designed to return a rowset (or you'll get the ubiquitous "undefined" error) and that your server supports returning a rowset from a stored procedure.
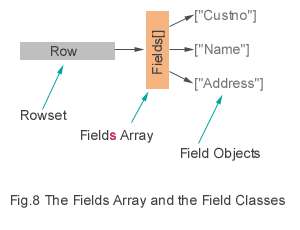
The Fields Array And The Field Classes
Learning a new language is hard enough without two objects sharing (almost) the same name. But it makes a certain amount of sense if you know that the Fields array and the Field classes are inextricably linked. Field objects represent the columns of your rowset. The Fields array is an associative array in which are stored the object references of the aforementioned Field objects.
Let's try to simplify this a bit. There is only one Fields array associated with any given rowset. It's generated automatically by Visual dBASE 7 and serves as a built-in container that provides the one-to-many relationship between the current row and its multiple field objects. The Fields array is an object, not a class. It can't be subclassed, doesn't need to be instantiated has only limited properties and methods (className, parent, size, add(), delete()) Being an associative array, each of its element is addressed by its name - which, in this case, is the fieldName property of the Field object whose address is stored within it.
Form.Query1.rowset.fields["Custno"]
In the example above, fields["Custno"] represents a pointer to the "Custno" field object.
The Field classes are something else entirely. Some are created automatically, others by you when you customize your data model. There are four different classes from which Field objects may be created:
- Field class This is the superclass for all other field objects. It is the "vanilla" parent from which more specific classes (see the classes that follow) are inherited. This is the class you'll use when you want to create your own field objects.
- DbfField class. This is a class inherited from the Field class that represents columns derived from fields in dBASE tables. Visual dBASE generates instances of the DbfField class whenever you "Select " from a .dbf table.
- PdxField class This is a class inherited from the Field class that represents columns derived from fields in Paradox tables. Visual dBASE generates instances of the PdxField class whenever you "Select " from a .db table.
- SQLField class This is a class inherited from the Field class that represents columns derived from fields in remote DMBS tables. Visual dBASE generates instances of the SQLField class whenever you "Select " from Interbase, Oracle, MS SQL Server, Informix, Sybase or DB2 tables.
Why all these different field subclasses? Each has a few custom properties particular to the type of table it represents. For instance, SQLField supports Precision and Scale for remote SQL databases. PdxField surfaces lookupTable and lookupType (automatic lookups), which are not supported in either .dbf or SQL databases. DbfField features default and decimalLength properties to set default values in all fields and decimal positions in numeric fields. The DbfField and pdxField classes both support formatting and range properties, the SQLfield does not. The flexibility of these subclasses hits home once you realize that a single rowset may contain dBASE, Paradox, Interbase, Oracle and Access fields (among others) as a result of a heterogenous Join (aSQL Join from different table types). Despite their various origins, each field object has exactly the right properties to manage the type of data it represents. Visual dBASE 7 spawns these instances when the rowset is created, one for each field specified in your "Select" statement. These specialized field classes can't be subclassed or instantiated - only Visual dBASE can do that - with the exception of the generic Field class.
The Field class offer an extraordinary opportunity to the Visual dBASE OOP programmer. Not only can you add new "calculated" fields, you can embed all kinds of processing and formatting code within custom Field classes for unlimited reuse in other rowsets, forms and applications. Creating your own field is relatively easy:
fld = new Field()
fld.fieldName := 'MyNewField'
fld.value := 'Hello World'
form.query1.rowset.fields.add(fld)There you go, a brand new field. And not just a dead calculated field like earlier versions of Visual dBASE. This is a real updatable field that, once datalinked to a control on a form, can be edited by your user.
Of course, in the example above, the value of the field is nonsense. "Hello World" isn't very useful. Not to mention that it doesn't update anything, so the data goes nowhere. Far more useful are "expression" fields that can be used to handily accomodate some of the limitations imposed by the new data classes. A good example is trying to link together two rowsets using MasterRowset and MasterFields (more on this in the following chapter). In Visual dBASE 7, you're not allowed to use an expression to link rowsets, only fields:
x.masterfields := "lastname" ---> OK
x.masterfields := upper(trim(lastname)+firstname) ----->NO!!
However, you can create a field to accomplish this same link with little trouble:
fld = new field() // Instantiate a new field
fld.fieldName = 'fullName' // name it
fld.beforeGetValue = ; // automatically create a "value" for this new field
{||trim(this.parent["lastname"].value)+" "+this.parent["firstname"].value}
form.rowset.fields.add(fld) // add it to the "fields array"form.query2.rowset.masterRowset = form.rowset // link the rowsets and
// Use your new field as the "linking" masterField
form.query2.rowset.masterFields = "fullName"Don't worrry about the syntax, we'll get to that in a moment. The point of this code fragment is to demonstrate how easily you can change the expression "trim(lastname)+firstname" into a real, functional, readable, updateable field that can be used in any number of ways - including datalinks to form controls and setting up "relations" between rowsets.
The power of this "calculated field" comes from two methods of the Field class: beforeGetValue and canChange. If you check out the online help sections on DbfField, PdxField and SQLField, you'll read that these classes don't have any events or methods. True enough, but since they're subclassed from the Field class, they inherit all the events and methods of this most powerful data class. These two events allow you to stand between the user-interface and the database, in complete control of what the user sees and what gets saved to the table. This is one of the new Visual dBASE 7 layers that sits between two other layers (row buffer and datalinks). And it's one you should pay serious attention to, as it affords a dramatic new opportunity to control your data.
BeforeGetValue is an event that fires whenever you request the value of a Field object. (See canGetRow above for an explanation of "Get" events). The value of a Field object can be requested programatically (x = form.query1.rowset.fields["field"].value), or by a datalinked control ( it obtains its value, by "requesting" it from the datalinked Field object). Since it fires before the control is notified, you can use beforeGetValue to change the data the user sees before it gets to the datalinked control. BeforeGetValue returns the value that gets sent back to the requesting code or object:
form.query1.rowset.fields["fullname"].beforegetvalue = ;
class::fullname_beforeGetValuefunction fullname_beforeGetValue
return iif(this.value = = 'Hello World','Goodbye World','Hello World')In the preceding example, when the datalinked control is refreshed, its value toggles between "Hello World" and "Goodbye World". Like all other events in Visual dBASE classes, you can use either a function pointer or a codeblock. Here's the same example in a codeblock:
form.query1.rowset.fields["fullname"].beforeGetValue = ;
{||iif(this.value = "Hello World","Goodbye World","Hello World"}BeforeGetValue is only half of the "custom field" equation. The other half is getting the value typed by the user back into a table field! This requires the second major Field class event: canChange. CanChange fires whenever an attempt is made, either programmatically or from a user-updated editing control, to change the value in a Field object. You either allow the new value to pass through (return true) or you prevent it from passing through (return false). If you accept it, the Field object's value becomes the new value. If you don't, it remains whatever it was previously.
Tip: To pass through or not to pass through is the question:
If you're using the canChange event to validate what the user typed in, you return either true or false, depending on the results you get from your validation code.
If you need to reformat the data, or use the data to lookup something else and save the lookup value to the field, definitely don't return true or the typed-in value will be saved.
If you're using a custom calculated field to update a different field, accepting the new value or not isn't really very important. In the code snippet below, we're going to save this calculated value in the field of an entirely different rowset. In other words, we're going to use a value defaulted into a datalinked field, then changed by the user to update a wholly unrelated "lookup" table:
// automatically create a "value" for this new field
fld.beforeGetValue = ;
{||trim(form.rowset.fields["lastname"])+form.rowset.fields["firstname"].value}
// assign an event-handler:
fld.canChange= class::fullname_canChange// Event handler method
function fullname_canChange(newvalue)
// update form.query2-> keyname field:
this.parent.parent.parent.parent.query2.rowset.fields['keyname'].value =;
newvalue
return trueAgain, ignore any syntax you don't understand. It'll be covered in detail in the following chapter.
I hate to admit it, but as long as I've been using Visual dBASE 7, I haven't even begun to plumb the depths of the possibilities of beforeGetValue and canChange. We've never had this kind of access to the "get" process before. The creative possibilities are endless.
One of those creative possibilities is morphing. Morphing means that you change the format of the data the user sees from the format of the data stored in the table and then restore before saving back to the field. A perfect example is date conversion. Assume that you have a date kept in DTOS() format to support an index key. However, you're definitely not going to ask the user to type a date in backwards! You can customize an existing field object to support both formats in just a few minutes.
// this method converts from 1990501 to date: 05/01/1999
function datefield_beforeGetValue
return ctod(substr(this.value,5,2)+'/'+substr(this.value,7,2) +;
'/' + substr(this.value,1,4))// this method converts date:05/01/1999 back to 19990501
function datefield_canChange( newvalue)
// Update the field using "index" format:
this.value = dtos(newvalue)
// don't update field with "newvalue", we've already
// updated it ourselves in the previous line!
return falseIn the example above, the Field object automatically converts the DTOS() date stored in the field into a normal, user-friendly MM/DD/YYYY format before sending it to the datalinked entryfield. When the user changes the date in the datalinked control, the Field object automatically converts it back to DTOS() format. Morphing accomplished!
Now here's the really good part. Let's turn this date "morphing" Field object into a reusable custom class for our OOP library:
Class dateField of Field custom // class declaration
with (this)
beforeGetValue = class::dateField_beforeGetValue
canChange = class::dateField_canChange
endwithfunction dateField_beforeGetValue
return ctod(substr(this.value,5,2)+'/'+substr(this.value,7,2) + ;
'/' + substr(this.value,1,4))function dateField_canChange( newvalue)
this.value = dtos(newvalue)
return false // don't update field with "newvalue"endClass
That's all there is to it. From now on, automatic date conversion that's totally transparent to the user requires only four lines of code (only three if you pre-load your custom classes in your application's startup file):
set procedure to dateField.cc additive
fld = new dateField()
fld.fieldName = 'Birthdate'
form.rowset.fields.add(fld)Ok, we've created a new custom Field class with special functionality. But how do we link it back to the rowset - and from there all the way back to the original field in the table? Easy, just make sure when you add() the new dateField object that its fieldName property matches the name of the original field in the table. (It goes without saying that the original field must have been "Selected" in the Query or it won't be in the rowset and can't be "matched"). Piece of cake. And elegant, to boot. If we assume that there was a real field named "Birthdate" in the original table, all we've done in the code snippet above is override Borland's default field object with our own. When the row is saved(), the value of our custom "Birthdate" field goes right back to the table.
Tip: This is probably a good place to stress the importance of knowing which layer you're in when you're morphing data using the Field classes. You're in the row buffer. None of the changes you do in a Field object write directly through to the table. That's still controlled by row pointer movement or the Rowset's save() and abandon() methods. Which means that any change you make in a Field object will be abandoned if the row buffer is abandoned and saved if the row buffer is saved.
Still One More Tip: The Visual dBASE 7 on-line help stresses this point, but I think it bears repeating: the value of a field object is stored in its value property, not in the Fields array! If you code something along the following lines:
form.query1.rowset.fields["Birthdate"] = date()
youll get the ubiquitous "undefined variable" error. You need to address the value property, not the object:
form.query1.rowset.fields["Birthdate"].value = date()
There's two more properties of the Field classes that will probably be unfamiliar to dBASE programmers but which provide serious new functionality. LookupSQL and LookupRowset provide a form of automatic "morphing". Oftentimes, particularly when using a combobox, you want to look up on one field (datasource), but store the value of an entirely different field to the datalinked control. A good example is a customer combobox. You want to show the customer's name to the user for a more user-friendly search, but you want to store the customer number to the field in the table. No problem. Use your Field object. Just assign a SQL Select string for the lookup table to the lookupSQL property. Whenever the row changes, Visual dBASE automatically creates the lookup rowset according to your "Select" string and stores a reference to that rowset in the Field object's LookupRowset property. We'll show you examples on how to implement lookupSQL in the next chapter.
Just a caution before we move along. In addition to the beforeGetValue and canChange events of the Field class, you'll also find onGotValue and onChange events that can be equally valuable for updating other fields in the same rowset or fields in an entirely separate rowset. Always remember that these Field-level changes are not yet committed to the table. So, before you go changing the quantity field in the inventory rowset, make sure that you save() the invoice items rows first! Or even better, limit cross-field changes triggered by Field object events to fields in the same rowset. Use Rowset events (like rowset.onSave()) if you need to update other rowsets in other Queries.
DataModule and DataModRef Classes
If you remember, at the beginning of this chapter we listed the five main data classes in the Visual dBASE 7 OODML. That wasn't quite accurate. There are more than five. But the five we've already discussed constitute the core of form-based and program-based data manipulation. The other classes provide data management services, access to stored procedures on remote servers and language-level object functionality. Paramount among them is the DataModule. The DataModule has only two properties and not a single method or event, but is, nonetheless, one of the most powerful classes in the new Visual dBASE 7 OODML.
The DataModule (along with its companion class, DataModRef) serves as a container for many of the other data classes. As such, it allows you to encapsulate complex multi-query and multi-database collections of data objects, event handlers and methods in a single reusable, inheritable custom class.
Let's assume you're writing an Invoice module. It'll require at least four queries: Customer, Invoice, Items and Inventory. Some of these may populate their rowset from Interbase tables, others from DB/2 tables and still others from dBASE tables - which means you'll need at least two database objects, one each for Interbase and DB/2. The rowsets of your Invoice module will need to be linked in complex one-to-many relationships: at least customers to invoices and invoices to items. Your application may call for a few custom "calculated" field objects to emulate "balance due" and "extended price" fields. You'll defnitely want a whole bunch of validation methods that check for duplicate customer, inventory and invoice numbers, negative quantities, negative prices, non-existent Inventory items and who knows what else. This is going to require a lot of coding, testing and tweaking before you deliver a reliable, automated system for creating, editing and deleting invoices.
So why would you want to reinvent this particular wheel over and over again each time you create a similar document-style form? Why re-code all the queries, custom fields and validation code for Sales Orders, Purchase Orders and Credit Memos when you can inherit from a pre-built, pre-tested class and write only the slight changes needed to support these other documents? Well, of course, as a programmer writing in an object-oriented language, you don't want to. And, because of the DataModule class, you don't have to.
Tip: The DataModule is another strong argument for using data-object validation instead of validating on the form. If your validation code sits in a DataModule, it's infinitely portable - not just to other forms in this application, but to every application you write from this day forward. Strong suggestion: for all but the simplest queries, use DataModules.
Check out the DataModule code that follows. This isn't the complete class, just selected snippets to illustrate some of the possibilities of the DataModule. It's a checkbook class. It gets the rowsets needed for accounts, checks and deposits; links them together and even encapsulates the code that updates account totals when a check or deposit is created, edited or deleted. Whenever I need a checkbook form, I design a user-interface, drop the Checkbook DataModule on the page, link up the editing controls and I'm in business. Each checkbook requires only about fifteen minutes of testing (that's right, fifteen minutes) since the CheckbookDataModule has been fully pre-tested, debugged and certified. The last checkbook form I wrote took about a half day from start to finish.
Once again, don't worry if you don't understand this code, we'll get to syntax in the next chapter.
////// CLASS CheckbookDataModule ///////////////////////////////
////// Purpose: Initializes and manages data for checkbook
////// applications
class CheckbookDataModule of DataModule
// Get Bank Account data
this.ACCOUNTS1 = new QUERY()
this.ACCOUNTS1.parent = this
with (this.ACCOUNTS1)
left = 5
top = 10.5
sql = 'select * from "Accounts.DBF"'
active = true
endwith
// Get Check, Deposit, Interest and Svc Chg data
this.TRANSACTIONS1 = new QUERY()
this.TRANSACTIONS1.parent = this
with (this.TRANSACTIONS1)
left = 16.8571
top = 11.0909
sql = 'select * from "Transactions.dbf"'
active = true
endwith
// Link transactions to their parent accounts
with (this.TRANSACTIONS1.rowset)
onSave = class::Transactions_OnSave
onEdit = class::Transactions_OnEdit
indexName = "ACCOUNTDATE"
masterRowset = parent.parent.accounts1.rowset
masterFields = "Key"
endwith
// dBASE creates default rowset for easier syntax
this.rowset = this.accounts1.rowset
////// Method: Amount_BeforeGetValue //////////////////////////////////////
////// Purpose: Stores "before change" value for edit recalc ///////////
function Transactions_OnEdit
// Store value before changes are made for calculating
// edit changes later
this.oldValue = this.fields['amount'].value
return true
////// Method: Transactions_OnSave ////////////////////////////////////////////////
////// Purpose: Updates AccountTotals after amount change //////////////
function Transactions_OnSave
// determine amount of change in transaction value
nDelta = this.fields['amount'].value-this.oldValue
// Create reference for "Accounts" query rowset for
// easier syntax
accounts = this.parent.parent.Accounts1
try
// Update matching total field to transaction type
accounts.rowset.fields[cType].value += nDelta
catch (Exception e)
// Whoops, no field to match cType?
msgbox('Error updating '+cType+chr(13)+e.message,'No Such Field',16)
return false
endtry
// Update Account Balance
class::UpdateCurrentBalance(accounts)
// reset "old value" to new value for next transaction
this.oldValue = this.fields['Amount'].value
return true
////// Method: UpdateCurrent Balance //////////////////////////////////
////// Purpose: Updates account totals //////////////////////////////////
function UpdateCurrentBalance(accounts)
with ( accounts.rowset )
// Add up "positives", subtract "negatives" to get account balance
fields["Current Bal"].value: =;
(fields["Deposit"].value +;
fields["Credit"].value +;
fields["Interest"].value );
- (fields["Check"].value +;
fields["Debit"].value +;
fields["Service Charge"].value )
endwith
accounts.rowset.save() //OK, updating complete, save the row
return trueendclass // end of checkbookDataModule class
This very simple example of a custom DataModule class gives you (hopefully) just a glimpse of the potential of the OODML to be used to develop reusable "black box" data objects. Other candidates might be: posting engines, mail merge engines (with built-in Carrier Route sort), inventory updates (including LIFO, FIFO and average cost), depreciation, amortization - the list is limited only by your imagination.
Tip: Generic "engines" are not the only important application for custom DataModules. Reuse within an application is another excellent excuse for them. Assume our Invoice example above. Will the Customer, Invoice and Items queries appear just once in your application? Or isn't it much more likely they'll show up again and again in Accounts/Receivable, Sales and Customer management modules? I can't say it often enough: Why reinvent the wheel? If there's any possibility whatever that the queries and rowsets you're working with at the moment will ever be needed on another form (and don't forget reports), they're an excellent candidate for a DataModule. After all, by the time you realize you want to reuse something, it's too late to make it reusable!
DataModules can't be connected directly to a form. For good reason. As an object like all other Visual dBASE 7 objects, the DataModule is encapsulated - hiding and protecting all its queries, rowsets, fields and methods from all the other objects and forms in your application. Its data can't be accessed from outside the DataModule without an explicit connection through its object reference - it's "handle", as it were. That being the case, how can you possibly share the same rowsets between multiple forms? How can you open a modal dialog and have it read or update the rowsets on its parent form? Only one way - by passing its object reference.
The Visual dBASE 7 developers (mindful of the difficulty many dBASE programmers had in referencing data between separate forms in earlier versions of dBASE) added a class that automates that multi-form connection: the DataModRef. The DataModRef is used to attach an instance of a DataModule to its form. Set the "share" property of the DataModRef to "1" (share all), and whenever dBASE encounters a DataModule derived from the same class as the original, it reuses the original instead of creating a new instance of the DataModule.
In short, set DataModRef.share to "1" and all forms using the same DataModule will share the first one instantiated. Set share to "0" (none) and each form will create its own, encapsulated instance of the DataModule. With the DataModRef "shared", all forms read and update the same rowset and all changes are immediately visible to all forms sharing the same DataModule.
You don't have to use a DataModRef in order to instantiate and access a DataModule. Here's an example of a form using a stand-alone DataModule:
Class testform of form
set procedure to checkbook.dmd additive // load file
with (this)
this.d = new checkbookDatatModule() // instantiate
// check out the current account value
onOpen = {;msgbox(;
'Account:'+this.d.accounts1.rowset.fields['Account'].value)}
endwith
endclassBut Visual dBASE 7 can make it highly unpleasant for you if you don't use a DataModRef. Though it's not required, the Form Designer sure gets unhappy if you don't use it. Instantiate a DataModule without a DataModRef, and the next time you bring the form up in design mode it's gone.
Tip: There are only two circumstances in which you can use a DataModule on a form without a DataModRef :
If you accept that you can never again edit the form in the Form Designer, or
If you create your DataModule instance in an OnOpen, Open or another form event -which may not be really helpful as it's probably too late for a clean datalink to the form's editing controls.
On the other hand, you can and should use a stand-alone DataModule when your data is not tied to a form. Going back to our checkbook DataModule example once again, we might want to write your own "rebalance" program that runs as a process with no datalinked controls. In this case, the DataModRef is totally superfluous:
function RebalanceEntireCheckbook
// Create new instance of our checkbook DataModule
set procedure to checkbook.dmd additive
d = new checkbookDataModule()// Set totals back to "0"
with (d.Accounts1.rowset)
fields["Current Bal"].value = 0
fields["Check"].value = 0
fields["Deposit"].value = 0
fields["Interestl"].value = 0
fields["Service Charge"].value = 0
endWith// Loop through all the transactions1 in the detail file
d.Transactions1.rowset.first() // go to top of rowset
do while not d.Transactions1.rowset.endOfSet
d.oldValue = 0 // These are not edits,
// there is no old value
d.Transactions1.rowset.onSave() // run the rowset's
// onSave method which includes a
// call to the method that updates
// the Accounts rowset
d.Transactions.rowset.next() // goto next row
enddoIf you were able to read the code above and can recall the original example, you might have noticed that, while showing you how to use a DataModule without a form, we've also done a neat demonstration of reusability. The method called to do the actual updating as you move through the rowset (Transactions1_onSave) is the event-handler we built into the DataModule to fire whenever the user changed the amount of a check or deposit. No user-input in this routine. In fact, no form. Nonetheless, by carefully crafting our calling syntax, we're able to reuse the exact same pre-tested, proven code in a "background" operation for which it was never intended. All we had to do was clear the "total" values and "skip" through the rows.
Note: It also proves the value of DataModules and OODML in general. To be honest, I never anticipated using this encapsulated "update" code outside of the DataModule - until I wrote this example. But since I created the original in a container, it was there and ready for applications I hadn't even contemplated when I wrote the original. Neat.
The DataModRef acts as a "stand-in" for the DataModule by instantiating it automatically. Just as the Query class creates its rowset object when its "active" property is turned on, the DataModRef automatically instantiates the DataModule class when its "active" property is turned on. You need to set two properties of the DataModRef to tell it:
- What file is it in? (Filename), and
- What class do you want to use ? (DataModClass) This property is required because you may have more than one DataModule class in a single .dmd file.
When the DataModRef is activated, it stores the object reference of the DataModule object it creates in its ref property. Which leads to the rather strange-looking syntax of the expression in figure 10.
It is, fortunately, simpler than it looks. We've created a "proxy" object to represent the DataModule (datamodref1). That object, in turn, has a "ref" property in which is stored an object reference to the DataModule it represents.The rest of the line is the same syntax you'd have with or without a DataModule. It takes a little getting used to, but it does make a certain kind of sense.
The DataModule is the key that unlocks the reusability and productivity advatanges of OODML. We'll have a great deal more to say about it and its "stand in", the DataModRef, in subsequent chapters.
The StoredProc Class
We've already discussed the StoredProc class in the earlier section on Queries. We jumped the gun because these two classes have a great deal in common - and a great deal that's not.
The primary purpose of the StoredProc object is to call a method that sits on a remote server. Those of you who have never programmed against a remote SQL engine may not be aware that all the popular Client/Server databases feature some level of support for executable code that's used for validation, updating or calculation. The purpose behind storing and running code on the server is to get the most data-critical operations as far away from the user-interface as possible. That way, all applications, regardless of the language in which they're written, can call the exact same procedures to run against the database. Stored Procedures and Triggers (procedures called automatically on the server in response to a data "event") ensure that rules are always enforced against the data - not just when programmers remember to enforce them. It also elminates one of the most annoying and dangerous risks to your carefully-crafted data stores: the end-user with a copy of Access or Approach or some other end-user database who decides to tap in (and corrupt) your tables. Every time your data is saved, validation is run, related fields are updated, all executed on the server without regard to the application used to access the data.
This is one flavor of "multi-tier" Client/Server called Two-Tier Client/Server. The calling application is one tier and the procedures stored on the server are a second-tier. The server-based code usually consists of the business rules - which fields update which other fields under what circumstances, what ranges are allowed or disallowed, what conditions must be me before data is saved. Our checkbook DataModule is a good example of business rules. If a check is entered, a certain total must be updated in the Accounts rowset. Other totals must be calculated based on the updated total. Imagine the chaos (not to mention the wrong balances) if another programmer or user were to add or delete a check or deposit without updating the Accounts fields! Triggers and Stored Procedures ensure that this never happens, since the data will not be saved unless it meets all the criteria and all the specified operations and updates have been performed.
Tip: Most popular today is the "three tier" Client/Server module. The business rules are stored in application code, but not with the application. Our checkbook (once again) is an excellent model for three-tier Client/Server. Your end-user application (tier 1), which sports only data-entry and navigation objects, calls the Checkbook module (tier 2), which resides on the Application Server, which, in turn, writes its data to the database(tier 3), which sits on the File Server. Hence "three tier". Admittedly, this model is less sure and reliable than the two-tier model, but it puts a lot lighter load on the server. Trade-off: performance for risk. Of course, the risk is still an awful lot less than letting every developer and user hack around in your tables!
Just a point to note: the "three-tier" model is rapidly giving way to distributed objects, in which many copies of the business rules may reside on many servers in discrete, encapsulated objects in the form of JavaBeans, CORBA or Microsoft DCOM (ActiveX) protocols. The advantage to the distributed model is that, theoretically, any application can be written in any language and run on any platform and still incorporate business-critical rules as though they were hand-coded into each application.
Visual dBASE 7 thoughtfully provides an object-wrapper (functionality that's "wrapped" in an object syntax so that it interacts more comfortably with other objects) for Stored Procedures. Stored Procedures (like dBASE functions) may have parameters passed to them when invoked. To accomodate this, the StoredProc class provides a Params associative array (sound familiar? ). Elements are automatically added to the Params array once the ProcedureName property has been set, but only if dBASE is able to read the procedure on the particular server in use. It's generally pretty good at that. If it can't, you can set up your own parameters in the same line as your ProcedureName:sP = new StoredProc
sP.ProcedureName="SaveTransaction( :amount)"
sP.Params["amount"].value = 100.20
sP.Params["FirstName"].type = 1 // inputYou'll note in the above example that the Params array in the StoredProc class is quite a bit different from the Query's Param class in that it has value and type properties. These two properties mark the essential difference between the two classes: The Query class's Params array is used to substitutes values for "variables" in a SQL Select Statement; the storedProc passes parameters to external functions which may be changed when that function executes. In other words, the elements of the Params array may have to return values, not just set them. To accomplish this, the Params array of the storedProc class hosts Parameter objects in its elements, not values, as the Query's Params array does. The parameter object's "value" stores both the value sent to the procedure and the changed value returned by the procedure (if any). "Type" tells dBASE what's to be expected from the parameter: Input only, Output only (in which case you put in a dummy value to define the "data type") or Input/Output. There's one special case, the Result parameter object. If the storedProc returns a value (like a dBASE function returns a value), it is stored automatically in a parameter object named "result"
? form.datamodref1.ref.storedProc1.params["result"].value --> return value
What makes the StoredProc similar to the Query is that the "result" of a StoredProc can be a rowset - in which case the Active property of the StoredProc stays "true" and you have an imitation Query on your hands whose rowset can do everything the Query's rowset can, including datalinking to form fields.
The UpdateSet ClassThis is an unassuming little class. Used to update rows from other rows and tables from rows and tables from tables, it's not even as capable, in some ways, as the old dBASE "Copy To" command. It can't output SDF or any other delimited text file, it doesn't sport a huge list of options, However, don't let its modest appearance fool you. This is one of the most remarkable language-level data classes around. Why? Because it can copy almost any row or table to almost any other row or table. Meaning that you can start with an Oracle table and end up with an Interbase table. Or start with a dBASE table and end up with an Access table. It's our very own Data Migration Wizard, only better. The Data Migration Wizard can't copy rows - live result sets generated within your application. Furthermore, updateSet runs within your application under your direct programmatic control. The implications of the UpdateSet class for replication, import and export in a multi-database environment just can't be overstated. To those of you working with heterogenous data, the UpdateSet class will prove indispensible.
// Instantiate a new updateSet object.
Upd1 = new UpdateSet()
// Point to the source, in this case a rowset
Upd1.source = form.datamodref1.ref.accounts1.rowset
// Point to a destinateion table, in this case a table
// in an Interbase database:
Upd1.destination = ":Company:Accounts"
// Go ahead and copy
Upd1.copy()Though the code is really quite simple, the conversions this class performs is not. In order to ensure that you don't lose any data in the translation from rows to tables or one data format to another, updateSet will keep error logs if you provide a filename to the updateSet's keyViolationTableName or problemTableName properties.
Take a few minutes, at your leisure, to check out the Visual dBASE 7 online help for a more detailed view of the different copy options available.
SummaryThe Visual dBASE 7 OODML is a lot to swallow at one meal. Not only are you confronted with new syntax, classes and methods, you're once again in the grips of a paradigm shift - a whole new way of thinking about accessing and managing data. (Sorry to use such a trite expression as "paradigm shift", but it really fits here!). The flip side is that the talented developers of Visual dBASE 7 have handed you, on a silver platter, power and control the likes of which you've never dreamt. Every day I find new applications for the data-access class methods. Rowset and Field object validation has cut my most onerous coding by more than three quarters. DataModules are rapidly expanding my OOP library and increasing my productivity logarithmically. Let me close this chapter with a short list of my personal favorite "new things you can do with data classes that you couldn't do before in Xbase DML". I don't know if the items on the list will convince you, but I admit that they most assuredly did me.
- No more workareas, Set Database or Create Session. No more ambiguous data management.
- No more housekeeping (close data, etc.) The objects manage the data they represent.
- Encapsulated Data.
- Sharing data among forms is much easier.
- Almost complete control over if, and under what conditions, data gets written to disk.
- Flush is now granular, right down to the rowset level.
- Programmatic control over login.
- Rowset-level events that fire for appends, edits, changes, abandons and deletes.
- Field-level events that fire before datalink and after changes.
- Explicit control over the datalink itself.
- Finally! - the ability to freeze or refresh datalinked controls at will.
- Morphing.
- Filter Mode
- Scalability.
- Business rules move away from the User-Interface.
- Field level custom methods.
- Data-level validation.
- "Live" calculated fields.
- Heterogeneous data access (multiple data engines simultaneously)
and most important of all:- Object data - with all its benefits of reusability and inheritance.
Appendix 1 Xbase and OODML Equivalents List
The following table is a (very) partial list of old Xbase DML commands and their equivalents in the Visual dBASE 7 OODML. Please keep in mind that none of these are SQL commands or propeties and that the navigation equivalents work only on the rowset after the query has been activated. Just to keep the record straight, the row buffer commands (like beginAppend()) are not Xbase DML, they're Visual dBASE form methods. But they've been replaced too, so I took the liberty of including them in this table.
Xbase
OODML
Create Session s1 = new session() Set Database To d1 = new Database()
d1.databaseName := 'Mugs"
d1.active := trueUse q = new query()
q.sql := 'Select * from "customer.dbf"'
q.active : = trueSet Order q.rowset.indexname := "custno" Set Relation qChild.rowset.masterRowset := form.qParent.rowset
qChild.rowset.masterFields := "custno"Set Filter q.rowset.filter := "Custno = 'Katz001'" Set Key To q.rowset.indexName = 'custno'
q.rowset.setRange('Katz001')Go Top q.rowset.first() Go Bottom q.rowset.last() Skip 4 q.rowset.next(4) Skip -4 q.rowset.next(-4) form.beginAppend() q.rowset.beginAppend() form.abandonRecord() q.rowset.abandon() form.saveRecord() q.rowset.save() form.isRecordChanged() q.rowset.modified Close Data Don't need it. Just destroy your data objects. this.endOfChapter