WHAT IS Y2K?
Literally, Y2K means (Y)-Year (2)-Two (K)-Kilo (Thousand). In this discussion Y2K will not be used in its literary sense but will refer to the inability of computers to recognize and process the advent of the new millennium. Y2K is not a virus or a bug. It is the result of a conscious software programming decision. When the century rolls over, many computers won't be able to tell the difference between 1900 and 2000. As a result, calculations will produce errors because 99 plus 1 does not equal 00, and because 00 < 99. This is true for both hardware and software. Though the cause is simple, rectifying is difficult due to the wide range of software languages, applications, and microchips (embedded systems), etc., currently in use today. The problem stems from three main issues: two digit date storage, leap year calculations, and special meanings for dates. The implications of these three issues need to be addressed by all organizations. There is no quick fix to the year 2000 problem as the use of dates in calculations is pervasive throughout software and that usage is not standardized. Dates are used by computers to process and to communicate this data to other computers. If the dates aren't processed correctly, the data becomes corrupted or distorted and the wrong information is processed.
The most common problem occurs when software has been written to store and/or manipulate dates using only two digits for the year. Calculations built upon these dates will not execute properly because they will not see dates in the 21st century as being larger numbers than those in the 20th century.
The two digit date convention assumes that the century is 19. This assumption was regarded as a necessity in the early days of commercial computing because of the high cost of computer storage and memory.
Leap year calculations
Leap years are calculated by a simple set of rules. Unfortunately, there are systems and applications that do not recognize the year 2000 as a leap year. This will cause all dates following February 29, 2000 to be offset incorrectly by one day. The rules for leap year calculations are as follows. A year is a leap year if it is divisible by four, but if it is divisible by 100 it is not a leap year, but if it is divisible by 400 it is a leap year. Thus, the Year 2000 is a special case leap year that happens once every 400 years.
Special meanings for dates
The third main Year 2000 problem is more commonly found in older code bases. In order to write more efficient code that allowed for the use of less memory, date fields were sometimes used to provide special functionality. The most common date used for this was 9/9/99 or 01/01/01. In some applications the use of the special date meant save this data item forever or remove this data item automatically after 30 days, or sort this data item to the top of the report, or this data item has an undefined date. Within each organization, special date codes may have been used differently. This is one of the main reasons that no single tool can locate all uses and/or misuses of date data.
Technically, the problem is simple to understand. The solutions to the problem tend to be fairly simple as well. The scope of the problem, however, makes it difficult. Every piece of hardware, software, and embedded system must be taken into account. Everything from mission critical central accounting systems to small convenience applications must be examined for date handling and how those dates might affect the rest of the environment.
Y2K affects computer calculations and operations that use the date. This could lead to serious errors in data and calculations. This problem affects a vast amount of software, particularly accounting and database systems, as such, dBASE has come under great scrutiny with reference to its handling of the date system and the year 2000 or Y2K. You will be pleased to know that all versions of dBASE has the ability to store its date in the full century form, thus making data entry and date calculations able to function as expected. The problem is, however, not the way dBASE stores date data but how does it interpret data that is already stored explicitly as two digits. As will be discussed later, dBASE has a set century command that sometimes can be used as a really very quick fix. Thus dBASE can convert already data stored as '98' to '1998'. But it's not that simple.
The Year 2000 problem is totally predictable in its timing (00:00 1 January 2000), but completely unpredictable in its effects. Its greatest danger lies in that uncertainty.
There are also other issues revolving around Y2K. One of them being the most frightening, Litigation. The legal implications of the millennium bug are astounding even to lawyers. In legal circles it is accepted that no single event in the history of mankind has ever given (or will give) rise to more potential litigation than Y2K. Not even lawyers are sure which areas of liability will arise but it is clear that Y2K will affect all sectors of commerce and society. It is of paramount importance to identify at least some of the potential risks of liability and to take immediate precautionary measures accordingly. Establishing legal liability serves two functions: Firstly, it will enable you to identify your liability exposure and which steps to take in this regard. Secondly, it will enable you to identify who is responsible for the costs of fixing your systems/equipment and whether you should demand satisfaction from a commercial or litigation perspective.
How can I then know that my programs, computer, or any other related software or hardware will conform to Y2K. Here are four simple rules. They are not standard, just a guideline.
Year 2000 conformity shall mean that neither performance nor functionality is affected by dates prior to, during and after the Year 2000.
Rule
1:
No value for current date will
cause any interruption in operation.
Rule
2:
Date based functionality must
behave consistently for dates prior to, during and after Year 2000.
Rule
3:
In all interfaces and data storage,
the century in any date must be specified either explicitly or by unambiguous
algorithms or inferencing rules.
Rule
4:
Year 2000 must be recognized as
a leap year.
How then does this relate to dBASE in its date storage and date interpretations and date calculations? What about programs that I have written and have not taken the difference of two digit and four digit years into account? Do I have to re-write the whole app? Is there a fix that I can use? Why can't I just use set century on?
This might actually work, but it is not fool proof. There are some circumstances where it will work and some where it won't. That is why there really is no quick fix solution, no program to automatically make it right. A program such as the one that I have written try's to find possible areas of concern and report them, leaving YOU, the user or programmer to make the final decision.
If the application is very simple and was developed by putting together objects designed with the tools supplied with dBASE, and you have simple index expressions, with little or no custom coding, setting century on may work in most cases. Simple data input screens might have to be redesigned if things get too crowded.
Other things to lookout for are (Some of which came from an article written by Alan Dechert about Y2K in a dBASE DOS environment, here in Italics):
I have written a program in dBASE 7.01 that will scan through code and table structure and try and point out any problematic areas. This program was based on an idea I saw on the internet. Alan Dechert wrote a Y2K code scanning application for DOS. See his site for his excellent article and code concerning Y2K and dBASE for DOS. After seeing this, I thought to myself, wow that is easy, why don't I do the same for dBASE 7.x. If you are concerned that this program will in anyway damage your system. DON'T USE IT. The first thing you need to do is make a backup.
The Y2K check program
Why did I choose to use dBASE to write this in? Well primarily because I am a 'dBASE fundamentalist'. We actually have huge amounts of code to check that is written in dBASE, and I was not going to scan through it manually. Seeing that I am a lazy person I had to find an easier way. dBASE was the logical and easier choice. With dBASE's simple yet powerful forms designer; its control inheritance; its simple but yet strong low level file functions; its ease of on the fly table creations and its speed of data manipulation, how could I not choose dBASE.
The easiest thing to do was designing the form, the controls and assigning events to those controls. Also if anything in the form and control needed changed, I just did it and the change bleeds all the way through the app. No scanning through the code and manually changing all the reference to whatever I had changed.
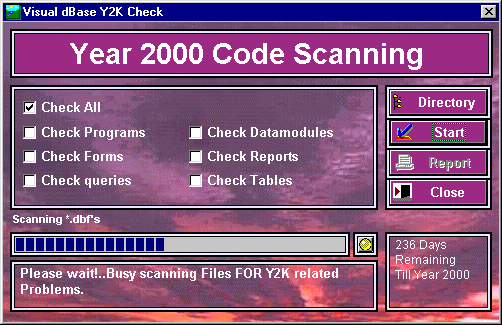
Wow. It was just so simple to start with a new form, modify the background property with the picture of my choice. Here again in VdBASE7 we have the advantage of a number of graphic file types which makes life much simpler. The background here is a jpeg image created in Paint Shop Pro. It is a composite image I created with various images I have floating round my HD. Drop in some pushbuttons, a container and some checkboxes, and a progress bar and we're looking professional, almost like a programmer that's been doing this for years.
The Container is a great object. The great thing about it is I can drop other objects onto the container, and then when I move the container all the objects within it move as well. No more selecting, selecting and selecting. The other great thing is the transparency property. Setting the text fields and the container transparency property to true makes way for a professionally looking well designed and attractive application. Ain't dBASE great and easy?
Adding events was even easier. The only problem I had was with the repainting of the progress bar. I found that windows was not repainting the screen during a long and complex loop. This was fixed by a repaint routine that I got of the dBASE newsgroup from one of the many people that are so willing to help. The repaint routine I put into a custom form, and voilà all my forms are now based on that custom form and inherit that paint routine without me retyping it or redefining it. I called the custom form base form and the Y2K check form is based on that. That got rid of the paint problem. Where else can you do that?
// Custom Form
class BASEFORM ;
of FORM custom
if type("UpdateWindow");
# "FP"
extern cLogical ;
UpdateWindow(;
cHandle;
);
user32
endif
if type("PeekMessage");
# "FP"
extern cLogical ;
PeekMessage(;
CSTRING,;
CHANDLE,;
CLONG,;
CLONG,;
CLONG;
);
User32;
From "PeekMessageA"
endif
#ifndef
PM_NOYIELD
#define PM_NOYIELD 2
#endif
#ifndef
WM_LBUTTONDOWN
#define WM_LBUTTONDOWN 513
#endif
#ifndef
WM_LBUTTONUP
#define WM_LBUTTONUP 514
#endif
Procedure Open
this.init()
return super::open()
Procedure ReadModal
this.init()
return super::readmodal()
Procedure Init
return
Procedure Repaint
if argcount()=1
UpdateWindow(argVector(1))
else
UpdateWindow(form.hwnd)
endif
return
Function CheckMouse(hWND)
local cMsg
cMsg = Space(14) // Buffer
return PeekMessage(cMsg,;
hWND,;
WM_LBUTTONDOWN,;
WM_LBUTTONUP,;
PM_NOYIELD)
endclass
It's as simple as that!
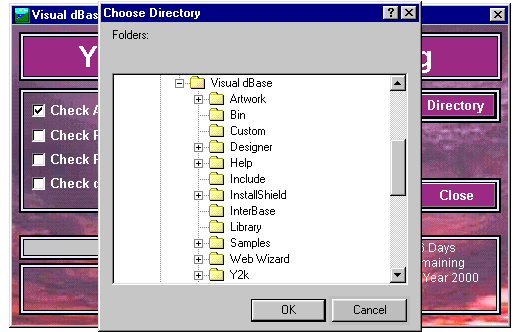
The first thing we need to do when running the form is to choose a directory where all our code and table lies. This is simply done by using the getdirectory() function and returning the desired directory.
Once we've selected the directory where our code and tables lie, we need to select the file types to scan. We can choose to select all of them or we can select any combination we desire. Once we've done that, click the <Start check> pushbutton to check for possible problematic areas.
The scan procedure first checks to see if a specific table it needs exist. If not, it will dynamically create them. This very handy with dBASE as you don't have to ship a whole bunch of tables when you deploy your app; it is possible to have code to create those tables on the fly. This table is based in part on the results table that Alan Dechert used in his Y2K code scanner for dBASE-IV.
FUNCTION createtable
//
CREATE results FILE IF necessary
IF .NOT. FILE("&rootdirectory.\results.dbf")
CREATE "&rootdirectory.\temp0"
STRUCTURE EXTENDED
Append Blank
REPLACE FIELD_Name
with "FILENAME"
REPLACE FIELD_Type
with "C"
REPLACE FIELD_Len
with 12
REPLACE FIELD_IDX
with "N"
......
INDEX ON FILENAME+FUNCTNAME
TAG INDEX1
ELSE
mrootdbf=rootdirectory+"\"
Close DATA
SELE 1
USE "&mrootdbf.results"
exclu in 1
ZAP
ENDIF
RETURN
After a successful table creation
it's time to start the real work. This is where dBASE excels. We now need
a bunch of variables that contain data to check against. E.g. we need to
check if a command like ctod() exists in our program. Now we can do one
of three things:
1) We can store all the commands
that we think necessary to individual memory variable. This is not desired
as it can become a nightmare to remember which ones are which.
2) We can create a table and store
them there as records. This will work great: we can then make the app very
flexible because we can put in the ability for the user to customize what
they would like to scan for. Also, this is very handy because then we can
scan any text-based program.
3) We can also put the commands
into an array, this is handy because its very fast when scanning through
the array as it resides in memory but it is also a little bit ridged in
that if we want to change something we have to do it in code. I have chosen
to use the array method simply for the speed, but I will be using the table
method at another time.
Form.afunction = new ARRAY(45,3)
Form.afunction[1,1] =
"ctod("
Form.afunction[1,2] =
"dBASE function"
Form.afunction[1,3] =
"H"
....
Once we have created our check base we then extract from the directory the files that we have chosen to scan. Scanning the directory into an array does this very simply.
Form.adirprg = new ARRAY()
....
Form.TEXT2.TEXT="Scanning *.wfm's"
Form.nprgfiles = Form.adirprg.Dir("*.wfm")
Form.scanfile()
We now scan through this array and open each file with the low level file function in dBASE. With the file open we can then compare each line with the command that we have chosen and then take the necessary steps depending if our evaluation evaluates as true or false.
Form.lfile = new FILE()
....
Form.lfile.open( Form.adirprg[n,1],
"R" )
The R option opens the file as 'read only': we don't want to write anything undesirable to the file.
IF Upper(Form.afunction[a,1])$upper(Form.mlowline)
Append Blank
REPLACE filename
with Form.adirprg[n,1], functname with Form.mfunction,;
LINE with Ltrim(Form.mlowline), LINE_num with mlineno,;
risk_level with (Form.afunction[a,3])
ENDIF
What this now does is run through each line in the file we have just opened, compare it with the command function in our array that we created and are scanning earlier to see if that command is contained anywhere in that line (that is the contained 'within' function '$'). If it does we then write that line with the line number of the program and the program name and the possible offending command or function to a table. This table will be used to print out a report of possible offending areas.
What this achieves is that we don't have to scan through lines and lines of code that have no bearing on date related programs. We can use the report to go directly to the offending program and directly to the offending line, look at that line and then make an intelligent decision as to how we will fix or not fix something.
Once we have scanned through this file we close it with the 'file.close()' function. We skip trough our directory array, pick up the next file, open it, start scanning our command array and so on and so on until all files are done. Now we will have a table with a listing of all programs and all line that are potentially dangerous for date sensitive date.
It is also a very simple thing to check dBASE tables and production mdx file. All we do is open the table scan through its fields and check to see if it is of a date type. If it is we store the table name and field name in our result table.
FOR nfld = 1 to FldCount(WorkArea())
Form.mlowline=FIELD(nfld,WorkArea())
....
IF Type(Form.mlowline)=="D"
sele results
Append Blank
REPLACE filename with Form.adirprg[n,1], functname with "Date type",;
LINE with Ltrim(Form.mlowline)+", Date FIELD", LINE_num with T,;
risk_level with "H"
First we need to get a count of the number of fields in the table. Then we scan through each field and find out if it is of date type. If it is we store the results.
Indexes are just as simple. dBASE enables us not only to see the data type that the index is based on but also retrieve the actual index expression. Once we retrieve the index expression, we can then compare the index expressions and see if they contain any suspect commands or functions.
cmdx=MDX()
mtagcount=TagCount()
FOR T = 1 to mtagcount
IF cmdx#""
sele 2
Form.mlowline=KEY(MDX(1,Alias("b")),t)
IF Type(KEY(MDX(1,Alias("b")),t))=="D"
......
ENDIF
We first find out how many index tags there are in the production index. We can then scan through the index tags and see if any contain indices that are based on date type data.
IF Upper(Form.afunction[a,1])$upper(Form.mlowline)
We can also store the index expression to a variable and compare that variable with our command and function array to see if the index expression contains suspect functions.
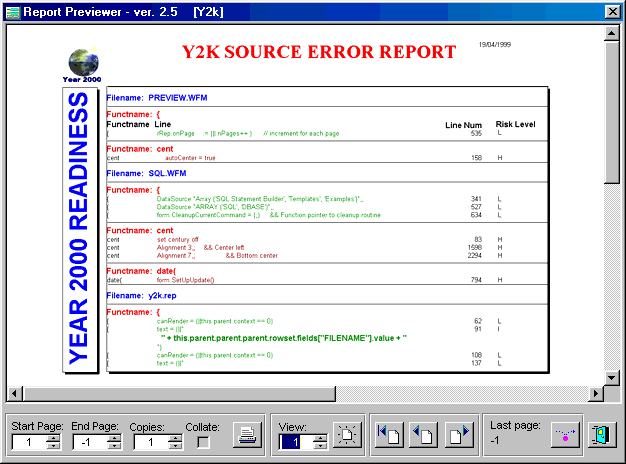
Once we have acquired and formulated all our data, its a simple thing in dBASE to format a report and represent the results in a professional and elegant way. This report is an enhancement on the report created by Alan Dechert for his DOS application.
The great thing about the report writer is that, like most other report writers, it is all visual design; that is, all drag and drop. The difference with the dBASE report writer, like so many of the other dBASE design tools, is that I can customize a report, and all other reports based on that customized report will carry those customizations. E.g. If my reports have to have client specific logos, and specific page and font setting, all you do is create a custom report, and voilà all other reports have the same look and feel. You don't have to redesign the settings, headers and foots, or re-insert the logos, or graphics of the report every time. This leaves you with more time doing what dBASE is meant for, database design and maintenance and not graphic design and publishing.
One of the great things about the report is that it is very tightly integrated with dBASE. In fact it acts almost like a common form in dBASE. One of the things that I have done is colour code the results based on their risk category, green for low risk and red for high risk. Keep in mind that the risk rating is my interpretation; you'd have to evaluate each line of code for yourself.
And that's it. There is so much more that dBASE can do but the Internet does not have enough room for us to explain (I'm only joking, but you get the idea). No matter the small irritations you might find in dBASE, it still beats other tools out there for desktop databased specific application. You wouldn't want to use dBASE for graphic design: similarly, other applications, as good as they might be in some areas, do not meet the requirements of a database specific development tool.
Robert Bravery
To download the Year 2000
code scanning software, click here
(it's a 126Kb zipped
executable file)