A table is an organized collection of data. To make this discussion simple, lets say a table is like an electronic spreadsheet in which each row is a single record and each of the characteristics related to it is written in the appropriate column (called a field). If you are a beginner, before you build your own tables, please read not only the following text but also Mike Tossys Database Design and Normalization article. The latter could save you from a lot of errors in defining your tables.
The true nature of tables
To see a table as a spreadsheet is a nice concept but this is only a concept. All the files on a computer are long strings of binary values inside clusters, sometime consecutive, often spread all over a partition. We tend to see dBASE tables as a series of individual records or as a spreadsheet because thats the way dBASE displays the data in its tables. Actually, these tables are just stings of zeros and ones, just like any other computer file.
The string of data from a dBASE table file has two parts: first, the header (hence its name), followed by the data. For the user, the useful part of a table is the data it contains. Not so for dBASE. The software doesnt understand a word about the data in a table. For dBASE, the useful part of a table (and the only part it understands) is the header. In that header, dBASE finds a lot of information about the table: the number of records, the size of the header (that size changes according to the number of fields), the size of each record, etc.
When you ask dBASE to display the thousandth record, that software take note of the size of the header, multiply by 999 the size of each record, add a byte (if my memory serves) for a separator between records, and jumps N bytes further, and winds up exactly at the thousandth record. Instantly.
This is the basis of dBASEs strength: the fixed length of the records in a given table. If dBASE had to read the long string of binary values in a table in order to find where a record stops and where another one begins, it would have the speed of a word processor looking for a word. That speed is acceptable in a short text. But in an article exceeding a megabyte in length, that search could take a very long time. On the contrary, when you ask dBASE to go to the millionth record, it finds that record instantly because it doesnt have to find it: it knows where it is.
Even when you are looking for some data (e.g., Smiths address) and dont know the record number, dBASE is clever. Without an index, it will jump from record to record, accessing exactly and precisely to the family name in each record, not looking further than the first letter when it is not the right one, until it finds Smiths record. dBASE neither knows what Smith means, nor that "Smith" is a family name. The only thing it knows is that the header is telling it where it could find the right information; if not, to jump N bytes further, and so forth.
This is one of the reasons why dBASE is an outstanding piece of technology.
The level and language of a table
The BDE
As bizarre at it might seem, no version of dBASE running under Windows can directly access the data in its own tables. They do it through the Borland Database Engine (BDE). The reason for that is part of dBASE history. At the end of the eighties, through acquisitions, Borland International ended up with two database management software packages: dBASE and Paradox. Rather than maintaining their own separate database engines, Borland had the idea of creating a common engine which would be able to be used by all Borland software: that was the BDE. Many years later, when dBASE was acquired by its present owner, the latter found itself with a flagship product that depends upon a foreign technology to do some of its essential tasks.
The table level
This explains why we have to go through the BDE to change the current table level. Unless the table structure is changed, the table level is always kept as it is. The level setting in the BDE just defines which level new tables are getting. That doesnt affect the ability of the BDE to read any kind of dBASE tables. Thanks to the BDE, a dBASE application can obtain data simultaneously from tables having different table levels.
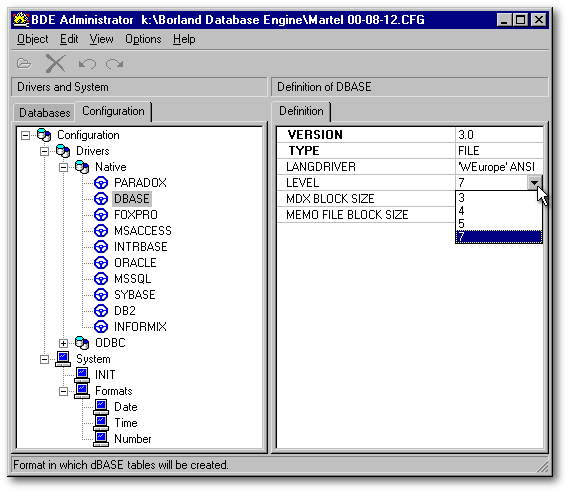
But what is the level of a table? The level means its version. The dBASE table format is a standard that has evolved over time. When a new version of dBASE made some improvements to that format, a new format level number was given, identical to the new dBASE version. For example, we have levels 3, 4, 5 and 7 corresponding to dBASE III, dBASE IV, dBASE 5, and Visual dBASE 7. There is no level 6 because there was no Visual dBASE 6.
Level 7 brought many improvements. The field names can have up to 31 characters (from a maximum of 10 before). Some new fields types have appeared (for example, the AutoIncrement field that makes nearly impossible to give the same number to two records in the same table). If your tables have to be used by other software, you might have to sacrifice these advantages for the sake of compatibility, as few applications can use a level 7 table.
The BDE Administrator is used to set the current dBASE level. Go to the menu item Start|Settings|Control Panel and double-click the BDE Administrator icon.
In the left pane of the BDE Administrator, select the Configuration tab, then open the treeview until you see the dBASE table driver (represented by a steering wheel). In the right pane, click at the right of Level to reveal the down arrow button that gives access to the drop-down list and select the appropriate table level.
The table language driver
Just above Level, you can choose the Language driver (LangDriver): that language driver defines how records will be indexed in a table. More precisely, it decides how accented vowels will be ordered. Personally I am using 'WEurope' ANSI. It indexes the accented vowels in the following order: a A á Á à À â Â å Å ä Ä ã Ã. That Language driver is the one recommended by dBASE, Inc.s technical support.
But Germans have some problems with it since they expect letters carrying diaeresis (umlaut) to be indexed differently from what English people expect. Danes expect words beginning with the letters AA, Aa, aA and aa to appear at the end of the index, after letter Z. It seems that they should use the Language driver called 'Borland DAN Latin-1'. That driver doesnt appear in the list but the BDE Administrator will accept that name if it is typed in the LangDriver entryfield.
Near the bottom of the left pane,
under System|INIT, a Language driver can also be selected. To be
honest, I couldnt find in Borlands documentation what the purpose of
this driver is. I presume that it is better to have the same language driver
in both places. Also in the
System|INIT section, be sure to set
the BDE to create dBASE tables rather than Paradox tables by default (in
the Default driver item). Note: While we are in the System|INIT
section of the BDE, we should note that some experts believe that the default
settings in that section are very conservative for todays machines. For
example, on June 30, 2000, Dan Howard [dBVIPS] revealed the settings
he was using then:
| Setting |
|
|
|
| MaxBufferSize |
|
|
|
| MaxFileHandles |
|
|
|
| MemSize |
|
|
|
| SharedMemSize |
|
|
|
His suggestion is to set MemSize equal to 16 (as the minimum) or to one fourth of the quantity of RAM on your computer.
Once you have set the language driver and the table level, quit the BDE Administrator. If you made some changes, you will encounter two dialog boxes when you exit. In the first one, you will be asked if you want to save your changes. The second will inform you that all applications that depend upon the BDE have to be restarted for these changes to take effect. In fact, these changes will have consequences only when a new table is created or when you change the structure of an existing table.
If you change the Language driver in the BDE Administrator and that affects the way accented vowels are displayed in your code, that means that no Language driver is set in dBASEs .ini file. When this is the case, the BDEs language driver is used by default.
In order to limit the effect of the BDEs Language driver to your tables and avoid the troubles you could get into when a change of the Language driver affects the execution of your code (especially if there are accented vowels in your field names), load vdb.ini or db2k.ini in an editor (e.g., Notepad). In the [CommandSettings] section, add the following line: LDriver=Windows . Since we are not yet at the stage where you will be creating programs, I would suggest to you that you would check now if your .ini file contains that line. If not, please add it. You will avoid yourself a lot of troubles.
Current vs Specific language or level
Once a table is created, it is impossible to change its language driver. This means that if you develop applications aimed at the some international markets, you could create tables with different language drivers for different markets. When these tables are used, their data will be read and written according to their specific language, not according to the current one. On the other hand, if you modify a tables structure, the table level will be changed to the table level currently called for by the BDE.
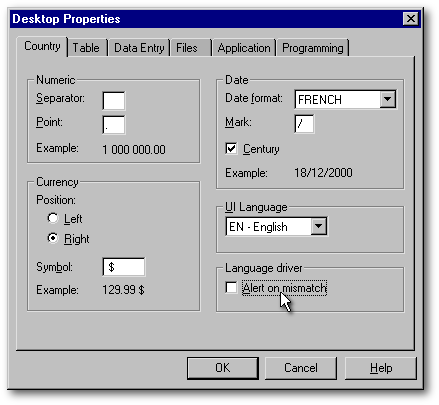
If you want to stop dBASE from reporting an error message each time it opens a table with a language driver different from the current one, go to the menu item Properties|Desktop Properties: under the first tab, Country, be sure to have the Alert on mismatch checkbox unchecked. You could get the same result if you type set LDcheck off from the Command window. (Note: You can also add that line of dBL code to your applications to avoid your clients from getting that error message when they use your applications.)
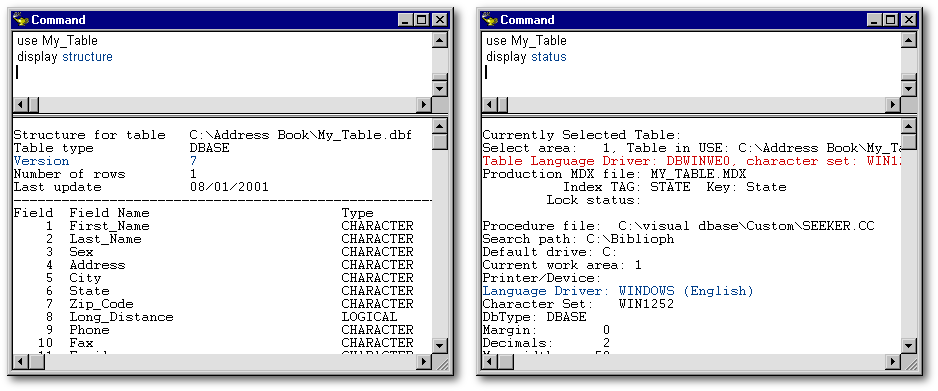
When you want to know what the current Language driver is without having to open the BDE Administrator, push the F6 key. In the Results pane, on the line that starts with Language Driver, you will get the name of the current Language driver. (We set it in blue in the right hand part of the image below.) If you see something like DBWINWEO ('WEurope' ANSI) instead of WINDOWS (L) where L is a language that means there is no LDriver entry in your vdb.ini or db2k.ini and that dBASE is using by default the BDE Language driver. To see the current table level without opening the BDE Administrator, you have to create a new table.
To know what the level of a table is, open it from the Command window with the command use "My_Table" and push the F5 key. Note: Replace "My_Table" with the name of the table. The quotes are needed only if there is a space in the name of the table.
To find out which Language driver is set, push the F6 key. The result is shown hereunder in red, at right, on the line Table Language Driver (which must not be confused with the line Language Driver (the latter is showing dBASE current Language driver). From the Command window, type use (with nothing else) to close the table.
The BDE limits
Up to 512 dBASE tables can be opened at the same time on a computer. Theoretically, a dBASE table can have a billion records. In fact, a table cant be bigger than 2 gigabytes. This size is the real limit of dBASE table. A record can have up to 1024 fields. The field name is limited to 31 characters. A character field can hold up to 254 characters (letters and/or numbers) while a memo field is unlimited.
The index file has the same name its the table except that its suffix is .mdx (Multiple Indexes). As this suffix suggests, each of these files might contain many indexes. The limit is 47 indexes per index file. Even if one can create an unlimited amount of secondary .mdx (under other names), I dont recommend that you do so because the dBASE language, dBL, cannot deal with a multiple index file that doesnt have the same name as the .dbf.
If a multiple index file can contain 47 indexes, only one of these can be active at a given time. Another index can be applied at any time. Moreover, all of the entries of the evaluated index must have the same width. This width is limited to 100 characters. The formula needed to create an index (index on ) must not be longer than 220 characters.
The BDE can deal with requests from a maximum of 48 executables at a given moment. On a Web site, that means that if the BDE takes an average of three milliseconds to answer a request, thousands of people can visit a site but only 48 of them can receive some data contained in dBASE tables in a three millisecond period of time. If we accept that three millisecond average, a Web site based on dBASE is limited to a little bit more than 21 billion BDE requests a year. If they take an average of three seconds (which is unlikely), that limit drops to 21 million BDE requests a year. Over that limit, your site should be fed by a second computer.
How to create a table
There are two ways to create a table. It may be done either by using the dBASE interface or programmatically. The dBASE interface offers many ways to create a table:
Spaces should be avoided in the names of dBASE tables. Otherwise, you will have to place those names between quotes each time you want to apply a dBL command to these tables.
The Table Wizard
Serious books about dBASE programming usually avoid talking about the Table Wizard. Why? Because it is just for beginners. But hey! This series is aimed directly at beginners, so why not have fun?
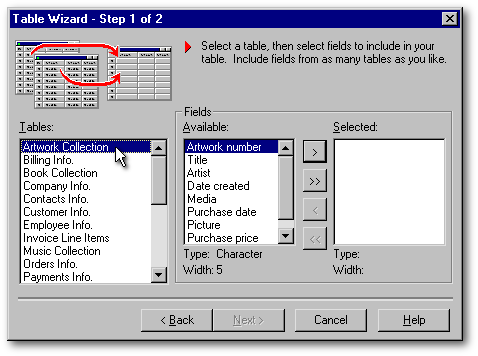
The Wizard has two steps. In the first one, you will be presented with a list of available table templates: e.g., an Artwork Collection template, a Billing Info template, etc. As soon as one of them is selected, a list of suggested fields will appear in the left of the Fields box. At this stage, you cannot change any field names or add new ones. (Be patient: you will be able to do that very soon.) Using the pushbuttons, you can move some or all the items from the list of available fields (on the left side of the Fields box) to the list of Selected fields (on the right side of the Fields box). When at least one field is selected, the Next pushbutton is enabled. It allows you to go to the next step of the Wizard.
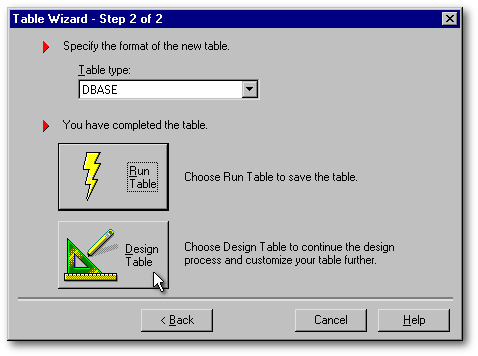
The last step is simple. Near the top, a drop-down listbox presents you with the choice to create a dBASE, a FoxPro, or a Paradox table. Then, if you push the Run Table button, you will save that table and see that its empty (its boring!). If you push the Design Table, your table will be loaded in the Form designer where you will be able to put the finishing touches on it (e.g., rename fields, change field type or width, create indexes, etc.) . This module allows you to access the Form designer with most of the job already done.
The Table Designer
Lets drop what we did in the Table wizard (it was for fun, wasnt it?) and go back to the time we had to choose between the Table Wizard and the Table designer. This time, we shall use the Table designer in order to do a small exercise: to create a Phonebook.
When it opens, the Table designer looks like a spreadsheet (see the next image). In a table, a field doesnt have a number. Yet in the Field column, numbers are displayed. These numbers are just there to help you to take advantage of the Ctrlg shortcut, which is used to move the cursor to a precise field number. When a table has a lot of fields, that shortcut might come in handy.
When we create a database, we often need to know the name and width of fields in other tables. Because of their small size, a few instances of the Table designer can be opened at the same time, showing the structures of several tables at once.
When you create a table, the principles that should guide you are simple. A field should stock the smallest unit of coherent data. You should avoid putting first names and last names in the same field. Nor should you put the city and province or state in a single field. On the other hand, you should put the entire street address in a single field even if it is composed of a number, a street name and an apartment number because it is unlikely that you will have to analyze any of these data separately. If you had to, you would have to create a separate field for it.
If the table will be part of a database, it should have a unique field (a field without duplicate values) that will make it possible for that table to be linked to another table on an identical field. For that reason, the data in a field should not be duplicated elsewhere in the table.
The field name
Its in the Name column that fields are named. Try entering a field name of First_Name using both upper and lower case characters. If its impossible for you to enter lower case letters, that means that you are creating a table with a table level lower than 7. If this is the case, dont save anything, close dBASE and go to the BDE Administrator and set the table level to 7 and load dBASE anew.
Under Visual dBASE 5, field names were limited to ten characters, couldnt contain a space (we had to use the underscore character instead) and had to start with a letter. In a level 7 Visual dBASE table, a field name can be up to 32 characters long, may contain spaces, and can start with just about anything. Having said that, I dont recommend that you start a field name with a number unless you are absolutely sure you will never use SQL (a database management language recognized by the BDE).
The field types
Once your first field has been named, push the Tab key or the Enter key to go to the next column or click on it. The cell will become a drop-down list. In this list, you will have to choose from among twelve field types. Since some text will have to be written in the First_name field, we shall select character as the field type. If you dont mind, lets give a look at the different field type available for level 7 tables.
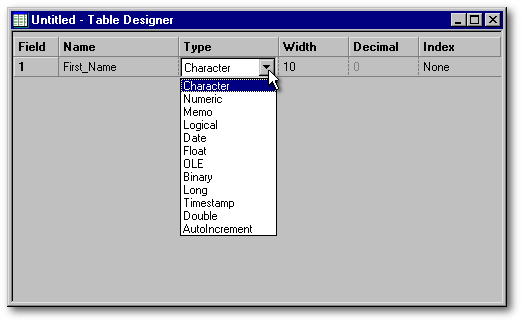
A dBASE table can store many types of data: text, number, image, sound file, OLE (Object Linking and Embedding), etc. In order to satisfy the wide range of needs from its developers community, dBASE has a large number of field types.
Before we review these field types, I would like to make a short comment about the meaning of binary. All data in a computer are made of values that could be qualified as binary (which means two numbers in Latin) because they have only two possible values: zero or one. Any of these zeros or ones is called a bit of data. Grouped by eight, these bits will constitute a byte. When a file contains bytes that represents not only letters, numbers and signs found on a keyboard, but also any of the other non-printing signs among the 256 possible values of a byte, that file is called binary. A text file created with Notepad is always a text file. The same text done in Word or Wordpad is a binary file (that can be read properly only by those applications that have an import filter). So a binary field is made to accept any of the 256 values of a byte.
The field width
- Character
They are the most popular. They can hold up to 254 letters, numbers, or any sign available on a keyboard. They can also store any mixture of letters and numbers.
- Numeric
If we take numeric in its broadest meaning, dBASE has five kinds of fields that can store only numbers: Numeric, Float, Long, Double and AutoIncrement. Use these fields when you want to store numbers that will be used in calculations.Actually, Numeric fields (in the narrow meaning) are specialized Character fields. First, the width of a Numeric field is limited to 20 bytes (including the decimals, the decimal point, and, if necessary, a minus sign). Moreover, when a byte in a Character field can have 256 possible values (the ones in an ANSI or ASCII table), a byte in a Numeric fields is limited to 13 possible values (any number between 0 and 9, the decimal point, the minus sign for negative values and the null value).
The value of a Numeric field is stored as a right-justified text. When dBASE needs to use that value, it transforms it on the fly to a number. This is why calculations based on Numeric fields take more time than the same calculations done on the Long or Double field types.
- Memo
With their unlimited size, Memo fields are the only way to store large amounts of text into a table. Yet each of these fields has a fixed width of ten bytes. How can dBASE compress any text into just ten characters? dBASE uses the ten characters to store a pointer to the text. The text itself is stored in a .dbt file whose name is the same as the .dbf to which it belongs. For example, if a memo field has been included in My_Table.dbf, a file called My_Table.dbt will be created. The pointer indicates the exact location of the text in the .dbt file.HTML tags can be used to format the text in a Memo field and to display bold or italic characters, words set in different fonts installed on your system, GIF or JPEG images, etc. In the case of these images, they are not stored in the .dbt file. The text in the Memo field contains an HTML tag that points to the location of the file on the hard disk.
The 16-bit version of the BDE (the one used by Visual dBASE 5.x) can experience unexpected memo bloat. Bloat is when the .dbt grows suddenly to hundreds of megabytes. This bug seems to have been corrected in the 32-bit version of the BDE (the one used by Visual dBASE 7.x and dB2K) since no such cases have been reported up to now.
- Logical
The size of a Logical field is limited to one byte since its value can only be T for true or F for false. When data is entered in a control connected to a Logical field, Y (for yes) and N (for no) will also be accepted and transformed internally into T or F.You cant build an index directly on a Logical field. Nevertheless, an index can be build if the value of the Logical field is transformed into a character, as we will see later.
- Date
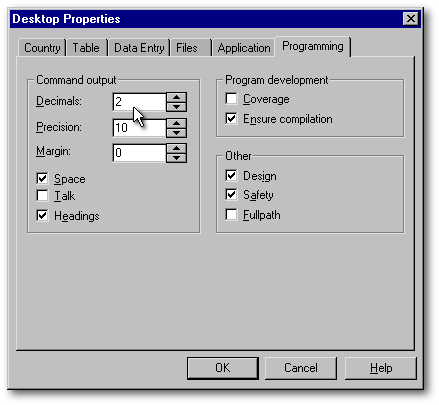
These fields are specialized Character fields: their width is limited to 8 bytes and are used to store dates. The year is stored in the first four bytes while the month and the day are each stored in two bytes. Even if the date is always stored internally in the year-month-day format, it is displayed in the format set in the vdb.ini or the db2k.ini. file. The user can change the display format with the set date command (for example, set date YMD or set date American) or on the Country tab of the Desktop Properties dialog box. See the image in the Current vs Specific language or level section earlier in this article).
- Float
Under Visual dBASE5, these fields were specialized in storing floating-point numbers. They correspond to Double fields under the 32-bit versions of dBASE. There both have Float fields only to be compatible with VdB5: under the newer versions of dBASE, a Float field is just a Character field limited to 20 bytes (including the decimals and the decimal point). It can contain positive or negative values.
- OLE
These fields can store OLE objects created by other Windows applications. The width of an OLE field is just ten bytes and contains only a pointer indicating the precise location of the OLE object stored in the .dbt file.
- Binary
These fields are used to store binary files (most of the time images or sounds) in a table. Their width is only ten bytes. The field itself stores only a pointer indicating the precise location where the binary file stored in the .dbt file. There is no limit to the size of the binary file stored in the .dbt, other than the two gigabyte limit of a dBASE table.
- Long
First included in novelty from Visual dBASE 7, these binary fields have a fixed width of four bytes. dBASE doesnt try to know what the value of each byte is (for example, to which character in an ANSI table the byte value corresponds) but rather treats these 32 bits as a single block that has 232 (4,294,967,296) possible values. Because the Long field is interpreted as a 32 bit wide block of data rather than as four bytes is why we call it long.It might contain any whole number between -2,147,483,647 and +2,147,483,647. If you calculate the total, two values are missing: they are zero and null. Zero is stored as +0, and null is stored as -0. A Long field can not contains decimals. For the benefit of those who want to know everything, in these 32 bits, the first one is used to indicate the sign: zero if its a negative number, one if its positive.
When a main table contains an AutoIncrement field and has to be linked to a child-table, one of the best ways to implement that is to link the AutoIncrement field in the main table to an indexed Long field in the child table.
- Timestamp
New since Visual dBASE 7, Timestamp fields have a fixed width of eight bytes and are used to store the date and time of a precise moment. Note: The time precision extends to the second.
- Double
These fields first appeared with Visual dBASE 7. They are called double not because they worth two bytes but because their length is eight bytes, twice as large as a Long field. Like a Long field, a Double field can store positive or negative numbers and was optimized for mathematical operations. Contrary to Long fields, Double fields can store decimals.When you set a field to be Double, the Table designer disables the cell in which you set the decimals and writes zero. This suggests that Double fields cant have decimals. That is a false impression. Internally, the 32-bit versions of dBASE save the data with a precision of about fifteen decimals. For display purposes only, this data will be rounded on the fly to the number of decimals set by the Decimals item in the [CommandSettings] section of your vdb.ini or db2k.ini. You can change that precision from the Command window with the command set decimals to N (where N is the number of decimals you want). This can also be done with the Properties|Desktop Properties menu item, under the Programming tab.
- AutoIncrement
Also new with Visual dBASE 7, the AutoIncrement field is a variant from the Long field. Their similarity explains why it is suggested to use an AutoIncrement or Long field from a table can be linked to an AutoIncrement field from another table. Contrary to a Long field, an AutoIncrement field cannot be edited and is created by dBASE at the exact moment the record is saved.A table cant have more than one AutoIncrement field. Even if the Table designer seems to allow more than one of these fields to be created in the same table, the BDE will not allow you to save it.
- _dbaselock
This field is very different from the other ones: its the only one that cant be created from the Table designer. From the Command window, you have to open the table in exclusive mode and use the command convert. In a network environment, this field is used to write the identity of the most recent user who changed a field value or modified the structure of a table. It also shows the date and time of that change. By default, it is 16 byte wide.
use My_Table exclusive
convert
display structureIt should be noted that it is not enough to merely ask for the table to be used exclusively to get that permission. Exclusive use will be granted to you only when nobody else is using a table. On a network, its different. If someone else already requested exclusive use of the table, or if your request was communicated to the BDE at the exact moment some changes were written to a table, your request could be refused without a warning. If you work in a network environment, after you asked for a _dbaselock to be added to a table, it would be better to check if that was done. Use the command display structure to make sure the field was added. The _dbaselock field will be last in the list. Tip: when you have succeeded in opening a table in exclusive mode, the statusBar displays something similar to my_table.dbf exclusive Row: 1/n. If the word exclusive doesnt show, thats because you failed.
Lets go back to creating the structure of your phone book table. Set enough room to Width to be able to enter all the data the field must contain. For example, to enter the number 12.50, you need five bytes: two for the decimals, one for the decimal point, and two others for the numbers left to the decimal point. If it is possible that the number could be negative, you would need six bytes.
If these numbers are monetary values on which you will make calculations other than additions and subtractions, use five or six decimals in order to get the precision needed and let dBASE round the results and display two decimals.
To index or to sort
You can create indexes on any field except Binary, _dbaselock, Logical, Memo and OLE. When the cursor is placed in the Index column, the cell is transformed into a drop-down list with three choices: None, Ascending and Descending. It allows you to create an index on ascending order, descending order, or to delete an index. Later we will see how to create complex indexes, i.e., an index on something other than a single field, for example.
In an indexed table, the records stay in the same order in which they were entered into the table. When an index is created, a new file (if it doesnt already exist) is created bearing the same name as the table except that its extension is .mdx instead of .dbf. It contains a value based on the value of the indexed field and a pointer (usually the record number) to the position of the corresponding record in the table.
Just as the person in charge of Protocol at the White House will know who can sit to the left or the right of the President at an official dinner, regardless of the order the guests arrived for the occasion, an index knows the order in which the records should be displayed in browse mode when the table is indexed, regardless of the order the records were added to the table.
Why not simply reorder the records in the table so that they would be natively in the order we want, rather than having an index interpose itself between the table and us? Because an index has many advantages :
That being said, there could be very good reasons to sort a table. For example, when an archived copy of the members of an association is wanted for a specific year. In that case, the command sort is used. This command creates a new table, identical to the original table, under a new name. There are two main differences though: the new table is ordered on one of its fields and no indexes are transferred to the new table.
In the following
example, we create a new table (called
Members_2001)
from
an existing table called My_Table.
Those records in My_Table
whose
Year_of_membership field
contains a value of 2001 will
be copied to the new table, ordered by
name.
|
use My_Table sort on Name to "Members_2001" for "Year_of_membership" = "2001" |
|
When a table is opened from the Command window, a list of its indexes can be seen with the command display structure (F5). An index will appear in the Results pane only when the following conditions are met :
|
xDML: use My_Table exclusive index on Field_Name tag Index_Name use |
||
|
OODML: |
||
| index1
= new DBFIndex()
index1.indexName = "Index_Name" index1.expression = "Field_Name" _app.databases[1].createIndex("My_Table", index1) |
// we create an index object
// it is given a name // it is defined as a simple index built on a field // '_app.databases[]' is the array containing the names // of all the tables in the current folder |
|
If you wish
to create an index from the Command window on a field with a space in the
field name or on a field that starts with a number, you must place the
field name between colons and the name of the tag, between single or double
quotes. For example, if a field name contains a space:
index on :Last name: tag "Last name".
With OODML, one would write:
|
:Index Name with Spaces: = new DBFIndex() :Index Name with Spaces:.indexName = "Index Name with Spaces" :Index Name with Spaces:.expression = "Field Name with Spaces" _app.databases[1].createIndex("My_Table", :Index Name with Spaces:) |
|
From the
Command window, an index can be created on a Logical field. The trick is
to base that index not on the actual value in the logical field but on
a character value created on the fly.
|
use My_Table exclusive index on IIF(Logical_field
=
true, "Yes", "No_") tag
"Logical_field"
use |
|
With OODML, an index based on a
logical field could be created the following way:
|
Yes_No_ = new DBFIndex() Yes_No_.indexName = "Yes_No_" Yes_No_.expression = [iif(Logical_field = true, "Yes", "No_")] _app.databases[1].createIndex("My_Table", Yes_No_) |
|
In the code above, the conditional command IIF (which is different from the IF command) will write Yes as the key value when the field named Logical_field is true and No_ when it is false.We could have chosen Y and N, respectively, but we wanted to stress the importance of fixed length index: this is why we added an underscore to No.
In the code above, the part that says = true is superfluous in an IF or an IIF statement. We left it for clarity. Likewise, the quotes around the field name Logical_field are superfluous since the field neither contains spaces nor starts with a number. Finally, when an indexed table is displayed in a browse view or in a grid, the vertical scrollbar doesnt work properly. Thats the only shortcoming of dBASE indexes.
The command display status (F6) reveals all the indexes, even the ones which are not displayed by display structure (F5).
To delete
an index from the Command window, we have once again the choice between
xDML and OODML:
|
xDML: use MyTable exclusive delete tag My_Index use OODML:
|
|
To add other fields
In the Table designer, when the cursor is in the column reserved for the indexes, we skip to the next line by pushing the Enter key. When the cursor is in the Field column, it becomes an open hand. This is a reminder that the column order can be modified through dragn drop.
The Table designer has the following
shortcuts:
| Shortcuts | Effect | ||
| Up Arrow | to go to the previous field | ||
| Down Arrow | to go to the next field or, if on the last field, to create a new field | ||
| Right Arrow | to go to the next character in the field | ||
| Left Arrow | to go to the previous character in the field | ||
| Enter key | to go to the next column or, if in the last column of the last field, to create a new field | ||
| Tab key | to go to the next column or, if in the last column of the last field, to create a new field | ||
| Shift Tab | to go to the previous column or to go to the last column of the previous field | ||
| Ctrl a | to add a new field at the end of the list | ||
| Ctrl n | to insert a new field | ||
| Ctrl u | to delete the field in which the cursor is located | ||
| Ctrl g | to move the cursor to a specific field number | ||
The shortcuts
to add or delete a field correspond to the toolbuttons ![]() on the Toolbar and correspond also to some items in the Structure
menu.
on the Toolbar and correspond also to some items in the Structure
menu.
Lets complete the table structure in order to get something like the one shown in the following image. Adapt it to your needs. If one of your field names is quite long, the width of the Name column might be too narrow to display it completely. In order to widen that column, place the mouse cursor over the line separating that column from the next one and drag it to the right.
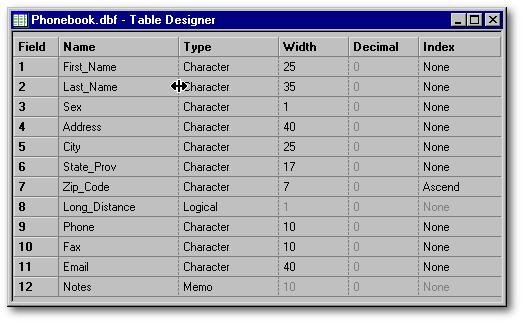
It is possible to change the column order in the Table Designer window using dragn drop. When you place the mouse cursor over the header of any column (except the Field column which cant be moved), that cursor will be changed to an open hand. Drag the header to move the column where you want it to be. This process has no effect on the table structure. If you close the table and open it anew, the columns will be in exactly the same order as they were originally.
More important is that in the Table Designer you can change the order of the fields in a table using dragn drop. When the mouse cursor is placed at the far left over a field number, the mouse cursor is changed to an open hand. Drag the field up or down to the place you want it to be. If you save the table and open it anew, the changes you made will be reflected in the new structure of that table.
In the case of phone numbers and zip codes, you should not make any provision for number separators. For example, if you would like the phone numbers to be displayed as (123)456-7890, dont make room for the parenthesis nor the dash. dBASE has all the tools to format a field: the user of your application will thus not have the burden to type these separators when the data is entered.
To save a table, select the item File|Save from the menu or use its Ctrls shortcut. A dialog box will ask you to give a name to that table before saving it. That name could be anything, as long as it is not a dBL command, nor contain a dash (in such a case, you would have problem making SQL queries on that table), nor contain accented vowels (as the BDE will have problem dealing with its indexes).Using Ctrl-w will save the file and close it automatically.
How to modify the structure of an existing table
From the Navigator, one can use any of the following means to call the Table designer to change the structure of a table. Under the Table Files tab in the Navigator:
| use My_Table exclusive | // replace 'My_Table' with the name of the table to open | |
| modify structure | ||
If the table already contains data and you would like to rename many fields, it would be more prudent to make the changes one at the time (and save the table between the changes) rather than doing all these changes in one step, specially if these fields are in succession in the table structure.
The On-line Help states the following under Modify structure: You shouldnt change a field name and its width or type at the same time. If you do, Visual dBASE wont be able to append data from the old field, and your new field will be blank. Change the name of a field, save the file, and then use modify structure again to change the field width or data type. Also, dont insert or delete fields from a table and change field names at the same time. If you change field names, modify structure appends data from the old file by using the field position in the file. If you insert or delete fields as well as change field names, you change field positions and could lose data. You can, however, change field widths or data types at the same time as you insert or delete fields. In those cases, since modify structure appends data by field name, the data will be appended correctly.
If you have to add or to delete multiple fields, this can be done without saving in between each change as long as you dont rename fields at the same time. The Ctrls shortcut saves the changes while the Ctrlw saves the changes and closes the Table designer in a single operation.
How to copy a table
Even if the 32-bit versions of
the BDE are a lot more reliable than the one used by Visual dBASE 5, it
is more prudent to make a back-up copy of a table before making changes
to its structure.
| copy table My_Table to Back_up_copy | |
To make a
copy of a table, we have the choice between two xDML commands.
Copy table "Old_Table" to "New_Table" allows
you to create a table without having to open it first. If there
are .dbt and .mdx files
associated with the table being copied, those files will
automatically be created also. The new table will have the same language,
the same indexes, and the same level as the original table. In a nutshell
it will be a perfect copy. The second command,
copy to "New_Table"
requires
that the table be open. The new table will have the same language driver
and the same level as the original table. The
copy to
command doesnt copy the _dbaselock field. If you start with the original
table sorted according to an active index, the records in the new table
will be sorted in that order. But, in this instance, no
.mdx file
will be created. If we add with
production
to the latter
command,
the new table will be sorted according to
the active index in the original table and will have its own
.mdx file.
|
use "Old_Table" order tag "Index_Name" copy to "New_Table" with production |
|
| use | |
OODML has
a command similar to Copy table
in
the sense that it doesnt need the table to be open and it makes a perfect
copy of the table (with its .dbt
and
.mdx)
as long as that table is in the current folder. That OODML command is:
|
_app.databases[1].copyTable("My_Table", "Copy_of_My_Table") |
|
How to add records
 By
default, when dBASE adds a new record to a table, it does it in Column
mode ( i.e., with all the fields aligned one under the other). Nevertheless,
a table can be displayed in three different modes: in the Column mode,
in Form mode, or in Table mode (i.e., in a spreadsheet). You can toggle
from one mode to the next by pushing the F2 key. In Browse mode, it is
possible to change the column width or the column order. When their order
is changed, that doesnt modify the structure of the table (unlike what
happens in the Table designer).
By
default, when dBASE adds a new record to a table, it does it in Column
mode ( i.e., with all the fields aligned one under the other). Nevertheless,
a table can be displayed in three different modes: in the Column mode,
in Form mode, or in Table mode (i.e., in a spreadsheet). You can toggle
from one mode to the next by pushing the F2 key. In Browse mode, it is
possible to change the column width or the column order. When their order
is changed, that doesnt modify the structure of the table (unlike what
happens in the Table designer).
It is possible to add new records to a table displayed on screen by using any of the following means:
The vast majority of the records added to dBASE tables are added through dBL applications. When we have to use the dBASE interface to add new records, its to create a few records in order to test a user interface or a specific program. If this is the case, here are three tips that will make your job easier.
When a table contains a memo field, and if that field is empty, the field will be represented by the icon of a white page. If it contains data, it will be represented by an uppercase A on a white page. It is possible to ask dBASE to display those fields in a small editor in order to have a preview of their contents. dBASE can do that when a table is displayed in Column mode or in Form mode, but not in Browse mode. Select the menu item Properties|Desktop Properties, and, under the Table tab, click the Associate Component Types button. In the dialog box that appears, beside the memo field type, select the Editor radiobutton. If the table is already displayed, close it and open it anew to make that change effective. For now on, that change will also affect the Table designer. By default, editors will be proposed to display the content of memo fields in all modes except Browse mode.
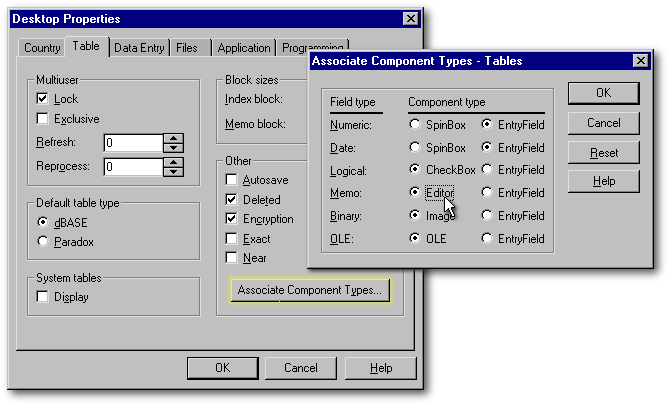
Again at the menu item Properties|Desktop Properties, this time under the Data Entry tab, if the CUA Enter checkbox is empty, you will be able to move to the next field with the Enter key (as you can with the Tab key). The only exception is when the cursor is in a memo field. In such a case, the Enter key will behave once again like the carriage return of a typewriter. In Column mode or in Browse mode, the Tab key or the use of a mouse will be the only ways to get out of the memo field.
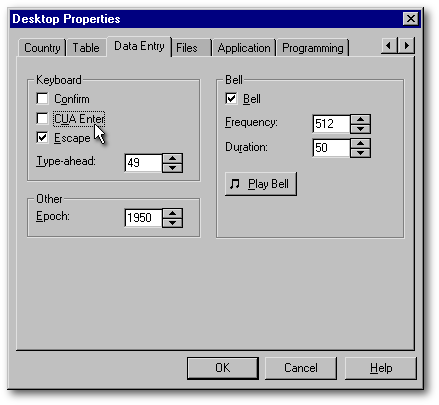
Finally, above the CUA Enter checkbox, there is a checkbox called Confirm. When the Confirm checkbox is empty, the cursor will automatically move to the next field as soon as a field is full (a bell sound will tell you when the end of a field has been reached). If you have to enter the answers to a survey, that tip can save you from pushing the Enter key thousands of times. Once you have become skillful, you might want to shut down the bell sound by unchecking the Bell checkbox.
You can get
the same results from the Command window or from dBL applications that
we just got from Desktop Properties. We can do this by entering the following
commands:
|
set CUAEnter off set Confirm off |
|
In the dBASE for DOS versions, once a record was completed, the Enter key allowed us to create a new record (if we were appending records) and to move to the beginning of that new record. Under the 32-bit versions of dBASE, the Enter key works only in Browse mode. In Column or Table mode, the easiest way to add a new record is with the Ctrla shortcut.
Special cases
From the dBASE interface, the data entry doesnt cause any problem except for certain field types. A _dbaselock field is always invisible. When you are creating a new record, if it contains an AutoIncrement field, this field will be empty since its number will be added by dBASE at the precise moment that record will be saved. Finally, dBASE deals with OLE fields like any Windows application.
Memo fields
In Column mode or in Form mode, the Tab key allows the user to access and to quit a memo field when it is displayed in an editor. In Browse mode, we can access the memo field by any of these means:
Many of these methods will also work for binary fields. I would like to explain the only method that works whenever the binary field contains an image or a sound. The table has to be open in Browse mode. (Push the F2 key if the table is open in Column mode or in Form mode.) Double-click on the binary field to open the Specify Binary Field Subtype dialog box. In this dialog box, you will have to specify if you want to store an image or a sound in that field. dBASE will offer an empty image viewer or a sound player. Right-click on it and select Import Image or Import Sound Go to the folder where the image or sound is located and select it. Once the viewer or player is closed, the image or sound will be copied in the .dbt file and registered in the binary field. When the binary field contains data, the eight zeros that represents an empty binary field will be replaced with the icon of a sunny landscape or with the icon of a musical note. Double-click on it to view the image or play the wave file.
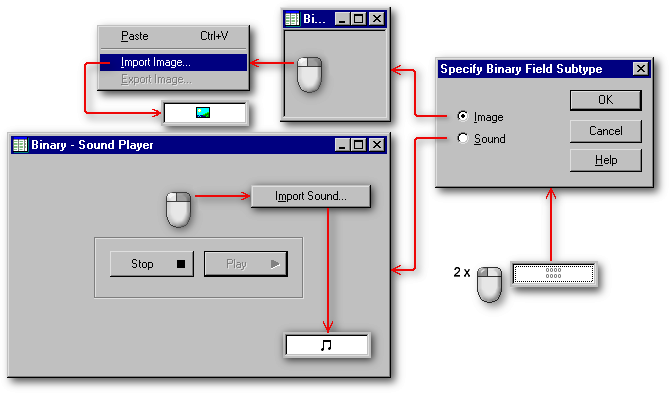
The 32-bit versions of dBASE support a wide range of color formats:
Anything
can be stored in a binary field.
For example, one could hide the commercial plans of his company. Contrary
to OLE fields,
that can be visualized in Column mode or in Form mode, and which content
can be double-clicked and loaded in an application able to read them, a
binary field
remains a total mystery when it is used to store anything else but an image
or a wave file. In order to store or to extract the file Secret_plans_of_the_Penta.gon,
we just have to do:
|
xDML: replace binary Binary_field from Secrets_plans_of_the_Penta.gon type 10 // to store copy binary Binary_field to Secrets_plans_of_the_Penta.gon // to extract the stored file OODML: form.rowset.fields["Field_Name"].replaceFromFile("File_Name") // to store form.rowset.fields["Field_Name"].CopyToFile("File_Name") // to extract the stored file |
|
At the end of the first line of code above, the type number can be any number between 1 and 32767. Believe me, if your data is encrypted, it will be impossible, even to the KGB, to find the secrets hidden in your table. Note: In Browse mode, when a binary field contains something other than an image or a wave file, it will be represented by the black numbers 0100 0010, while an empty one will be represented by eight pale gray zeros.
If you dont want to type the name of the file to store in a binary field, you just have to type replace binary Binary_field from ?. The question mark will call the OpenSource File dialog box (but the only possibility will be to choose among .bmp files). Similarly, for an OLE field, the command will be replace OLE OLE_field from ?.
From the Command window, if you want to delete the content of a binary field or an OLE field, use the command blank field Binary_Field_Name.
Append From vs AutoIncrement fields
When a table has an autoIncrement field, a flag in the tables header keeps track of the autoInc number by storing the hexadecimal value of the next AutoInc number. If we do a simple append using the xDML Append command (not the Append from command), that flag is updated.
However, when multiple records are added en masse using the Append from command, that flag is not updated. The target table inherits all the autoInc values from the source table. The records are copied as such. The autoInc flag in the tables header is neither used nor updated. It is simply ignored. Actually, the Append from command usually doesnt update the autoInc flag. Why usually? Because if we add the clause for true to the Append from command (Append from for true), then the flag will be used and updated. Complicated? Yes, but there is more.
When all the records in a table
are deleted (using the zap command),
the autoInc flag is not reset. Nor is it decreased when the last saved
record is deleted. Lets see some practical examples, just to see if everything
is well understood.
|
use Source_Table // Source_Table has an autoIncrement field copy structure to Target_Table use Target_Table // which is empty for now append from Source_Table |
|
In the above example, the autoInc
numbers in the Target_Table are those found in the Source_Table. The first
autoInc number given to the next record added to the table with a simple
Append command will be
1. This is because all the autoInc numbers that were already in the table
were ignored since they were written without changing the tables header
autoInc flag. Moreover, if the target table is appended
en masse
once again, but this time from another table that has some identical autoInc
value, we would end up with duplicate values. This is where the
for true clause is valuable.
If we had used the following code:
|
use Source_Table // Source_Table has an autoIncrement field copy structure to Target_Table use Target_Table // which is empty for now append from Source_Table for true |
|
In this case, the BDE will increment the autoInc number correctly in Target_Table, starting from number one. Any record added individually will bear the next autoInc number available.
Does it mean that the
for true clause should
always be used? Not necessarily. There might be situations where we would
want the autoInc number in the source table be retained in the target table.
Our problem is that the first new record added thereafter will not get
the following autoInc number. How can this problem be avoided? Prior to
the Append from command,
we just have to create (then delete) the number of records needed to set
properly the autoInc number in the tables header. For example, if the
autoInc number in the source table stops at 500 and thus we want the next
autoInc number to be 501 when a simple
Append command is issued,
we would use the following code:
|
use Source_Table // Source_Table has an autoIncrement field copy structure to Target_Table use Target_Table exclusive // the following line of code will increment // the autoInc flag in the tables header generate 500 zap // this command needs exclusive use of the table append from Source_Table |
|
If we start with a source table that doesnt have an autoIncrement field and append its records into a target table that does have such a field type, what will happen? In that case, the autoIncrement field will be empty for all the records added en masse. Thereafter, the first record to be added to the target table with a simple Append command will bear the next autoInc number, as if the records added en masse never existed. That problem would have been avoided with the for true clause.
If one of your tables is at risk
of duplicate values because you made some of the mistakes weve spoken
about, you could renumber the values in your autoIncrement field. If you
dont care about the starting autoIncrement value, the easiest solution
is to use SQL:
|
Alter table Target_Table drop Field_Name Alter table Target_Table add Field_Name AutoInc |
|
In the dUFLP is a file called DBF7File.cc
which has the ability to change the value of the autoincrement field. For
example, the code needed to set the next autoInc number to 325 in a table
called Target_Table, would be:
|
set procedure to DBF7File.cc additive oFile = new DBF7File("Target_Table.dbf") oFile.setNextAutoIncValue("Field_Name", 325) oFile = null |
|
The null values
At the moment a new record is created, all its fields look empty. When using level 7 fields under a 32-bit version of dBASE, these fields are not really empty. They contain a null value. This null value can be seen as a proof of the virginity of a field. For example, when the user writes some data in a field and erases everything afterwards, the field is empty but has lost its virg I mean its null value. In the case of a numeric field, when it contains a null value, nothing can be seen in that field. If the null value has been lost, a number (zero, for example) is seen in that field. Note: Simply passing through a field with the Tab key is not enough to cause it to lose its null value status. These are a few examples of the advantages of null values:
|
if City = null replace City with "" endif |
|
Under dB2K, it is easier to deal with null values:
When a table is displayed in the dBASE interface ( i.e., not by a dBL application), one can use any of the following methods to delete some of its records:
|
use My_table browse // to display the table delete 20 // to delete the 20th record go top // to make that suppression visible |
|
At the bottom of the dBASE window, you should see the Statusbar. If you dont, just type the following command in the Command window: _app.statusbar = true. On its right end, the Statusbar indicates the record number. (For example, if it says Row 6/2500, it indicated that youre on the sixth record in a 2500-record table). With the arrow keys, if you navigate in the table (i.e., if you move the record pointer to another record), the table pointer should skip over the deleted record number. The explanation is simple: deleted records still exist because they have been marked for deletion, not physically removed. From the Command window, if you type the following command: set deleted off and if you move the record pointer, the deleted records will reappear. Under a 32-bit version of dBASE, the Statusbar will display something similar to Row 6/2500, Deleted when the record pointer is over a deleted record. Once you are through, type set deleted on to reset dBASE to its normal behavior.
In Visual dBASE 5, it is easy to see the deleted records in a Browse window: when set deleted is off, the deleted records have a red x in the second column (the one immediately after the record number). The user just has to click the checkbox to delete or to recall a record.
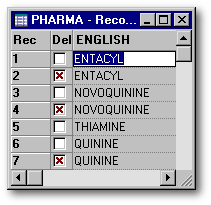
In order
to physically remove deleted records from a table, use the
pack command
or the packTable() function.
Though this process can be slow when run on huge tables, it is necessary
to eliminate the burden of carrying unnecessary records in a table, thus
speeding up applications that use that table.
|
xDML: use My_table exclusive pack use OODML:
|
|
To unmark records in a table that have been marked for deletion, one has only to use the command recall all. This command works only if dBASE was allowed to display the deleted records with the command set deleted off. If you want to recall only one record, once you have taken note of its record number (that number appears in the Statusbar when the record is selected), the command recall N (where N is the record number) will recall it. The ability to recall deleted records is an unique characteristic of dBASE tables.
How to view the records in a table
To consult a table, the user can:
Note: The Open File dialog box (above) will look different according to the language and the version of your Operating System.
When the user is working in dBL, dBASE offers the programmer many means to protect tables against data corruption. Under a 32-bit version of dBASE, however, this is not the case when we view a table from the dBASE interface. There is no security net (e.g., just an Undo or its shortcut Ctrlz). So be careful not to modify your data inadvertently. For example, when a Browse window opens, its first cell is selected. If a key is pressed its value will replace the highlighted value. Under Visual dBASE 5, full protection is provided with the command browse noedit (or browse noedit noappend) when the Command window is used.
Note: In the Phonebook table, dont be surprised if one of its fields has a colored background. We will see how this is possible near the end of this article.
Once a table is displayed, dBASE will update its Toolbar with a new set of tools made to deal with tables. Look at the enabled buttons in the image below. From left to right, the first two buttons allow the user to view a table or to modify its structure, respectively.The next three buttons allow you to select between the three viewing modes of a table: Browse mode, Column mode, or Form mode. The next five buttons are used to add, delete, save, to cancel, or find a record. With the next two buttons, the table will be ordered in ascending order or in descending order, but only if indexes have been set up to allow that. The last four buttons are VCR-type buttons that allow you to navigate within the table. From left to right, the VCR buttons take you 1) to the first record, 2) to the previous record, 3) to the next record, and 4) to the last record in the table.
![]()
The following shortcuts can also
be used to navigate in a table displayed:
| navigation | in browse mode | other modes | |
| First
record of table
Previous page Previous record First field or Beginning of current field Previous field Next field Access a memo field Quit a memo field Last field or End of current field Next record Next page Last record of table |
Ctrl
Home
PgUp Up arrow key Home Shift Tab Tab or Enter F9 or double-click icon Ctrl F4 or Ctrl w End Down arrow key PgDn Ctrl End |
Ctrl
Home
PgUp Shift Tab Tab Tab* Tab* PgDown Ctrl End |
|
| To
add a record
To find a record To replace data To save changes |
Ctrl
a
Ctrl f Ctrl r Ctrl s |
Ctrl
a
Ctrl f Ctrl r Ctrl s |
|
All the functionality of the Toolbar can be found in the Table menu, which is available when a table is displayed. If the only way you will use tables will be programmatically, go directly to the section How to combine many tables into a single one (later in this article). On the other hand, if you would like to know all the possibilities of your software, lets check out the items in the Table menu.
When you select the item Delete Rows , three choices are available to you: Current, Specified and All. When Specified is chosen, the user has to specify the characteristics of the records to delete. The changes will take effect only after the record pointer has been moved to the beginning or to the end of the table (or after the table has been closed and been open anew).
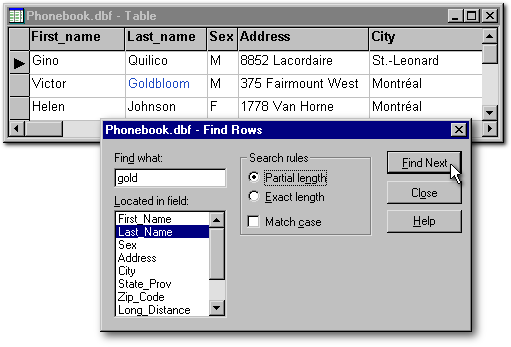
With the item Find Rows (see the image below), the user can make a search based on the first characters (letters or numbers) of the value of a field, whether that field is indexed or not. In the Find Rows dialog box, the user has to select a field in the Located in field list. This search does not use indexes and therefore can be accomplished rapidly only when the table has few records. When the table has many records, the search will be slower since dBASE has to look into each record, one after the other, until it finds a record meeting the search criteria.
In the following example, the search is made on the letters Gold or gold in the Last_Name field. When the Find Next button is clicked, the record cursor goes from John Does record to Victor Goldblooms record. In the Search rules rectangle, there are two radiobuttons. When Partial length is selected, dBASE will find a record as long as you type in the first few letters of the last name. If Exact length is selected, the entire last name must be typed into the field (for example goldbloom). When the Match case checkbox is checked, the search key will have to start with an uppercase letter in order to find a name.
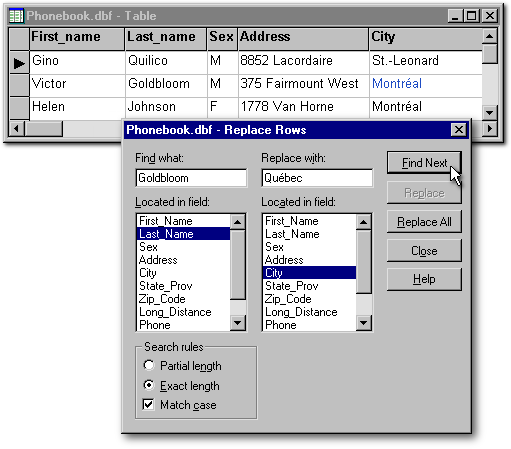
With the menu item Replace rows , it is possible to make a search on a field and to change the content of another field (or the content of that same field). For example, in the screenshot below, some members of the Goldbloom family are living in Québec City and we entered them by mistake as living in Montréal. If we click the Find Next pushbutton, we will have the opportunity to change the City for the first Goldbloom or for the next one. When clicked, the Replace pushbutton will change the city and jump to the next Goldbloom. This is why the user will get the error message Value not found when he replaces the city of the last Goldbloom of the table.
If all the Goldblooms in our table have moved to Québec City, we could apply the change globally by clicking the Replace all pushbutton. If we do so, after the changes have been made, a dialog box will ask for confirmation. If we cancel those changes, the table will give the impression of having been unaffected by that cancellation. If we close that table and open it anew, we will see that our cancellation is effective.
The menu item Begin Query by form is very spectacular. It is easier to see it in action when the table is not displayed in Browse mode. Please push the F2 key until the table is displayed in Column mode or in Form mode. As soon as that menu item is selected, all the data displayed from that record will be erased. Relax no harm has been done to your table. Just type your search criteria in the appropriate field. For example, if you want to find the last name Goldbloom, type in the complete family name (Goldbloom) in the Last_name field just Gold wont work. Then re-open the Table menu and select Apply Query by Form. The form will display Victor Goldblooms record. This search method is quite slow because dBASE has to pass through each record in order to find a record that meets the search criteria. Moreover, this search method is primitive since only the first record that meets your criteria can be found. If none of the records meet the criteria you set, you get an error message Value was not found. If you get that message, use the vertical scrollbar to bring the records back into view.
The menu item Begin Filter by Form doesnt have that last shortcoming. After that item was chosen, when we apply the filter by selecting the Apply Filter by Form menu item, the table is kept under the influence of that filter until we select Clear Filter by Form. As long as the filter is effective, we can use the VCR buttons on the toolbar. But navigation will be allowed only among the records that fill the filter criteria. With that search method, unfortunately, you will not be able select the people living outside a city or those whose phone number is greater than a number. Moreover, when the user types a value that doesnt exist in the table, dBASE will show an error message, then will display the form with all its controls empty. If the user selects Clear Filter by Form, the fields stay empty as if he were creating a new record. If the user navigates in the table, he will see that its not the case.
Begin Filter by Form can be used to filter the records to be deleted if all of them have a common and exclusive characteristic. When navigation is restricted by the filter, we can see the records that will be deleted. If we select the All option from the menu item Delete Rows , dBASE will delete selectively the filtered records. We have to cancel the filter to see the remaining, unaffected records.
The menu items Sort Ascending and Sort Descending can be used only when the cursor is inside an indexed field. Moreover, the index has to be a simple one. If the index is a complex one (as we will see further), that index will not be recognized.
The menu item Lock Columns is available only when the table is displayed in Browse mode. A certain number of consecutive columns can be anchored at the left of the browse window. These columns can then be seen when the horizontal scrollbar is used and when normally these columns should fell out of view. If these columns completely filled the Browse window when they were locked, stretching the Browse window will not show the other columns. The user will have to resize the window approximately to the size it was before and make the columns thinner until they dont fill the window any more. Then it will be possible to see the other columns. To cancel the lock, either re-open Lock Columns and put the counter back to zero or close the Browse window.
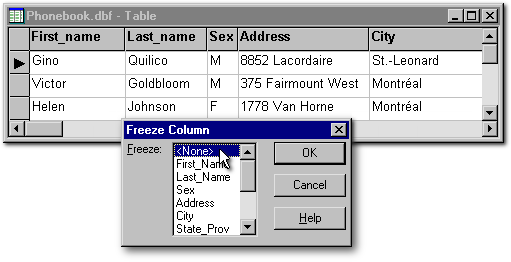
The menu item Freeze Column limits the cursor inside a column. This item is available only in Browse mode and its effect is canceled when the user closes the table, quits the Browse mode, or when <None> is chosen in the Freeze Column dialog box (see the image below). This menu item is not canceled when other menu items are chosen and thus, is compatible with them. For example, if some of our Goldblooms were actually Goldbergs whose names had been misspelled, we could review the table by filtering on Goldbloom and by limiting the cursor to the LastName field. This would prevent any damage to other fields in the editing process.
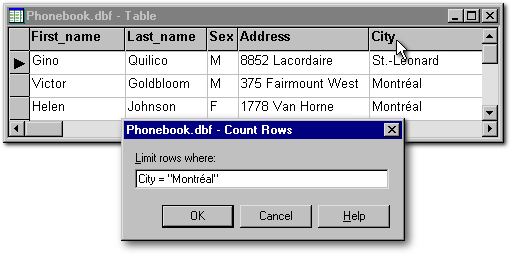
The menu item Count Row gives the number of records corresponding to a criteria. In the following example, we will learn how many people in our Phonebook are living in Montréal. Had the name of the field contained a space, the name of that field would have to be put between quotes (e.g., "Zip code" = ). On the other hand, if our criteria would have been based on a numeric field, the value of that field, at the right of the equation, would have to be typed without quotes.
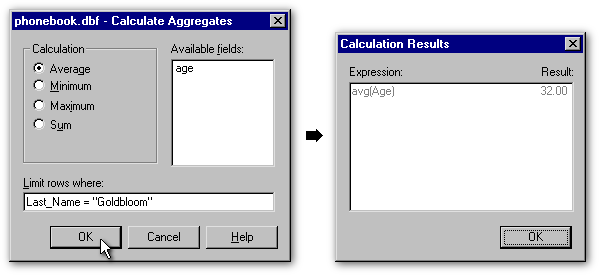
The menu item Calculate Aggregates works only on numeric fields. For the sake of this demonstration, we temporarily added a numeric field to store the contacts age in our Phonebook table. This menu item allows us to calculate the average, the minimum age, the age of our oldest contact, or to get the total number of years of the people in our table. We also can apply these calculations to a subgroup of people. The Limit rows where: entryfield was made for that purpose. In the example below, we learn that 32 years is the average age of all the Goldblooms in our table.
Since the
Table
menu doesnt offer a means to rename a table, we shall use the Command
window. In order to rename a table, the table has to be closed. The code
is :
|
xDML: rename table "Old_Name" to "New_Name" OODML:
|
|
How to combine many tables into a single one
Lets suppose
a group of workers have to go on the streets to gather data for a survey.
All these people are using different tables but each has the same table
structure. Lets also suppose that you have to combine all this data into
a single table. First copy those tables in the same folder. (This is not
an absolute requirement. Putting all the files in the same folder saves
you the trouble of having to type path names.) Then type the following
code into the Command window:
|
use Main_Table exclusive append from MiniTable_1 reindex append from MiniTable_2 reindex append from MiniTable_3 reindex |
|
Some of you might wonder why reindex command is used. Havent we said that dBASE updates all the indexes of a table as soon as a new record is added to it? Yes, precisely for that reason, we want to prevent dBASE from updating the indexes after each new record. We want it to update the indexes only when all the records have been added to a table. The reindex parameter, contrary to what it suggests, postpones the update to the end of the appending process for a given table.
How to create a complex index
In our phone book table, the Last_Name index allows us to see our contacts ordered by family name. Unfortunately, it is not possible to call a sub-index that would allow us to see the members of a family ordered by their first names. Of course, we could create an index on the field First_Name but we would have to chose between seeing our data ordered by family name or by first name (whatever the family name).
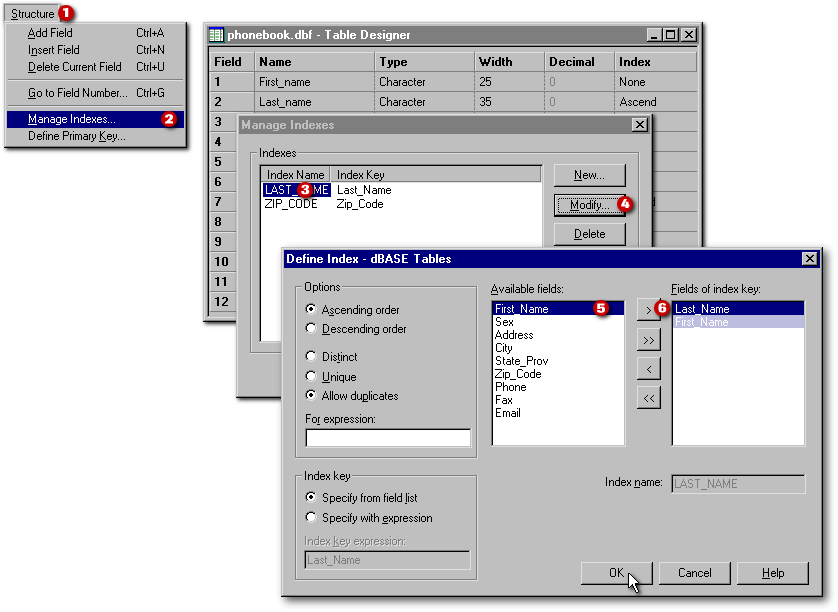
To create a complex index, we will use the (implicit) Index designer. It is available only when the Table designer is already open. When the Structure|Manage Indexes menu item is chosen, this calls the Manage Indexes dialog box. The name of an index has to be selected to enable the Modify pushbutton
In the Define Index dialog box, which appears when you click the New or Modify buttons, the Ascending order and Descending order radiobuttons are used to change the order the records are displayed in Browse windows. The Allow duplicates radiobutton allows two records to carry the same data in the indexed field (for example, it allows two people to be entered in the table when they have the same family name). The Specify from field list radiobutton is selected in the image below since we want to create an index based on two fields. They can be selected in Available fields list using the four buttons between the two lists and moved to the Fields of index key list. With the Last_Name field moved to the Fields of index key: list followed by the First_Name field, it will be possible to order our records on family name and, inside each family, to see its members ordered by their first names. In the example illustrated by the following image, when an existing index was modified, we dont have to give it a new name. If we were creating a new index, the Index name entryfield would be available in such a case, the name of a new index can be any name, even the same as an existing field. In the example illustrated below, as we click the OK pushbutton, the Index key description (beside the red dot number 3), would be replaced with Last_Name + First_Name.
The index cant be wider than 100 characters. In our example, the cumulative width of the Last_Name and First_Name fields is 70 characters. Even when that width is under the BDEs limit, dBASEs indexes will be updated faster when we avoid creating large indexes. When we finish creating a new record, as soon as we ask the table to be saved or when we want to navigate in the table (to create another new record or to consult an existing record), the indexes are updated. To optimize the speed of your applications, you could limit the number of characters taken into consideration by an index to the first 10 or 15 characters in a field. In that case, you would select the Specify with expression radiobutton: the Index key expression entryfield would then become available. In this entryfield, you would type left(Last_Name, 15) + left(First_Name, 10) Note: Do not leave any space between the word left and the opening parenthesis. Here, the left() function will select the left characters of the field. Between the parentheses, we put two parameters (sometimes referred to as arguments): the name of the field and the number of characters to be selected, separated by a comma.
The For expression entryfield, in the center, at left, allows us to create a partial index by setting a condition for being included in the index. In a partial index, only certain records of the table will be taken into consideration. For example, if TRIM(Last_Name) = "Martel" is typed into that entryfield, only the records in which the Last_Name field contains Martel will be displayed when that index is applied and the table is viewed. The trim() function is used to take out the free space at the right of a value. Without it, we would have to take under consideration the width of the Last_Name field and type Last_Name = "Martel " or Last_Name = "Martel" + space(29).
When the trim() function is used to create a partial index, that function is used only to decide which records will be indexed. No item inside the index will be trimmed and each entry in that index (each key) will have the same width: that width will be equal to the width of the field on which the index is built. It would be a huge mistake to type trim(Last_Name) + trim(First_Name) instead of left(Last_Name, 15) + left(First_Name, 10) in the Index key expression entryfield because that would create a variable width index. Since the width of the family name and of the first name change from one person to the next, the index keys wouldnt have the same width inside the index. This leads inevitably to index corruption when new records are added to the indexed table. Never, never, never should you create variable width indexes! Note: A function consists of the function name (such as left or upper) followed by opening and closing parentheses. Depending upon the function, there may be one or more parameters, separated by commas in side the parentheses. When using functions, it is important that there not be a space between the function name and the opening parenthesis.
From the
Command window, indexes can be created by any of the following means. The
upper()
command is used to set all the index keys in upper case letters. That way,
GOLDBLOOM will not be ordered differently than "Goldbloom". The command
doesnt change the data in the table. It changes only the corresponding
key in the index.
|
use "Phonebook" exclusive index on upper(Last_Name + First_Name) tag Name use // or use "Phonebook" exclusive
// or use "Phonebook" exclusive
// or Index1
= new DBFIndex()
|
|
The first line in the code above opens the table exclusively. It is impossible to modify the structure of a table (adding an index is a modification of the structure of a table) without opening that table in exclusive mode. When it is opened in that mode, no terminal connected to a network can change that table (for example, to add a record). In the second line of the code above, order on creates the index, while the tag sets the index name. The use command, with nothing else on the line, closes the table. The last example is in OODML: it works when the table is located in the current folder. It doesnt need the table to be open.
When a table is opened from the Command window, only the simple indexes, i.e., those based on one field only and carrying that fields name, will be listed in the Results pane when the F5 key (Display structure) is pressed. Conversely, when the F6 key (Display status) is pressed, all indexes, both simple and complex, will be listed.
The Field Properties
The Table designer has one floating palette known at the Properties Inspector (or the Inspector, for short). If the latter is not visible when the Table designer is already open, pushing the F11 key will make it appear. (Remember that shortcut as you will use it often.) In Object-oriented programming (OOP), we work with properties, functions and events. All these can be accessed through the Inspector.
If we open the Phonebook table and call the Table designer as if we would like to modify its structure, the Inspector will look like the image below. Near the top, its combobox displays the name of the field that is selected in the Table designer. If we open the combobox, all the fields in the table will be listed. To inspect a different field, either select another field in the Inspectors combobox or select it in the Table designer. Like any character field, the State_Prov field has four properties.
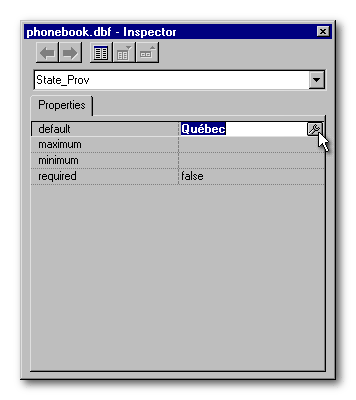
The default property sets the value that will be proposed by default to the user each time a new record is created. That value could be changed by the user or accepted as is. The maximum and minimum properties limit the data entered by the user to anything between those values. Lastly, the required property prevents the user from leaving the field if the field is left with a null value. If you try to set a required property on a table that has some records already created, the BDE will refuse to accept that property if some fields have that field empty.
The standard properties are different
for different field types.
| Type | Default | Maximum | Minimum | Required | |
| Character | ü | ü | ü | ü | |
| Numeric | ü | ü | ü | ü | |
| Memo | ü | ||||
| Logical | ü | ü | |||
| Date | ü | ü | ü | ü | |
| Float | ü | ü | ü | ü | |
| OLE | ü | ||||
| Binary | ü | ||||
| Long | ü | ü | ü | ü | |
| TimeStamp | ü | ü | ü | ü | |
| Double | ü | ü | ü | ü | |
| AutoIncrement | |||||
| _dbaselock | |||||
In the case of a Date field, if the default property is set to today, when a new record is created, that days date will appear by default. In the case of a TimeStamp field, if the default property is set to now, the exact moment a record was beginning to be created will be displayed.
But wait, there is more. A field can also have custom properties. If you right-click on the Inspector, the New Custom Field Property item can be selected in the popup menu. If you select that item, a Custom Field Property Builder dialog box will appear. In its combobox, 56 custom properties are listed for you to chose among.
Once a custom property is chosen, its value has to be set. It should be noted that you are not limited to the 56 custom properties suggested by dBASE. Any new property can be created from scratch. However, in that case, the new custom property will be just like a variable attached to that field.
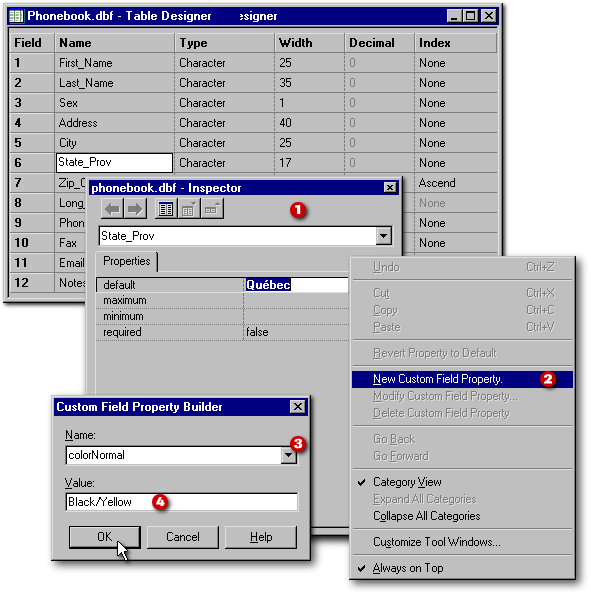
As soon as that dialog box is closed, the Inspector will display a new Custom property group in which the properties you have created will be listed. For any field, an unlimited number of custom properties can be created. In the example above, the data stored in the State_Prov field will be displayed in black text over a yellow background everywhere the Phonebook table is used. This is why any grid or browse datalinked to that table has a yellow column for that field. Any entryfield connected to that field will also be colored.
How to create a table programmatically
In the section called How to create a table, it was said that there was another way to create a table other than from the dBASE interface. This is very useful. For example, if an application requires the existence of a table to run successfully and if the user has lost that table, the application could build a new table from scratch instead of refusing to load. Moreover, when you ask for help in the dBASE newsgroups, it is often useful to provide a snippet of code showing what you are trying to achieve. Adding the code to create your table(s) on the fly makes it easier to understand your problem.
The only
way to create a table programmatically, is through SQL (Structured Query
Language). Written by IBM, SQL is now a standard that is impossible
to ignore. We will thus use SQL to create a new table called
Phonebook2.dbf,
which will be identical to our original table. But first, our code will
check if there is already a table in the folder using that name.
If there is not a table with that name, one will be created.
|
xDML: if not file('Phonebook2.dbf') // To be sure the table doesnt already exist // code to create the table endif OODML:
|
|
Use the SQL
command create table Table_name
(Field_name, SQL_type) to
create the table. The correlations between SQL and dBASE field types are
listed in the following table (where
n
is the field length
and d is
the number of decimals).
| SQL type | Visual dBASE7 / dB2K | Visual dBASE5 | |
| Character(n) | Character | Character | |
| Numeric(n,d) | Numeric | Numeric | |
| Blob(10,1) | Memo | Memo | |
| Boolean | Logical | Logical | |
| Date | Date | Date | |
| Char(n,d) | Float | | |
| Blob(10,4) | OLE | OLE | |
| Blob(10,2) | Binary | Binary | |
| Integer | Long | | |
| TimeStamp | TimeStamp | | |
| Float(n,d) | Double | Float | |
| AutoInc | AutoIncrement | | |
| (no equivalent) | _dbaselock | _dbaselock | |
Lets review the structure of our original Phonebook table.
The SQL code needed to create the
Phonebook2 table
is shown below.
|
create table Phonebook2 (; First_Name char(25),; Last_Name char(35),; Sex char(1),; Address char(40),; City char(25),; State_Prov char(17),; Zip_Code char(7),; Long_Distance boolean,; Phone char(10),; Fax char(10),; Email char(40),; Notes blob(10,1)) |
|
Then we use dBL to create the indexes.
|
xDML: use Phonebook2 exclusive index on upper(left(Last_Name, 20)) + upper(left(First_Name, 15)) tag Name index on Zip_code tag Zip_code use OODML:
|
|
Thus, the full code needed to created
the Phonebook2.dbf table
is:
|
if not _app.databases[1].tableExists('Phonebook2.dbf') // To be sure the table doesnt already exist create table Phonebook2 (;
index1
= new DBFIndex()
endif
|
In order to create a program that contains these instructions, we will use the Source editor. Use modify command to call the Source editor. This command is used both to initially create a new program and to modify an existing one. So, to create the new program entitled Phonebook2 Table Creation, we will type modify command "Phonebook2 Table Creation.prg" from the Command window. We used quotes because the program has spaces in its name. If that name didnt have any spaces, quotes would have been unnecessary. Also, the .prg extension is unnecessary. We included it here for the sake of clarity.
The do command is used to execute a dBL script (program, form, etc.). From the Command window, the command do "Phonebook2 Table Creation.prg" will run that program and create our new table programmatically.
SQL can also
be used to programmatically modify the structure of a table. For example,
to delete the Long_Distance
and
Fax fields and to add
a new 30 character field called Title,
we would use (without having to open the table):
|
Alter table "Phonebook2.dbf" drop Long_Distance, drop Fax, add Title char(30) |
|
SQL and Spaces in Field Names
It is possible
to use SQL commands on a table that has spaces in its name or spaces in its field names
as long as those names are enclosed in quotation marks. Moreover, the name of the table
(always typed between quotes) must precede the name of the fields whose names have
spaces in them (note: on the contrary, this isn't needed for the fields that don't have
spaces in their names.)
In
a nutshell
The
animated GIF is a courtesy of Ronnie MacGregor.
Visual
dBASE, dBASE and dB2K are trademarks or registered trademarks of dBASE,
Inc. Windows is a registered trademark of Microsoft Corporation.
©
2001 MGA Communications. This document can be freely reproduced as long
as its text and its illustrations are not modified without its authors
consent.
Create table "Phonebook 3" (;
"Phonebook 3"."First Name" char(25),;
"Phonebook 3"."Last Name" char(35),;
Address
char(40),;
City
char(25),;
"Phonebook 3"."State or Province" char(17),;
"Phonebook 3"."Long Distance" boolean,;
Phone
char(10),;
Notes
blob(10,1))
Alter table "Phonebook 3.dbf"
drop "Phonebook 3"."Long Distance", add "Phonebook 3"."Title Name" char(30)
I
would like to thank Flip Young, Barbara Betcher and Ivar B. Jessen, my
proof-readers, for their invaluable contribution to this article.