Introduction
I intend to teach the reader how to design relational databases. The subject is not difficult. The approach is practical. There are no prerequisites.
Readers who have studied this subject before may be surprised that the formal academic notions of normalization and normal forms have been almost completely banished from this text. This is intentional. My experience teaching database design leads me to believe that a practical approach is easier to comprehend.
Background
A logical database is a collection of facts. Your company may have a personnel database wherein facts about its employees are kept. Your company may have an inventory database where it keeps facts about the numbers and kinds of objects it owns. In a relational database these facts are kept in special tables that can be manipulated by a computer. A logical database may have several related tables. For example, a library database might have a table about books and a table about library card holders (they are related because a library card holder can check out books). Database design is deciding what facts to keep in which tables.
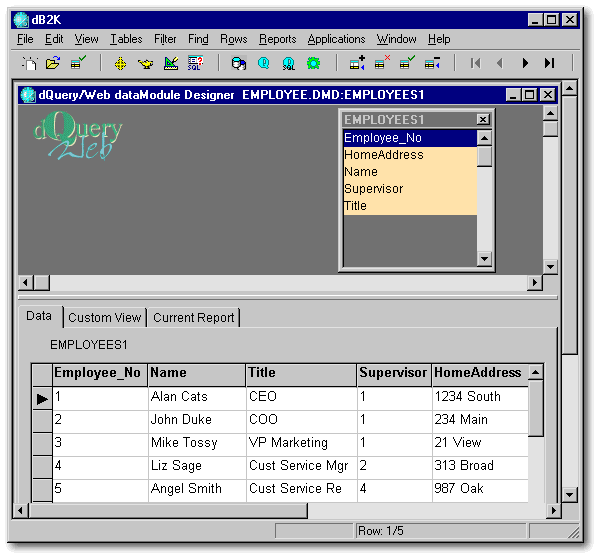
Let us start with some terminology. In Relational Database systems, like dB2K, data is stored in tables. These tables can be traditional dBASE (.DBF) files, Paradox files, or tables kept in an SQL database system like Oracle or InterBase. All dB2K (and all relational) tables consists of rows (records) and columns (fields) [1]. Here is a typical dB2K table shown in dQuery/Web.
Notice that all rows in the table have the same structure. They all have the same number of columns and the data type of a columns is the same for all rows. (Some older non-relational databases did not have this characteristic.)
A database is a collection
of tables that are used to hold the data needed for a specific purpose
or application. Thus the human resources database is the set of
tables, such as
employees,
skills, and dependents
needed to support the HR department. The sales database is the set
of tables that records sales data and probably includes tables such as
parts,
sales, customers,
and
shipments.
| Caution! |
| The word database is used inconsistently by the computer community. Not all databases are relational and non-relational databases may not use tables to store their facts. Some systems that claim to be relational aren't (which leads to some silly discussions I don't want to get into here). Some people use database as a synonym for table. Other people use database to mean a set of tables that are physically stored together but may not be related in any useful way. If someone tells you they have a database it is best to ask what they mean by database, as they may not mean what you mean. In this paper a database always means a logical relational database: a collection of one or more related tables. Please note that one table could be relational. The name relational is not related to the English language words relationship or related, but rather a formal mathematical word for table. A table is a relation. |
Normalization
Normalization is the process of deciding the appropriate place in a database to store various pieces of data. It is part of the database design process. Normalization has been the subject of much academic study. The academics have defined a series of levels of normalization, which are normally described in papers of this type. In a past life (in the 1980s) I taught database design. I have not found the academic approach to normalization useful for instructing beginners in proper database design. Instead I offer a set of practical rules and examples that will teach you how to design a well normalized database. You want well normalized tables, because they are the easiest to maintain, the easiest to query, and offer the least opportunity for inconsistencies. Let us begin:
The Rule of Nouns:This set of rules is already close to complete. Here is a useful test to see if you have designed your table well.Most tables hold facts about nouns (people, places, or things). Each row should contain information about exactly one of these people, places, or things.The Rule of the Primary Key:All tables have primary keys. A primary key is the column(s) that uniquely defines a row. For tables of nouns, it is the column(s) that uniquely distinguish that noun from every other possible noun in that table. [2]The Rule of Adjectives:Some tables have a natural primary key. The parts table probably uses the partno as its primary key. Some tables have no natural primary key, they need an artificial primary key. Every table must have a primary key - invent one if there is no natural one. This isn't as strange as it seems. Manual systems do it all the time. Employee number, serial number, and license plate number are all examples of invented primary keys. You can use the autoinc column for this purpose. Good primary keys do not change over time and are unique. For People you should invent a primary key. [3]
Except for the primary key, think of each column as an adjective. It holds descriptive information, facts, or attributes of the noun represented by the row. Every column in that row should adhere to this rule. A column must consistently hold the same attribute from row to row. (If that attribute doesn't apply, the column is null or blank.)
The Sentence Test:Let's go on to some examples to show the consequences of these rules. Then, we'll come back and give you the last two rules.Write a sentence that describes every row in the table. The resulting sentence should be simple, like Each row is an employee in our company.A complex sentence, like If the value of the type field is 'E', the row is an employee, if the value is 'D' it is an dependent, is a bad sign. You may need to redesign your tables. Does the sentence apply to every column in every possible row? It should. A sentence like, if cable_segment is false, then the length field holds the length of the total cable, if cable_segment is true, then the length field is the length of just this segment.[6], is major trouble. Your sentence should be simple, without ifs, ands, or buts.
A simple (wrong) example:

Having the names of your employee's children in the employee table is wrong. Here are three reasons:
Better would be:

The process of breaking the first table into two tables is called normalization.
So far we have a simple case of tables holding only information about people. It is fairly easy to see how this might be extended to places or things. This kind of relationship is called a one-to-many (or 1:M) relationship. It is a 1:M because each employee can have zero to many dependents and each dependent has exactly one employee. This covers most, but not all, the cases. In the previous tables we assumed all children were the dependents of exactly one employee. This might be OK or it might not. [4] Let's assume that you need to represent the possibility that a child is a dependent of two employees. We need some new rules:
The Rule of Relationships:Why relationships? Back to the employee/dependent example:Either tables hold facts about nouns or facts about relationships between nouns (Who owns which car?, Who works in which department?, Which product was shipped to which customer?)The Rule of the Primary Key for Relationships:Tables of relationships have a natural primary key. It is the primary key column(s) of both tables that are related. (Do not use the autoinc column as the primary key in a table of relationships.)The Rule of Adjectives (Amended):Except for the primary key, think of each column as an adjective. It holds descriptive information, facts, or attributes of the noun or relationship represented by the row. Every column in that row should adhere to this rule. A column must consistently hold the same attribute from row to row. (If that attribute doesn't apply, the column is null or blank.)
Best would be:

Clark has two children (John and Joanne). Gretchen has one child (Joanne) for whom she shares responsibility with Clark. (Clark and Gretchen might be married. Joanne could be the result of their current marriage. John might be from Clark's previous marriage. (The database doesn't have enough information for us to know for sure.)) Mark Jones has one child (Tom). (The database doesn't record if Mark is married or single. But we know that Tom is not recorded as a dependent of any other employee.) Mary Ann Singleton has no dependents.
This is called a many-to-many relationship (or M:M). It is M:M because, one employee can have zero to many dependents, and one dependent can have zero to many employees. (If you want to limit each dependent to at least 1 and no more than 2 employees, you'll need to do that with business rules. The database design - by itself - can't provide those limits.)
Believe it or not, you now have enough rules to properly normalize a database. However a few more examples might be in order.



Now, what are the relationships you need to track? Repair_Order and Service_Staff are related by who does the work. Since one staff member can work on more than one repair job, Repair_Order and Service_Staff must have at least a M:1 (many to one) relationship. But, do they have a M:M relationship? Probably yes. So let's design to allow it. (We can always provide business rules to prevent it. But if we design incorrectly and don't make allowances for it, there will be lots of problems later.) So let's add a relationship table. Now we have:
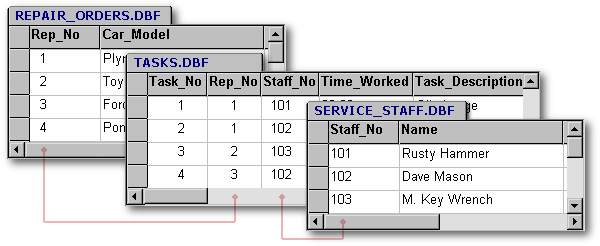
Now we have a M:M (many to many) relationship between Repair_Orders and Service_Staff, since one work order can be worked on by multiple people and each person works on multiple work orders. There is also a 1:M (one to many) relationship between Repair_Orders and Tasks, since one repair could need many tasks to be done, but one activity applies to exactly one order. Also, there is a 1:M relationship between Service_Staff and Tasks as one person does many activities, but one activity is done by only one staff member.
How about the relationship between Customers and Repair_Order? Is it 1:M? Then just add the customer's primary key to the Repair_Order table, like this:
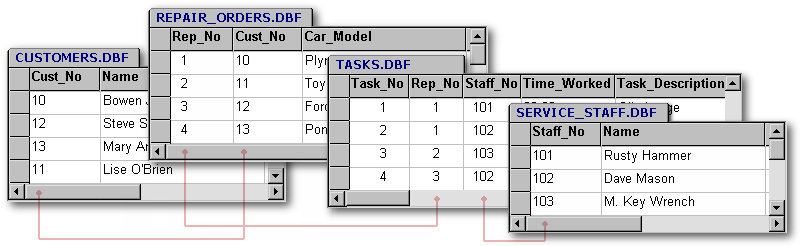
By-the-way, that linking field is technically called a foreign key. [5] A foreign key is the primary key in another table. It is how relational systems support 1:M relationships.
If you decide that there is a M:M relationship between Repair_Order and Customers (Doesn't seem likely to me, but maybe), you'll need an new table:

| Caution! |
| The phrase parent-child is sometimes used to describe a 1:M relationship. In dB2K, we frequently build applications where the 1:M relationship is expressed as a parent-child link. But, in the dB2K parent-child link, either table can be the 'parent' depending on your application needs. For this reason, I advise avoiding the term parent-child in database design within our community. Outside of this community, use caution when you hear 'parent-child' as it might be being used as a database design term! |
Example: History Table
Most databases describe the current facts of a system. They record the employees current pay. They record the current orders.
Many databases also have history
tables. These tables record facts at a specific point in time. You must
be careful about the interaction of current and history tables. Here is
an example, based on a sales system:
| Poor Design | Good Design |
Customers // Name of table |
Customers // Name of table |
The good design has more fields in OrderMaster. Why do both Customers and OrderMaster have ShipAddress? Is that correct? ShipAddress is already in the customer table and it is an attributes of the customer, isn't it? Well not really, and here is the trick of history tables. The ShipAddress in the customer table is the current address. The ShipAddress in the OrderHistory is the historical address copied from the customer table at the time of the order. Here is why that might be important:
Example: Validation
Let us go back to the very first example.
How can we ensure that we have high quality and consistent data? One technique is to use a validation table. For example, how can we be sure that only valid titles are entered into the employees.title field? You might build your data entry forms with a nice little pull down so that the user can just select from the valid titles. Make your pull down data driven using a validation table like this:

Validation tables of this form are similar to tables of nouns. However, they are so abbreviated and simplified that they are not true tables of nouns. In the example of the EmployeeTitleValidation table above, notice that title is not a true noun. There is no person, place, or thing that is a title. The EmployeeTitleValidation table is just a list of valid adjectives that can be applied to the employees.title field.
The Rule of Validation:When a Validation Table becomes a Table of NounsValidation tables can be useful to insure data consistency. Validation tables should have a single column which is the the list of valid values. The primary key of the validation table is that single column.
Please note that if you have a business or application need to store more than just validation information, you have a true table of nouns and not just a validation table. For example, your EmployeeTitleValidation table might grow to include salary information. Then you have a new table of nouns called jobs:
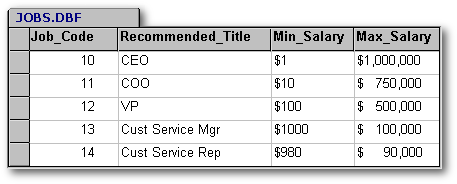
You need to modify the employees table as shown:

A comment about the title field: Depending upon the rules of the organization that you are modeling, title might be an adjective of the job or of the employee. If it is an adjective of the job, then my example is incorrect and the title field should be in the job table. In this example I have assumed that title is an adjective of the employee and therefore I show the title as a column of the employee table. See employees 1 and 3 for examples of why the employee's title might not match the job's recommend title. The proper location for columns frequently depends on the rules of the business (or organization).
Please think about companies that you've worked for. What are their rules regarding titles? What design should you use to implement those rules? One advantage for the design that I've shown is that it closely models my personal experience in how US companies really operate. This design is more flexible than one that requires an employee carry the title of their job. You can always make a flexible design more rigid with business rules. Inflexible designs, however, are simply inflexible. Business rules are easier to change than database designs. Systems tend to be in service for a long time. Business condition are likely to change during the service life of each system that you design. When possible, design your databases to be flexible and enforce your rigidity with business rules.
Counter Example: Encoding
Some people assert that the previous validation example is wrong. They claim that for proper normalization values like title should not be stored directly in the employees table. Those people claim that title should be stored in a linked table like this:

With the employees table as shown:
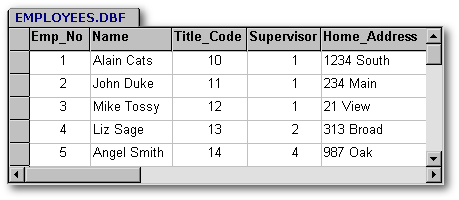
But, this is a case of encoding - not normalization. How can you tell? Notice that there is no more information here than in the validation example. Encoding can reduce the size of a database, but has the disadvantage of requiring a join every time you wish to display a human readable title. In most cases recommend validation tables over encoding.
Summary
In summary, a good database design will improve the performance of your system by making each I/O more productive and by reducing wasted space. It also makes querying the database easier. Although we didn't show examples here, it can also reduce the amount of duplicate and potentially conflicting data. The rules for designing databases are really straight forward. Here they are in final form:
The Rule of Nouns:Most tables hold facts about nouns (people, places, or things). Each row should contain information about exactly one of these people, places, or things.The Rule of Relationships:Either tables hold facts about nouns or facts about relationships between nouns (Who owns which car?, Who works in which department?, Which product was shipped to which customer?)The Rule of the Primary Key:All tables have primary keys. A primary key is the column(s) that uniquely defines a row. It is the column(s) that uniquely distinguishes that noun from every other possible noun in that table.The Rule of Adjectives:Some tables of nouns have a natural primary key. Many tables of nouns have no natural primary key, they need an artificial primary key. Every table must have a primary key - invent one if there is no natural one. You can use the autoinc column for this purpose. Good primary keys do not change over time and are unique. For People you should invent a primary key. [3]
Tables of relationships have a natural primary key. It is the primary key column(s) of both tables that are related. (Do not use the autoinc column as the primary key in a table of relationships.)
Except for the primary key, think of each column as an adjective. It holds descriptive information, facts, or attributes of the noun or relationship represented by the row. Every column in that row should adhere to this rule. A column must consistently hold the same attribute from row to row. (If that attribute doesn't apply, the column is null or blank.)The Rule of Validation:Validation tables can be useful to insure data consistency. Validation tables should have a single column which is the the list of valid values. The primary key of the validation table is that single column.The Sentence Test:Write a sentence that describes every row in the table. The resulting sentence should be simple, like Each row is an employee in our company.A complex sentence, like If the value of the type field is 'E', the row is an employee, if the value is 'D' it is an dependent, is a bad sign. You may need to redesign your tables. Does the sentence apply to every column in every possible row? It should. A sentence like, if cable_segment is false, then the length field holds the length of the total cable, if cable_segment is true, then the length field is the length of just this segment.[6], is major trouble. Your sentence should be simple, without ifs, ands, or buts.