Une table est un recueil structuré d'informations. Pour simplifier la discussion, on peut considérer une table comme un tableau électronique où chaque cas occupe une rangée et chacune de ses caractéristiques est inscrite dans la colonne appropriée. Dans le jargon dBASE, chaque rangée est une fiche (row en anglais) alors que chaque colonne est appelée un champ (field en anglais).
Si vous êtes néophyte, avant de commencer à créer vos propres tables dBASE, non seulement je vous inviterais à lire le texte qui suit, mais également le texte consacré aux principes de création des bases de données («Conception des bases de données et Normalisation» de M. Mike Tossy). La lecture de ce dernier texte pourrait vous éviter bien des erreurs dans la conception de vos tables.
La véritable nature d'une table
Se représenter une table dBASE comme un tableau électronique est un concept intéressant mais il s'agit d'une vue de l'esprit. N'importe quel fichier d'ordinateur est une longue suite de valeurs binaires déposées les unes à la suite des autres dans des unités d'allocation parfois consécutives, souvent dispersées un peu partout sur une même partition.
Les tables dBASE nous apparaissent comme une succession de fiches individuelles ou comme des tableaux parce que dBASE nous affiche de cette manière les données que renferment ses tables. En réalité, celles-ci sont une longue suite de zéros et de uns, comme n'importe quel fichier d'ordinateur.
Pour l'utilisateur, la partie utile d'une table est formée des données qu'elle renferme. Pas pour dBASE : vos données ne lui disent absolument rien. Pour lui, la partie utile d'une table (et la seule partie qu'il comprend) est son entête. Celle-ci se trouve au début du fichier d'une table, d'où son nom. Dans celle-ci, dBASE trouve une foule d'informations, dont le nombre de fiches qu'elle contient, la taille de l'entête (qui varie selon le nombre de champs), la taille de chaque fiche, etc.
Lorsque vous demandez à dBASE de vous afficher la millième fiche d'une table, le logiciel prend note de la taille de l'entête, puis multiplie par 999 la taille de chaque fiche, prévoit (si ma mémoire est bonne) un octet séparateur entre chaque fiche et saute X octets plus loin, exactement à la millième fiche.
C'est ce qui fait la force des tables dBASE ; la taille fixe de chaque fiche d'une même table. Si dBASE devait lire la longue suite de valeurs binaires pour savoir où se termine une fiche et où commence la suivante, le logiciel aurait la même vitesse qu'un traitement de texte recherchant un mot. Sur un texte de quelques pages seulement, une telle vitesse est acceptable : si la taille du texte est de plusieurs mégaoctets, la recherche d'un mot peut prendre beaucoup de temps. À l'opposé, lorsque dBASE reçoit l'ordre d'aller, par exemple, à la millionième fiche, il y accède instantanément.
Même lorsque vous désirez obtenir une information (ex. : l'adresse de monsieur Untel), sans savoir où se trouve cette information dans la table, dBASE fait preuve d'efficacité. Sans index, il procède alors par bonds d'une fiche à l'autre, accédant directement et très exactement à chaque nom de famille, jusqu'à ce qu'il trouve «Untel». dBASE n'a aucune idée de ce que signifie «Untel», ni même de ce qu'on entend par «nom de famille». Tout ce qu'il sait, c'est que son entête lui dit d'aller à tel endroit très précis de la table pour y trouver l'information exigée ou à défaut, à X octets plus loin, et ainsi de suite.
À ce titre, dBASE est une formidable machine à trouver et à traiter l'information.
Le niveau et la langue des tables
Le BDE
Aussi curieux que cela puisse paraître, toutes les versions de dBASE fonctionnant sous Windows sont incapables d'accéder directement aux tables dBASE. Elles le font par l'intermédiaire du Moteur de base de données Borland (BDE). Ceci s'explique par des raisons historiques. À la fin des années '80, au hasard des acquisitions, l'éditeur Borland s'est retrouvé propriétaire de deux gestionnaires de base de données, dBASE et Paradox. Plutôt que maintenir leurs moteurs respectifs d'accès aux données, Borland eut l'idée de développer un moteur commun, pouvant servir également à tous les logiciels Borland : ce fut le BDE. Plusieurs années plus tard, quand dBASE fut cédé à son propriétaire actuel, ce dernier se retrouve avec un produit-vedette qui dépend stratégiquement d'une technologie étrangère pour effectuer des tâches qui lui sont essentielles.
Le niveau d'une table
Ceci explique également que vous deviez passez par le BDE pour changer le niveau des tables qui seront créées par dBASE. À moins que sa structure ne soit modifiée, une table conserve toujours le même niveau. Lorsqu'on change le niveau des tables dBASE dans le BDE, on ne fait qu'établir le niveau des tables qui seront créées par la suite. Cela ne change rien à l'aptitude du BDE de lire n'importe quel type de table dBASE. Grâce au BDE, une même application écrite en dBL peut glaner des données simultanément dans des tables dBASE de différent niveaux.
Mais qu'est-ce que niveau d'une table ? À toutes fins pratiques, c'est sa version. Les tables dBASE appartiennent à un standard qui a évolué avec le temps. Lorsqu'une nouvelle version de dBASE apportait des améliorations au format des tables dBASE, on attribuait à ce nouveau format un numéro de niveau identique à celui de la version de dBASE. Par exemple, on a des niveaux 3, 4, 5 et 7 correspondant à dBASE-III, dBASE-IV, dBASE 5 et Visual dBASE 7. Il n'y a pas de niveau 6 parce qu'il n'y a jamais eu de version 6 de Visual dBASE.
Le niveau 7 possède, en comparaison avec les niveaux inférieurs, de nombreux avantages. Parmi ceux-ci, retenons que le nom des champs peut avoir jusqu'à 31 caractères (au lieu de dix). De plus, de nouveaux types de champs sont apparus (dont de type AutoIncrement, ce qui rend impossible l'attribution d'un même numéro à deux fiches d'une même table). Si d'autres logiciels ont à utiliser vos tables dBASE, il vous faudra toutefois sacrifier ces avantages au profit de la compatibilité, et créer par défaut des tables dont le niveau est inférieur à 7, ces dernières n'étant reconnues que par peu d'applications pour l'instant.
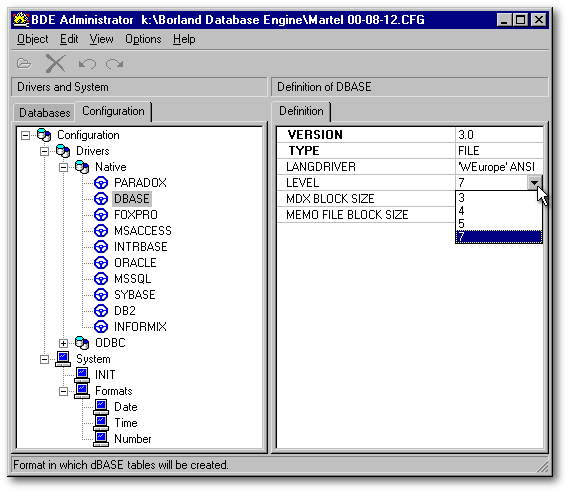
On établit le niveau par défaut des tables qui seront créées par dBASE, par l'intermédiaire de l'administrateur du BDE. À partir du menu Démarrer de Windows, on choisit Démarrer|Paramètres|Panneau de configuration et on double clique l'icône BDE Administrator.
Dans le panneau de gauche de l'administrateur du BDE, on choisit l'onglet Configuration, puis on ouvre l'arborescence jusqu'à révéler le gestionnaire des tables dBASE. En anglais, «Gestionnaire de table» s'écrit Table driver. Littéralement, cela se traduit par «Pilote de table» : cela explique pourquoi des icônes en forme de volants automobiles représentent les différents «pilotes» dans l'image ci-après.
Dans le panneau de droite, cliquez à droite de Level pour rendre visible le bouton qui donne accès à la liste déroulante, puis choisissez le niveau approprié.
La langue d'une table
À la ligne au-dessus de Level, se trouve le gestionnaire de langue (LangDriver) : c'est lui qui détermine comment seront indexés les fiches d'une table, en particulier l'ordre et la préséance des caractères accentués. Personnellement j'utilise 'WEurope' ANSI. Celui-ci classe les voyelles dans l'ordre suivant : a A á Á à À â Â å Å ä Ä ã Ã.
De manière générale, c'est le gestionnaire de langue recommandé par le support technique de dBASE Inc. Il cause toutefois des problèmes chez les peuples germaniques en ce qui regarde les trémas puisque les caractères qui en portent sont classés en allemand de manière différente qu'en français. Les Danois quant à eux classent les mots débutant par AA, Aa, aA et aa, à la fin de l'alphabet : ils choisiront donc le gestionnaire 'Borland DAN Latin-1' (il n'apparaît pas dans la liste des gestionnaires mais le BDE accepte ce nom lorsqu'il est dactylographié dans la boîte de saisie LangDriver).
Sous System|INIT, au bas
du panneau de gauche, on peut également choisir un gestionnaire
de langue. Je vous avoue que je n'ai pas réussi à savoir,
à partir de la documentation du BDE, à quoi sert cette inscription.
Je présume qu'il est préférable que ce gestionnaire
soit le même que pour le gestionnaire des tables dBASE. Dans la section
System|INIT,
assurez-vous également que le BDE crée par défaut
des tables dBASE et non Paradox (à l'item Default Driver).
Note : Puisque nous sommes dans la section System|INIT du BDE, signalons
que certains experts estiment que les valeurs par défaut de cette
section sont très conservatrices pour les ordinateurs d'aujourd'hui.
Par exemple, Monsieur Daniel Howard [dBVIPS] révélait le
30 juin 2000 les valeurs qu'il utilisait alors :
| Item du BDE |
|
|
|
| MaxBufferSize |
|
|
|
| MaxFileHandles |
|
|
|
| MemSize |
|
|
|
| SharedMemSize |
|
|
|
Sa suggestion est d'établir MemSize à une valeur minimale de 16, ou à un quart de la mémoire vive de votre ordinateur. On choisira la plus grande valeur entre les deux.
Une fois que vous avez déterminé le niveau et le gestionnaire de langue, quittez le BDE. Si vous avez effectué des changements, vous rencontrerez deux boîtes de dialogue : la première vous invitant à confirmer les changements effectués, la seconde pour vous aviser que ces changements ne prendront effet qu'au prochain chargement des applications qui dépendent du BDE.
Si le changement de gestionnaire de langue affecte la manière avec laquelle les caractères accentués s'affichent dans votre Éditeur de code, c'est qu'aucun gestionnaire de langue n'est précisé dans le fichier .ini de dBASE. Lorsque c'est le cas, dBASE utilise par défaut le gestionnaire de langue du BDE.
Afin de restreindre la portée du BDE aux seules tables et éviter qu'un changement de gestionnaire de langue affecte l'exécution de vos programmes (en particulier si vous utilisez des caractères accentués dans vos noms de champs), chargez le fichier vdb.ini ou db2k.ini dans un éditeur de texte (par exemple, Notepad). Ce fichier est situé dans le sous-répertoire \BIN du répertoire dans lequel vous avez installé Visual dBASE ou dB2K. À la section [CommandSettings], ajoutez la ligne LDriver=Windows. Puisque nous ne sommes pas encore rendus à l'étape de créer des programmes, je vous inviterais à vérifier immédiatement si ce fichier .ini contient bien cette ligne, sinon ajoutez-là. Vous vous éviterez ainsi bien des problèmes.
Détermination du niveau et de la langue
Une fois une table créée, il est impossible de modifier sa langue. Par contre, on changera son niveau si l'on altère sa structure alors que le niveau courant a été modifié entre-temps. Cela signifie que si vous développez des applications pour le marché international, vous pourriez créer des tables ayant un gestionnaire de langue adapté à chaque marché. Lorsque la table est ouverte, ses données seront lues et enregistrées conformément à son gestionnaire de langue spécifique, et non selon le gestionnaire de langue courant.
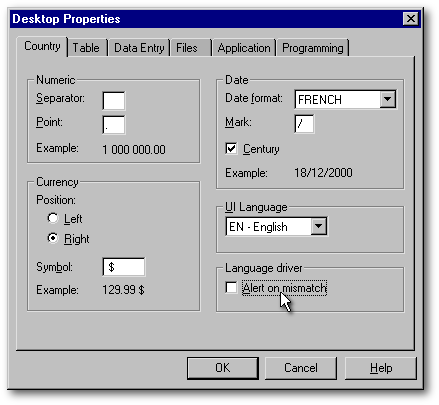
Dans le but d'éviter que dBASE ne vous signale un message d'erreur lorsque vous ouvrez une table dont la langue est différente de celle du gestionnaire de langue courant, choisissez l'item Properties|Desktop Properties du menu : sous l'onglet Country, assurez-vous que la boîte à cocher Alert on mismatch, en bas, à droite, n'est pas cochée. On obtient le même résultat en tapant set LDcheck off dans la Fenêtre de commande (note : on peut aussi ajouter cette ligne au code dBL des programmes que vous créez pour vos clients).
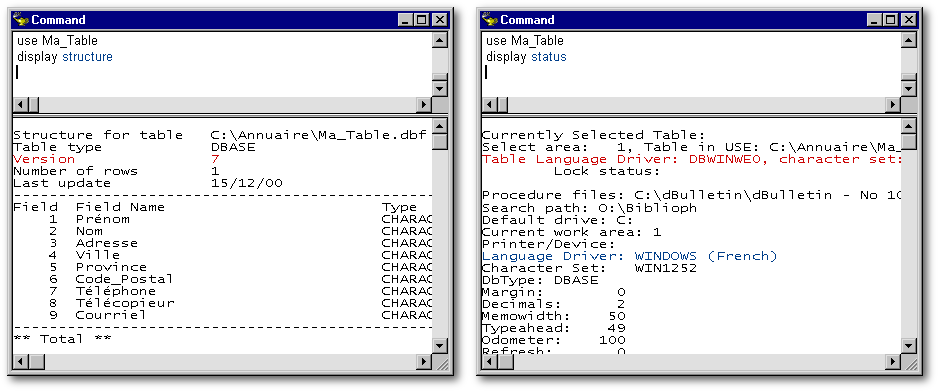
Lorsqu'on désire savoir quel est le gestionnaire de langue courant sans avoir à ouvrir le BDE, il suffit d'appuyer sur la touche F6 : dans le panneau des résultats, à la ligne débutant par Language Driver, vous obtiendrez le nom du gestionnaire de langue courant (note : nous avons coloré cette ligne en bleu dans l'image ci-desous, à droite). Si vous y voyez quelque chose ressemblant à DBWINWEO ('WEurope' ANSI) plutôt que WINDOWS (L) où L est une langue c'est que votre fichier vdb.ini ou db2k.ini ne contient pas la ligne LDriver=Windows à la section [CommandSettings]. Quant au niveau par défaut, il faut créer une table pour le savoir sans passer par l'Administrateur du BDE.
Justement, pour connaître le niveau d'une table, il suffit d'ouvrir la table à l'aide de la commande use "Ma_Table" tapée dans la Fenêtre de commande et d'appuyer sur la touche F5. On remplacera ici "Ma_Table" par le nom de la table en question. Il est à noter que les guillemets ne sont essentiels que si le nom de la table renferme un espace.
Pour obtenir son gestionnaire de langue, on appuiera plutôt sur F6 (ci-dessous à droite, en rouge, à la ligne Table Language Driver, qu'il ne faut pas confondre avec la ligne Language Driver qui donne plutôt le nom du gestionnaire de langue courant). Il suffit de taper use (avec rien d'autre) pour refermer la table.
Les limites du BDE
Jusqu'à 512 tables dBASE peuvent être ouvertes simultanément sur un même ordinateur. Théoriquement, chaque table dBASE de niveau 7 peut contenir jusqu'à un milliard de fiches. Dans les faits, la taille d'une table ne peut dépasser deux gigaoctets : c'est donc cette taille qui constitue la limite véritable des tables dBASE quant au nombre de fiches. Chaque fiche peut contenir jusqu'à 1024 champs. Le nom des champs est limité à 31 caractères. Un champ textuel peut contenir jusqu'à 254 caractères (lettres et/ou chiffres) tandis qu'un champ mémo est illimité.
Le fichier d'index d'une table porte généralement le même nom que le .dbf, sauf que son suffixe est .mdx (pour Multiple Indexes). Comme les lettres de ce suffixe le suggèrent, chacun de ses fichiers peut contenir plusieurs index. La limite est fixé à 47. Malgré le fait qu'on peut créer un nombre illimité de fichiers .mdx secondaires (sous d'autres noms), nous ne vous encourageons pas à le faire puisque le dBL ne gère pas les fichiers d'index possédant un nom différent de celui de la table.
Si un fichier d'index peut donc contenir 47 index, un seul de ces index sera actif à la fois : on peut passer de l'un à l'autre à tout moment. De plus, la largeur d'un index ne peut dépasser cent caractères. La formule pour le créer (index on ) ne peut avoir plus de 220 caractères.
Le BDE peut répondre aux requêtes simultanées d'un maximum de 48 exécutables. Concrètement, sur un site Web, si le BDE met en moyenne trois millièmes de seconde à répondre à une requête, des milliers de personnes peuvent consulter un site mais seuls 48 d'entre eux peuvent obtenir de l'information contenue dans des tables dBASE au cours d'un même instant de trois millièmes de seconde. En se basant sur une telle moyenne, un site Web alimenté par dBASE pourrait répondre à un peu plus de 21 milliards de requêtes adressées au BDE. À l'opposé, si le serveur met en moyenne trois secondes (ce qui est douteux), cette limite tombe à 21 millions de requêtes par an. Au-delà de cette limite, vous devrez vous résoudre à vous procurer un deuxième serveur pour alimenter ce site
Comment créer une table ?
Il y a deux manières de créer une table : par le biais de l'interface de dBASE, ou par programmation. L'interface de dBASE offre plusieurs moyens de créer une table :
Évitez d'utiliser des espaces dans le nom de vos tables. Non seulement cela vous évitera de toujours avoir à placer le nom de vos tables entre guillemets, mais vous devez également savoir que les commandes SQL (nous en reparlerons) refuseront de s'exétuter sur des tables dont le nom renferme un ou plusieurs espaces.
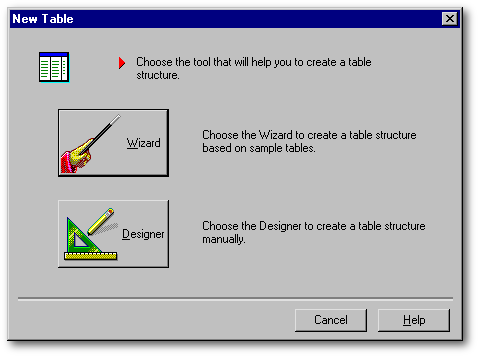
L'Assistant du Concepteur de table
Nous allons faire un bref détour par cet Assistant pour en saisir le fonctionnement. Il possède deux étapes. La première est représentée par la fenêtre suivante. À gauche, dBASE vous offre une liste de gabarits : table-type d'une galerie d'Art, table-type d'un service de facturation, etc. Dès que l'une d'entre elles est choisie, au centre, une liste de champs suggérés apparaît. À cette étape-ci, on ne peut modifier le nom des champs, ni en ajouter de nouveaux : cela sera possible un peu plus loin. À l'aide des boutons, on déplace les items de la liste des choix possibles, au centre, à la liste des choix effectués, à droite. Dès que des champs sont sélectionnés, le bouton Next (ce qui signifie «Suivant») devient disponible. Ce dernier permet d'aller à la dernière étape de l'Assistant du Concepteur de table.
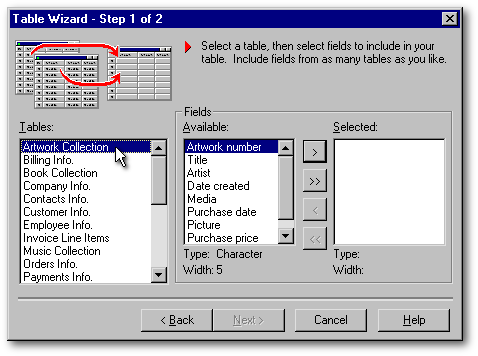
La dernière étape à franchir est simple. En haut, une liste déroulante permet de créer une table de format dBASE, FoxPro ou Paradox. Au dessous, deux gros boutons vous offrent le choix entre d'une part, sauvegarder votre table et finalement la voir vide (ce qui est dépourvu d'intérêt), ou d'autre part charger la table que l'on vient de créer dans le Concepteur de table afin de la fignoler (c'est à dire modifier sa structure renommer des champs, modifier leur type ou leur taille, créer des index, etc.). C'est dans ce sens que cet Assistant porte bien son nom puisqu'il vous permet d'atteindre finalement le Concepteur de table proprement dit avec le gros de l'ouvrage déjà accompli.
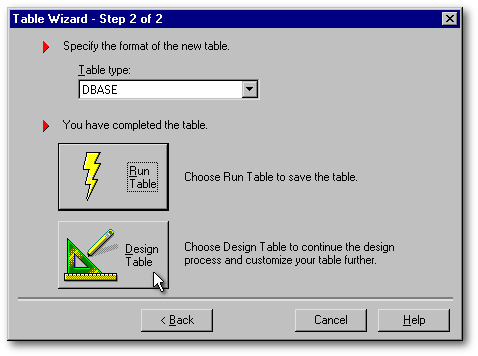
Le Concepteur de table proprement dit
Abandonnons, si vous le voulez bien, ce que nous avons fait à l'aide de cet Assistant et revenons en arrière, au moment où il fallait choisir entre l'Assistant du Concepteur de table et le Concepteur proprement dit. Puisque c'est en forgeant qu'on devient forgeron, je vous invite à utiliser le Concepteur de table (en appuyant sur le bouton Designer ci-dessous) afin d'effectuer un petit exercice : nous allons créer un annuaire téléphonique.
À l'ouverture, le Concepteur de table se présente comme un tableau (voir l'image un peu plus bas). La colonne Field indique le numéro du champ. Il est à noter que les champs d'une table dBASE ne porte pas véritablement de numéro. Cette numérotation n'est ici qu'une commodité dont on tire profit avec le raccourci Ctrlg qui sert à déplacer le curseur à un numéro de champ particulier.
Lorsqu'on crée une base de données, on a souvent besoin de connaître le nom et la taille de champs situés dans différentes tables. À cause du faible encombrement du Concepteur de table, on peut consulter la structure de différentes tables, à l'aide de plusieurs instances du Concepteur de table ouvertes simultanément.
Les principes de création d'un champ sont simples. Le champ devrait contenir la plus petite unité possible de donnée cohérente. On évitera d'inscrire le prénom et le nom dans le même champ. Ni à la fois la ville et la province ou l'état. Par contre, on pourrait y inscrire l'adresse même si celle-ci se compose du numéro civique, un nom de rue et possiblement un numéro d'appartement, puisqu'il est douteux que vous ayez à analyser n'importe quelle de ces informations séparément. Si ce devait être le cas, il faudrait lui attribuer un champ qui lui soit propre.
Si cette table doit faire partie d'une base de données, elle devrait avoir un champ unique (c'est-à-dire sans doublon) qui lui permet d'être liée à une autre table par un champ identique. À l'opposé, l'information dans une table ne devrait pas faire duplication inutilement au sein d'une même base de données.
Nommer un champ
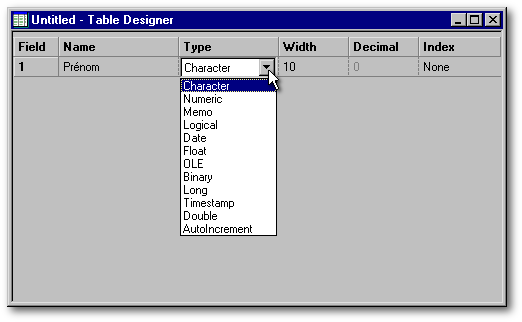
C'est dans la colonne Name qu'on inscrit le nom du champ que l'on veut créer. Tapez-y «Prénom». S'il vous est impossible d'y entrer des minuscules, c'est que vous êtes en train de créer une table de niveau inférieur à 7. Si tel est le cas, ne sauvegardez rien, quittez dBASE et allez à l'Administrateur du BDE pour y changer le niveau par défaut des tables créées par le BDE, puis rechargez dBASE.
Sous Visual dBASE 5, le nom d'un champ était limité à 10 espaces, ne devait pas renfermer d'espace (on utilisait le souligné à la place) et devait débuter par une lettre. Depuis Visual dBASE 7, le nom des champs peut avoir jusqu'à 32 caractères, contenir des espaces et débuter par à peu près n'importe quoi. Ceci étant dit, je ne vous recommande pas de débuter le nom d'un champ par un chiffre, ni de choisir un nom de champ comportant un espace à moins d'avoir la certitude que jamais vous n'utiliserez le SQL (un langage de gestion de base de données reconnu en bonne partie par le BDE). Une commande SQL comme alter table 'Ma Table' drop 'Mon champ' ne fonctionne pas à cause de l'espace dans le nom du champ. Il faudra plutôt écrire : alter table 'Ma Table' drop Ma_Table.'Mon champ'. Pour terminer, si le nom de la table renferme un espace, il sera impossible de recourir au SQL pour effectuer des opérations sur cette table. C'est pourquoi, dans le présent texte, nous éviterons les espaces dans les noms de table (et de champ, pour des raisons de facilité).
Les types de champ
Lorsque votre premier champ aura été nommé, passez à la case suivante en appuyant sur la touche de tabulation, sur Entrée, ou en cliquant sur cette case. Celle-ci se transformera alors en liste déroulante. Cette liste vous permet de choisir parmi les douze sortes de champs que peut renfermer une table dBASE de niveau 7. Dans le cas du champ «Prénom», c'est évidemment un champ textuel que l'on souhaite créer : on choisira donc Character. Si vous le voulez bien, faisons ici une petite pause pour parler des différents types de champ.
Une table dBASE peut renfermer plusieurs types de données : du texte, des nombres, des images, des fichiers sonores et des objets OLE (Object Linking and Embedding). À cause de cette variété, dBASE possède une grande variété de types de champs afin de répondre aux besoins des développeurs.
Bref rappel : toutes les données informatiques sont constituées de valeurs que l'on qualifie de binaires parce qu'elles ne peuvent avoir que deux valeurs (zéro ou un). Chacune de ces valeurs binaires forme un bit d'information. Ces bits sont habituellement regroupés par huit bits pour former un octet (ou byte en anglais). Lorsqu'un fichier renferme des octets correspondant non seulement aux lettres, chiffres et signes de ponctuation qu'on retrouve sur un clavier, mais également aux caractères non imprimables parmi les 256 possibilités d'un octet, ce fichier est dit «binaire». Le fichier d'un texte créé à l'aide de Notepad est toujours un fichier textuel alors que le même texte créé avec Word ou Wordpad est un fichier binaire (qui n'est lu correctement que par les applications dotées d'un filtre d'importation). De manière analogue, un champ binaire est conçu pour recevoir n'importe quelle combinaison parmi les 256 possibilités d'un octet.
La taille du champCharacter
Il s'agit des champs textuels, soit les plus utilisés. Ils peuvent contenir jusqu'à 254 lettres, chiffres ou signes de ponctuation. Non seulement peut-on y mélanger des lettres et des chiffres, mais on s'en sert pour stocker des nombres que l'on désire indexer. La raison en est que les index basés sur des champs Numeric sont sujets à la corruption alors que cela ne se produit jamais en temps normal avec des index basés sur des champs textuels.
Numeric
Au sens large du terme, dBASE possède cinq types de champ ne pouvant contenir que des chiffres : Numeric, Float, Long, Double et AutoIncrement. Ces champs servent à stocker des nombres qui seront l'objet de calculs.En réalité, les champs Numeric sont des champs textuels tarés. D'abord, la taille d'un champ Numeric est limité à 20 (incluant les décimales). De plus, alors qu'un octet de champ Character peut avoir 256 valeurs possibles (soit le nombre de caractères d'une table ANSI ou ASCII), un octet de champ Numeric n'a que treize valeurs possibles (un nombre de 0 à 9, un point, un signe négatif ou une valeur nulle).
La valeur d'un champ Numeric est stockée sous forme de texte justifié à droite. Lorsque dBASE a besoin de la valeur stockée dans un champ Numeric, il la transforme à la volée en nombre. C'est donc à dire que les opérations mathématiques effectuées sur des champs Numeric prennent plus de temps que les mêmes opérations effectuées sur des champs binaires (Long ou Double).
Memo
De taille illimitée, le champ mémo sert habituellement à stocker des textes de dimension importante. Pourtant, il occupe 10 octets dans la table proprement dite. L'explication est la suivante ; dBASE ne fait qu'inscrire un pointeur dans le champ mémo d'une table, le texte lui-même étant stocké dans un fichier .dbt portant le même préfixe que la table (par exemple Ma_Table.dbt pour la table appelée Ma_Table.dbf). Ce pointeur sert à indiquer précisément l'endroit où le texte se trouve dans le fichier .dbt.Les champs mémo peuvent contenir des marqueurs HTML qui permettent de formater le document qu'ils contiennent ; caractères gras, italiques, insertion d'image, etc. Dans ce dernier cas, l'image n'est pas stockée dans le fichier .dbt : le texte du champ mémo ne contient qu'un marqueur HTML indiquant le nom de l'image et l'endroit du disque où elle se trouve conservée.
Les versions à 16 bits du BDE (celles utilisées avec Visual dBASE 5.x) causent à l'occasion une corruption inexpliquée qui gonfle substantiellement la taille des fichiers .dbt. Ce bogue semble avoir été corrigé avec les versions à 32 bits du BDE (celles utilisées par Visual dBASE et dB2K) puisqu'aucun cas semblable n'a été rapporté jusqu'à maintenant.
Logical
La taille des champs logiques est limitée à un espace puisque leur valeur ne peut être que T (pour True, ce qui signifie «Vrai») ou F (pour False qui signifie «Faux»). À la saisie des données, un contrôle connecté à un champ logique acceptera aussi Y (pour Yes) ou N (pour No) qui seront transformés respectivement à l'interne en T ou F.On ne peut pas indexer les valeurs d'un champ logique. L'indexation est toutefois possible lorsqu'on transforme la valeur du champ logique en valeur textuelle, comme nous le verrons plus loin.
Date
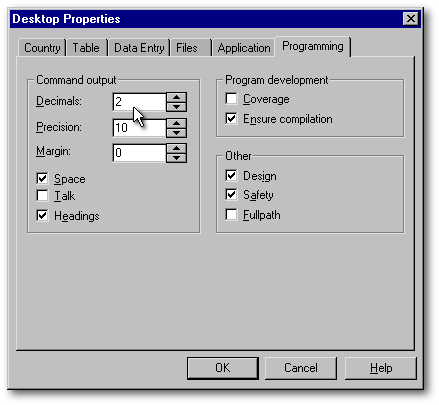
Les champs de type date sont des champs textuels spéciaux : ils ont une taille fixe de 8 octets et servent, comme leur nom l'indique, à stocker les dates. Quatre octets servent à noter l'année, deux autres le mois, et les deux derniers le jour. Même si les dates sont stockées dans le format 'année-mois-jour', les dates s'affichent toujours selon le format précisé dans le vdb.ini ou le db2k.ini. On peut changer le format d'affichage à l'aide de la commande set date (par exemple, set date YMD ou set date French) ou par le biais de la boîte de dialogue Desktop Properties (voir dans coin supérieur droit de l'illustration de la section «Détermination de la langue»).
Float
Autrefois, il s'agissait d'un champ spécialisé dans le stockage des nombres à virgule flottante (c'est-à-dire dont le nombre de décimales varie). Il correspond au type double sous Visual dBASE7 et dB2K. Ces derniers n'ont de champ Foat qu'afin d'assurer la compatibilité avec les anciennes versions de dBASE. Sous Visual dBASE7 et dB2K, le champ float n'est qu'un champ textuel dont la taille est limitée à 20 octets (incluant les décimales). Il peut contenir des valeurs positives ou négatives.
OLE
Le champ OLE permet de stocker des objets OLE provenant d'autres applications Windows. Dans la table proprement dite, le champ OLE n'occupe que dix octets et ne contient qu'un pointeur indiquant le lieu précis où l'objet OLE est stocké dans le fichier .dbt qui accompagne le table.
Binary
On se sert de ces champs lorsqu'on désire conserver des fichiers binaires (des sons et des images, par exemple) dans une table. N'occupant que dix octets, le champ Binary ne stocke pas le fichier binaire dans le fichier .dbf ; ce champ renferme plutôt un pointeur indiquant l'endroit précis où le son ou l'image est stocké dans le fichier .dbt qui accompagne la table. Il n'y a pas de limite quant à la taille d'un fichier binaire pouvant être stocké dans un fichier .dbt, si ce n'est la limite de deux giga octets imposée à une table dBASE.
Long
Le champ Long est apparu avec Visual dBASE 7. Il s'agit d'un champ binaire possédant une taille fixe de quatre octets. dBASE ne cherche pas à savoir à quelle est la valeur de chaque octet individuellement (par exemple à quel caractère d'une table ANSI cet octet correspond) mais traîte ces 32 bits comme un seul bloc pouvant avoir 232 (4 294 967 296) valeurs possibles. C'est parce que le champ Long s'interprète comme un bloc de 32 bits de large plutôt que comme quatre items de 8 bits qu'on le qualifie de «long».Il peut contenir n'importe quel nombre entier entre - 2 147 483 647 et + 2 147 483 647. Si vous faites le total, il semble manquer deux valeurs possibles : ce sont le zéro et la valeur nulle. Un champ Long ne peut pas contenir de décimale. Pour le bénéfice de ceux qui veulent tout savoir, des 32 bits d'un champ Long, le premier sert à indiquer le signe ; 0 = négatif, tandis que 1 = positif.
Lorsqu'une table principale renferme un champ AutoIncrement et que l'on doive lier cette table principale à une table-fille, une des meilleures manières d'y parvenir est en créant un lien entre son champ AutoIncrement et un champ Long indexé dans cette table-fille.
Timestamp
Timestamp signifie «estampille à temps». Ces champs sont une nouveauté de Visual dBASE 7. Ils ont une taille fixe de huit octets et servent à stocker la date et le temps d'un instant précis (note : la précision du temps s'étend jusqu'à la seconde).
Double
Né avec Visual dBASE 7, le champ Double est un champ binaire de huit octets. Tout comme le champ Long, il peut contenir des nombres positifs ou négatifs et est conçu pour exécuter rapidement des calculs. Il s'en distingue par sa capacité de stocker des décimales.Il est à noter que lorsqu'on établit qu'un champ est de type Double, le Concepteur de table inactive la case où vous devriez préciser le nombre de décimales et y inscrit zéro, ce qui laisse croire qu'un champ Double ne peut pas accepter de décimale. Cela est inexact. À l'interne, Visual dBASE et dB2K sauvegardent les données dans un tel champ avec une précision d'environ quinze décimales. Aux fins d'affichage seulement, ces données sont arrondies à la volée au nombre de décimales déterminé par l'item Decimals de la rubrique [CommandSettings] du vdb.ini ou du db2k.ini. On peut changer ce degré de précision apparent en tapant set decimals to N (où N est le nombre voulu de décimales) dans la Fenêtre de commande, ou par l'item Properties|Desktop Properties, sous l'onglet Programming. Cela n'affecte donc que l'affichage du nombre, pas sa valeur enregistrée dans la table.
AutoIncrement
Innovation de Visual dBASE 7, le champ AutoIncrement est une variante du champ Long. Leur similitude explique pourquoi seul un champ AutoIncrement ou Long d'une table peut être lié au champ AutoIncrement d'une autre table. Le champ AutoIncrement se distingue par le fait que son contenu ne peut être modifié et qu'il n'est généré qu'au moment précis où une nouvelle fiche est sauvegardée.Une table ne peut contenir qu'un seul champ AutoIncrement. Même si le Concepteur de table semble permettre la création d'une table possédant plus d'un champ AutoIncrement, le BDE ne vous laissera pas la sauvegarder.
_dbaselock
Ces champs sont très différents des autres ; on ne peut pas les créer à partir du Concepteur de table mais seulement par la commande convert après que l'usager ait ouvert la table de manière exclusive. Ces champs servent à inscrire l'identité du plus récent utilisateur à avoir modifié une fiche ou une table sur un réseau, de même que l'heure et la date de cet accès à la table. Par défaut, ce champ occupe 16 octets.
use Ma_Table exclusive
convert
display structureIl est à noter qu'il ne suffit pas de demander d'ouvrir une table en mode exclusif pour que le dBASE vous accorde cette permission. Elle vous est toujours accordée lorsque vous êtes seul à utiliser cette table. En réseau, c'est différent. Si quelqu'un d'autre a déjà réquisitionné la table en mode exclusif, ou si votre demande à été transmise au BDE au cours des quelques milli-secondes où étaient enregistrées des modifications à la table, votre réquisition pourrait être nulle sans que vous le sachiez (puisque le BDE n'émet pas toujours de message d'erreur lorsque cela se produit). Donc si vous travaillez en réseau, après avoir demandé d'ajouter un champ _dbaselock, il vous faudra donc vérifier, à l'aide de la commande display structure, que ce champ a bien été ajouté. Truc : Lorsque vous réussissez à ouvrir une table en mode exclusif, la barre d'état affiche un message analogue à ma_table.dbf exclusive Row: 1/n. Si le mot «exclusive» n'apparaît pas, c'est que vous avez échoué.
Revenons donc à la création de la structure de notre annuaire téléphonique, interrompue par cette présentation des divers types de champs. La colonne Width détermine la taille du champ. Prévoyez suffisamment de place pour pouvoir entrer l'information que vous souhaitez y inscrire. Par exemple, pour stocker un montant de 12.50, vous avez besoin de cinq espaces : deux pour les décimales, un pour le point et les deux autres pour les chiffres avant le point. Si ce nombre peut être négatif, un espace supplémentaire doit être prévu.
S'il s'agit de sommes d'argent sur lesquelles vous aurez à effectuer des calculs autres que de simples additions ou soustractions, prévoyez cinq ou six décimales afin d'avoir un degré de précision satisfaisant, quitte à laisser dBASE arrondir les montants obtenus en n'affichant que deux décimales.
Indexer vs réorganiser
On peut créer des index pour n'emporte quel type de champ sauf les suivants : Binaire, _dbaselock, Logique, Mémo et OLE. Quand l'index est permis, lorsque le curseur arrive dans la colonne Index, la case se transforme en liste déroulante avec trois choix possibles : None, Ascending ou Descending. Cela correspond aux choix suivants : «pas d'index», «en ordre croissant» ou «en ordre décroissant». Ceci permet de créer des index simples. Nous verrons plus loin comment créer des index plus complexes.
Lorsque vous créez un index, les fiches demeurent dans l'ordre selon lequel elles ont été ajoutées dans la table. Tout ce que vous faites, c'est de créer un fichier (s'il n'existe pas déjà) portant le même nom que la table mais avec une extension .mdx. Dans ce fichier se trouve l'ordre de préséance des fiches en vertu des index.
Tout comme le Responsable du protocole lors d'un dîner à l'Élysée sait qui peut s'asseoir à la gauche ou à la droite du Président de la République française, peu importe l'ordre d'arrivée des convives, l'index sait dans quel ordre doit s'afficher les fiches dans une vue tabulaire, en dépit de leur ordre naturel (c'est-à-dire l'ordre selon lequel elles ont été ajoutées dans la table).
Pourquoi ne pas tout simplement réorganiser la table physiquement de manière à ce que les fiches soient dans l'ordre souhaité plutôt que de s'encombrer d'un index ? Parce que les index possèdent plusieurs avantages :
Malgré cela, on peut avoir des raisons très valables de vouloir réorganiser une table. Par exemple, afin d'archiver une liste alphabétique des membres d'une association pour une année donnée. Il vous faudra alors recourir à la commande sort. Cette commande crée une nouvelle table identique à la première, à deux différences près : la nouvelle table est ordonnée sur un des champs, et aucun index de la table d'origine n'est conservé dans la nouvelle.
Dans l'exemple ci-dessous, on crée
une nouvelle table (appelée Membres_2000)
dans laquelle toutes les personnes dont le champ
Année_de_cotisation renferme
la valeur 2000 seront
classées en ordre croissant de
Nom.
|
use Ma_Table sort on Nom to "Membres_2000" for "Année_de_cotisation" = "2000" |
|
Lorsqu'une table est ouverte par le biais de la Fenêtre de commande, on peut afficher ses index à l'aide de la commande display structure (F5) . Lorsqu'il est créé à partir de la Fenêtre de commande ou par programmation, un index ne sera révélé par la touche F5 et affiché dans le panneau des résulats qu'aux conditions suivantes :
|
en xDML : use Ma_Table exclusive index on Nom_de_champ tag Nom_Index use |
||
|
en OODML : |
||
| index1
= new DBFIndex()
index1.indexName = "Nom_Index" index1.expression = "Nom_de_champ" _app.databases[1].createIndex("Ma_Table", index1) |
// on crée un objet Index
// on lui donne un nom // on le définit comme un index simple basé sur un champ // '_app.databases[]' est la matrice contenant les noms // des tables dans le répertoire courant |
|
La création d'un index ne
répondant pas aux deux premières conditions n'est possible,
à partir de la Fenêtre de commande, que si le nom du champ
est placé entre deux-points et le nom de l'index, entre des guillemets
anglais (simples ou doubles). Par exemple, dans le cas d'un nom de champ
comportant un espace, set index on :Code
postal: tag "Code postal".
En OODML, on écrirait plutôt :
|
:Nom Index avec des espaces: = new DBFIndex() :Nom Index avec des espaces:.indexName = "Nom Index avec des espaces" :Nom Index avec des espaces:.expression = "Nom du champ avec des espaces" _app.databases[1].createIndex("Ma_Table", :Nom Index avec des espaces:) |
|
À partir de la Fenêtre
de commande, on peut également créer un index sur un champ
logique de la manière ci-dessous (qui crée un index textuel
à partir du champ appelé «champ_logique»).
|
use Ma_Table exclusive index on IIF(Champ_logique
=
true, "Oui", "Non") tag
"Champ_logique"
use |
|
En OODML, on créerait un
index basé sur un champ logique de la manière suivante :
|
Oui_Non = new DBFIndex() Oui_Non.indexName = "Oui_Non" Oui_Non.expression = [iif(Champ_logique = true, "Oui", "Non")] _app.databases[1].createIndex("Ma_Table", Oui_Non) |
|
Dans ce cas-ci, le commande conditionnelle IIF() (à ne pas confondre avec IF) inscrit «Oui» quand la valeur rencontrée est true, et inscrit «Non» lorsque ce n'est pas le cas. Cela permet donc d'avoir un index textuel basé sur un champ logique. Puisque Oui et Non occupent chacun de trois espaces, on évite d'avoir un index de taille variable, ce qui est interdit. En dBL, la partie = true dans une commande IF() ou IIF() n'est pas strictement nécessaire mais je l'ai précisé ici pour des raisons de clarté.
Pour terminer, lorsqu'une table indexée est affichée en mode tabulaire ou dans une grille, l'ascenseur (c'est-à-dire la barre de défilement verticale) est inopérant. C'est là le seul inconvénient des index.
La commande display status (F6) révèle le liste de tous les index, y compris ceux qui ne sont pas trouvés avec display structure (F5).
Pour supprimer
un index à partir de la Fenêtre de commande, une fois de plus
nous avons le choix de procéder en xDML ou en OODML :
|
en xDML : use Ma_Table exclusive delete tag Mon_Index use en OODML :
|
|
Ajouter d'autres champs
Dans le Concepteur de table, lorsque le curseur se trouve dans la colonne réservée aux index, on appuie sur Entrée pour passer à la ligne suivante.
Par simple technique de glisser-déposer, on peut modifier l'ordre des champs. En effet, lorsque le curseur de la souris est placé dans la colonne Fields, il se change en main ouverte. Il suffit alors d'enfoncer le bouton de la souris et de déplacer le champ là où on veut qu'il se trouve.
De manière générale,
le Concepteur de table possède les raccourcis suivants.
| Touche de raccourci | Effet | ||
| Flèche du haut | on passe au champ précédant | ||
| Flèche du bas | on passe au champ suivant ou on crée un nouveau champ | ||
| Flèche de droite | on passe à la lettre ou à la colonne suivante | ||
| Flèche de gauche | on passe à la lettre ou à la colonne précédante | ||
| Entrée | on passe à la colonne suivante ou on crée un nouveau champ | ||
| Touche de tabulation (Tab) | on passe à la colonne suivante ou on crée un nouveau champ | ||
| Maj Tab | on passe à la colonne précédente ou à la dernière colonne du champ précédant | ||
| Ctrl a | on ajoute un nouveau champ à la fin de la liste des champs | ||
| Ctrl n | on insère un nouveau champ | ||
| Ctrl u | on enlève le champ dans lequel le curseur se trouve | ||
| Ctrl g | pour déplacer le curseur à un numéro de champ précis | ||
Les raccourcis pour ajouter, insérer
et détruire un champ correspondent aux boutons ![]() de la Barre d'outils et à certains items dans le menu Structure.
de la Barre d'outils et à certains items dans le menu Structure.
Complétez la structure de cette table de manière à obtenir ce qui suit (tout en l'adaptant à vos besoins). Si vous donnez à vos champs des noms plutôt longs, il se pourrait que la largeur de la colonne Name soit trop étroite pour vous. Vous pouvez élargir une colonne en plaçant le curseur de la souris au-dessus de la ligne qui sépare cette colonne de la suivante. Le curseur change alors d'aspect (voir l'image ci-dessous). Vous n'avez qu'à gratter vers la droite (en maintenant enfoncé le bouton gauche de la souris) pour élargir la colonne de gauche.
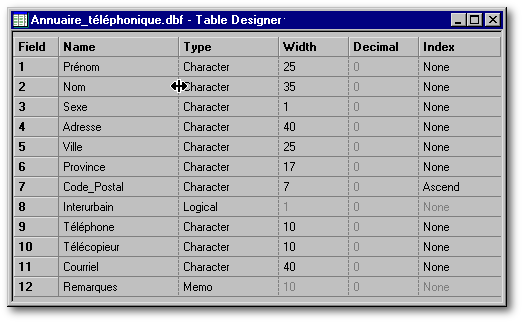
On peut modifier l'ordre des colonnes en plaçant le curseur de la souris au-dessus de l'entête d'une colonne (sauf la colonne Field qui est immuable). Ce curseur se transforme alors en main ouverte. On gratte l'entête pour déplacer la colonne où l'on veut. Ce changement n'affecte en rien la structure de la table ; si vous fermez cette table et l'ouvrez de nouveau dans le Concepteur de table, les colonnes seront disposés exactement comme ils l'étaient originellement.
Plus utile est la possibilité de modifier la structure d'une table par glisser-déposer. Il suffit de placer le curseur de la souris à l'extrême gauche du Concepteur de table, au-dessus d'un numéro de champ : le curseur se change en main ouverte. On gratte la rangée vers le haut ou vers le bas, jusqu'à l'endroit précis où on veut que le champ se trouve dorénavant. Si on sauvegarde les changements et on ouvre la table de nouveau, la nouvelle structure de la table reflétera les changement apportés.
Veuillez noter que dans le cas des numéros de téléphone, de télécopieur et de code postal, il est préférable de ne pas prévoir d'espace pour les séparateurs de chiffres. Par exemple, si vous désirez que les numéros de téléphones soient formatés (123)456-7890, prévoyez dix chiffres (donc rien pour les parenthèses et le trait-d'union). dBASE vous fournira les outils pour formater correctement ce champ sans que les utilisateurs de votre table n'aient à dactylographier ces séparateurs de chiffres lors de la saisie des données.
Pour sauvegarder la table, choisissez l'item File|Save du menu ou son raccourci Ctrls. Une boîte de dialogue vous demandera de nommer cette table afin de la sauvegarder. Une table peut porter n'importe quel nom, du moment que ce nom n'est pas celui d'une commande dBL, ni contenir un trait-d'union (ce qui causera des problèmes lorsque vous voudrez effectuer des requêtes SQL sur cette table).
Modifier la structure d'une table existante
Pour appeler le Concepteur de table afin de modifier la structure d'une table à partir du Navigateur, on doit soit :
| use Ma_Table exclusive | // remplacer Ma_Table par le nom de la table à ouvrir | |
| modify structure | ||
Si votre table renferme des fiches, et que vous vouliez renommer plusieurs champs, il est préférable d'effectuer un seul changement à la fois (et de sauvegarder) plutôt que d'effectuer en bloc plusieurs changements de nom, particulièrement lorsque ces champs sont consécutifs.
Quant à l'ajout ou à l'enlèvement de champs, on peut procéder en bloc, tant et aussi longtemps qu'on ne renomme pas de champs par la même occasion. Le raccourci Ctrls permet de sauvegarder les changements tandis que Ctrlw permet de sauvegarder et de fermer le Concepteur de table par la même occasion.
Comment copier une table ?
Même si les versions à
32 bits du BDE sont beaucoup plus fiables que les versions utilisées
par le Visual dBASE 5, il est préférable dans tous
les cas de créer une copie de sauvegarde d'une table avant d'en
modifier la structure.
| copy table Ma_Table to Copie_de_sauvegarde | |
Pour copier une table, nous avons
le choix entre deux commandes, chacune d'elles ayant ses particularités.
Copy
table "Ancienne_Table" to "Nouvelle_Table" permet
de copier une table sans avoir à l'ouvrir au préalable et
fait en sorte que la nouvelle table possède non seulement la même
langue, mais également le même niveau que l'ancienne. Par
contre, la commande copy to "Nouvelle_Table"
nécessite
l'ouverture préalable de la table à copier : la nouvelle
table possède la même langue et le même niveau que la
table d'origine. Lorsqu'on précise
with production à
cette dernière commande, cela permet de faire en sorte que la nouvelle
table soit naturellement classée selon l'index de la table d'origine.
Pour terminer, la commande use (seule,
sans objet) permet de refermer les tables ouvertes.
|
use "Ancienne_Table" order tag "Nom_d_index" copy to "Nouvelle_Table" with production |
|
| use | |
L'OODML possède
une commande similaire à
Copy table,
c'est-à-dire qu'elle ne nécessite pas l'ouverture au préalable
de cette table et qu'elle effectue une copie parfaite de la table (avec
ses fichiers .dbt et
.mdx).
Toutefois cette commande nécessite que cette table soit située
dans le répertoire courant. Cette commande est la suivante :
|
_app.databases[1].copyTable("Ma_Table", "Copie_de_Ma_Table") |
|
Comment ajouter des fiches ?
 Par
défaut, lorsqu'on demande à dBASE d'ajouter une fiche, celle-ci
est ajoutée en mode colonne, c'est-à-dire avec tous les champs
alignés les uns sous les autres. Toutefois il y a trois modes d'affichage
d'une table : en mode colonne, en mode formulaire, ou en mode
tabulaire (c'est-à-dire comme s'il s'agissait d'un tableau). En
appuyant plusieurs fois sur la touche F2, on passe successivement d'un
mode à l'autre. En mode tabulaire, on peut modifier la largeur des
colonnes et leur séquence (comme nous l'avons vu relativement au
Concepteur de table). Toutefois, cela ne modifie pas la structure de la
table : les champs demeurent dans le même ordre, seul leur affichage
étant modifié et ce, temporairement (tant que la table est
affichée).
Par
défaut, lorsqu'on demande à dBASE d'ajouter une fiche, celle-ci
est ajoutée en mode colonne, c'est-à-dire avec tous les champs
alignés les uns sous les autres. Toutefois il y a trois modes d'affichage
d'une table : en mode colonne, en mode formulaire, ou en mode
tabulaire (c'est-à-dire comme s'il s'agissait d'un tableau). En
appuyant plusieurs fois sur la touche F2, on passe successivement d'un
mode à l'autre. En mode tabulaire, on peut modifier la largeur des
colonnes et leur séquence (comme nous l'avons vu relativement au
Concepteur de table). Toutefois, cela ne modifie pas la structure de la
table : les champs demeurent dans le même ordre, seul leur affichage
étant modifié et ce, temporairement (tant que la table est
affichée).
À la fin d'une table affichée à l'écran, on ajoute des fiches par l'une ou l'autre parmi les méthodes suivantes :
Habituellement, lorsqu'on a recours à l'interface de dBASE pour créer des fiches, c'est pour en créer quelques unes qui serviront à nous assurer que l'interface utilisateur fonctionne correctement. En supposant que vous vouliez créer un bon nombre de fiches en mode colonne ou en mode tabulaire, il y a trois petits secrets qui vous simplifieront la tâche.
Lorsqu'une table contient un champ mémo, ce dernier est représenté par l'icône d'une page blanche lorsqu'il est vide, et par un A majuscule sur une même page blanche lorsqu'il renferme des données. Toutefois, il est possible de faire en sorte qu'en mode colonne et en mode formulaire (mais pas en mode tabulaire), les premières lignes d'un champ mémo apparaissent dans un éditeur, afin de donner un apperçu de son contenu. À l'item Properties|Desktop Properties, sous l'onglet Data, cliquez le bouton Associate Component Types et dans la boîte de dialogue qui s'ouvrira, choisissez le bouton radio Editor plutôt qu'Entryfield pour les champs mémo. Si le contenu de votre table est déjà affichée, il vous faudra fermer cette table et l'ouvrir de nouveau pour que ce changement prenne effet. Cela affectera également le Concepteur de fenêtres : par défaut, il vous proposera dorénavant des éditeurs pour représenter ces champs.
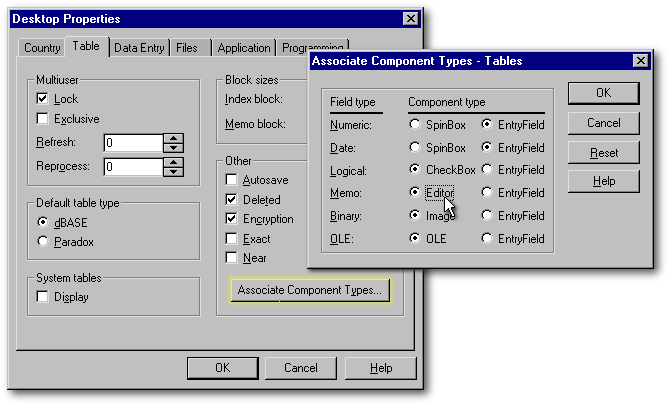
Toujours à l'item Properties|Desktop Properties, toutefois sous l'onglet Data Entry (ce qui signifie «Saisie des données»), lorsque la case à cocher CUA Enter est vide, vous pourrez déplacer le curseur au champ suivant à l'aide de la touche Entrée (comme le fait déjà la touche de tabulation). C'est seulement lorsque le curseur entrera dans l'éditeur d'un champ mémo qu'Entrée retrouvera son rôle traditionnel de «retour du chariot» (note : vous devrez recourir à la touche de tabulation ou à la souris pour sortir d'un éditeur).
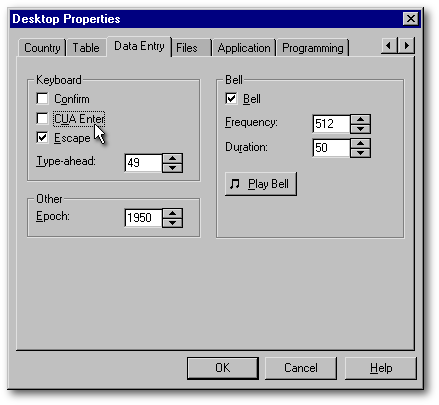
Pour terminer, sous le même onglet dans l'image ci-dessus, lorsque la case à cocher Confirm est vide, le curseur passe automatiquement au champ suivant dès qu'un champ est plein. Une tonalité vous avise lorsque cela se produit. Lors de la saisie des données des réponses à un sondage, vous vous éviterez des milliers d'Entrée par ce moyen. Une fois devenu habile à la saisie des données, vous pouvez faire taire cette tonalité en laissant vide la case à cocher Bell (qui signifie «sonnette»).
À partir de la Fenêtre
de commande (ou n'importe où dans vos applications en dBL) on obtient
le même résultat avec les lignes de code suivantes :
|
set CUAEnter off set Confirm off |
|
Les utilisateurs d'une version de dBASE pour le DOS se rappelleront que dès qu'une fiche était complétée, on passait à une nouvelle fiche automatiquement en appuyant sur Entrée. Sous Visual dBASE 7 et dB2K, cela fonctionne lorsqu'on est en mode tabulaire. En mode colonne ou formulaire, utilisez le raccourci Ctrl a.
À partir de l'interface de dBASE, la saisie des données ne cause pas de problèmes particuliers sauf en ce qui concerne certains types de champs. Lorsqu'une table contient un champ _dbaselock, celui-ci est invisible. Si elle contient un champ AutoIncrement, seul dBASE peut y inscrire un numéro : il ne le fait qu'au moment où la fiche est sauvegardée. La gestion des champs OLE sous dBASE est la même que pour n'importe quelle application Windows.
En mode colonne ou en mode formulaire, on accède au champ mémo et on le quitte comme n'importe quel autre, par la touche de tabulation. En mode tabulaire, le champ mémo est représenté par l'icône d'une page blanche lorsqu'il est vide et par un A majuscule sur une même page blanche lorsqu'il renferme des données. Puisque le présent chapitre concerne l'ajout de fiches, on ne verra ici que l'icône d'une page blanche. En mode tabulaire, on accède à son contenu par l'une ou l'autre parmi les méthodes suivantes :
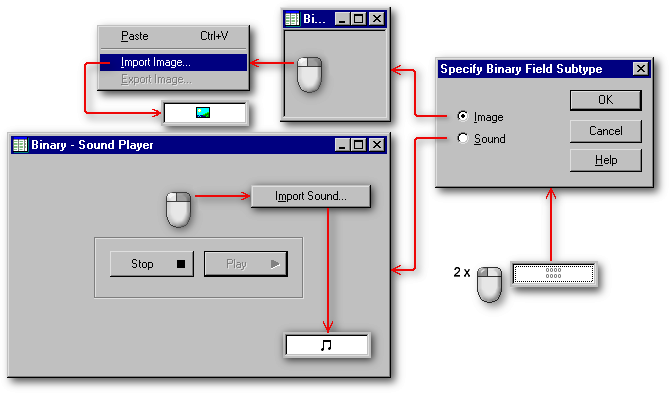
Visual dBASE7 et dB2K supportent exclusivement les formats suivants d'image couleur :
On peut stocker
n'importe quoi dans un champ binaire. Par exemple, vous pourriez y cacher
les plans commerciaux ultra-secrets de votre compagnie. Contrairement aux
champs OLE, que l'on peut prévisualiser en mode colonne ou en mode
formulaire, et sur lesquels on double-clique pour charger une application
pouvant lire leur contenu, les champs binaires sont totalement mystérieux
lorsqu'ils renferment autre chose que des images ou des fichiers wave.
Pour y stocker ou en extraire le fichier «Plans secrets du Penta.gon»,
on procédera ainsi :
|
replace binary champ_binaire from Plans_secrets_du_Penta.gon type 10 // pour stocker copy binary champ_binaire to Plans_secrets_du_Penta.gon // pour extraire le fichier stocké |
|
À la fin de la première ligne de l'encadré ci-dessus, le chiffre 10 peut être n'importe quel nombre de 1 à 32767. En plus, si les données de votre table sont encryptées, croyez-moi, il sera impossible de s'emparer du secret que renferme votre table. À noter : en mode tabulaire, lorsqu'un champ binaire renferme autre chose qu'une image ou un fichier wave, ce champ est représenté par les chiffres noirs 0100 0010 plutôt que par les huit petits zéros gris pâle d'un champ binaire vide.
Si vous voulez vous épargner la corvée d'avoir à dactylographier un nom de fichier et son chemin d'accès, vous pouvez tout simplement taper : replace binary champ_binaire from ?. Ce point d'interrogation provoquera l'ouverture de la boîte de dialogue OpenSource File qui vous simplifiera la tâche. De manière analogue, pour un champ OLE, ce sera replace OLE champ_ole from ?.
De la Fenêtre de commande, pour vider le contenu d'un champ binaire ou un champ de type OLE, on utilisera la commande blank field champ_à_vider.
Les valeurs nulles
Lorsque vous créez une nouvelle fiche, tous ses champs semblent vides. Sous Visual dBASE 7 et dB2K, ces champs ne sont pas vraiment vides car ils contiennent alors une valeur dite nulle. Cette valeur permet au logiciel de faire la distinction entre une champ que vous auriez oublié de remplir et un autre que vous choisiriez de laisser vide. Dès que vous inscrivez une valeur dans un champ textuel et que vous l'effacez par la suite, ce champ ne contient plus cette valeur nulle (note : simplement traverser un champ à l'aide de la touche de tabulation ne suffit pas à enlever cette valeur nulle). Dans le cas des champs numériques, lorsqu'ils contiennent une valeur nulle, rien apparaît dans leur case. Autrement, une chiffre, voire zéro, y est inscrit. Voici trois exemples de l'intérêt des valeurs nulles :
|
if Ville = null replace Ville with "" endif |
|
Sous dB2K, la solution est plus simple :
Lorsqu'une table a été ouverte par le biais de l'interface (c'est-à-dire autrement que par une application dBASE) et lorsque cette table est affichée à l'écran, on peut supprimer une ou plusieurs de ses fiches :
|
use Ma_table browse // pour afficher la table dans une vue tabulaire delete 20 // pour supprimer la 20e fiche go top // pour que la suppression soit visible |
|
Habituellement située en bas, la Barre d'état indique à droite le numéro de la fiche vis-à-vis laquelle se trouve le pointeur de la table (par exemple : Row 6/2500, c'est à dire la sixième fiche d'une table qui en contient 2 500). À l'aide des flèches du haut et du bas, si vous déplacez le pointeur de la table, vous remarquerez que la Barre d'état saute par dessus le numéro des fiches supprimées. La raison est que ces fiches «détruites» existent encore. Il suffit de taper dans la Fenêtre de commande set deleted off pour qu'elles apparaissent (après avoir déplacé le pointeur au début ou à la fin de la table) : sous Visual dBASE 7 et dB2K, lorsque le pointeur arrive vis-à-vis une fiche supprimée, la Barre d'état vous le précisera (par exemple, Row 6/2500, Deleted). Lorsque vous avez terminé, remettez set deleted on pour revenir à la normale.
Sous Visual dBASE 5, il est plus facile de repérer les fiches supprimées. En effet, lorsque la table est affichée en mode tabulaire alors que set deleted est off , les fiches supprimées sont marquées d'un «x» rouge dans la colonne à droite du numéro de fiche. Il suffit alors de cocher ou non la case pour supprimer ou rappeler la fiche correspondante.
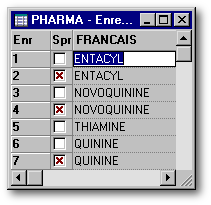
Afin de purger une table de ses
fiches supprimées, on doit utiliser la commande
pack (sur la table ouverte
en mode exclusif). Puisque cette commande réorganise la table, son
exécution est lente. On doit y recourir de temps en temps (par exemple
une fois par mois) afin d'alléger la table des fiches détruites
et accélérer l'exécution des programmes qui l'utilisent.
|
en xDML : use Ma_table exclusive pack use en OODML :
|
|
Pour annuler la suppression d'une fiche, on recourt à la commande recall. Cette commande fonctionne après que vous ayez permis à dBASE d'afficher les fiches supprimées avec la commande set deleted off. Si on désire ne rappeler qu'une seule fiche, une fois que vous avez pris note du numéro qu'elle porte en y déplaçant le curseur (le numéro apparaît dans la Barre d'état), on la rappellera par la commande recall N (où N et le numéro de cette fiche). Quand à elle, la commande recall all rappelle toutes les fiches supprimées encore présentes dans la table. Cette possibilité de rappeler des fiches supprimées est une caractéristique unique des tables dBASE.
Comment consulter une table ?
Pour consulter une table, on a le choix entre :
Note : La boîte de dialogue Open File (illustrée ci-dessus) possède un aspect différent selon la version et la langue du Système d'exploitation.
Lorsque vous travaillerez en dBL, dBASE mettra à votre disposition toute une série de mesures afin de vous protéger contre la corruption de vos données. Ce n'est pas le cas ici, sous Visual dBASE 7 et dB2K. Lorsque vous consultez une table à partir de l'interface de dBASE, vous travaillez habituellement sans filet de protection ; tout au plus Undo et son raccourci Ctrlz dans certains cas. Faites donc bien attention lorsque vous consultez une table de ne pas modifier son contenu par inadvertance. Par exemple, à l'ouverture d'une table, le contenu du premier champ de la première fiche est habituellement sélectionné : il suffit d'appuyer sur une touche pour l'effacer. Sous Visual dBASE 5, il suffit d'utiliser la commande browse noedit (ou browse noedit noappend) pour que la vue tabulaire soit en mode de consultation seulement.
Note : si vous décidez de consulter la table Annuaire_téléphonique, ne vous surprenez pas de voir qu'un des champs soit coloré (nous verrons pourquoi vers la fin du présent texte).
Dès que le contenu d'une table est affiché, la Barre d'outils met toute une série de boutons à votre disposition. De gauche à droite dans la zone qui n'est pas pâlie dans l'image ci-dessous, les deux premiers boutons permettent respectivement de consulter la table ou de modifier sa structure. Les trois autres concernent les modes de consultation : en mode tabulaire, en mode colonne ou en mode formulaire. Les cinq suivants sont pour ajouter, détruire, sauvegarder, annuler ou chercher une fiche. Les deux autres classent les fiches en ordre croissant ou décroissant (si des index le permettent). Quant aux boutons de style «lecteur vidéo», ils offrent un moyen de navigation, c'est-à-dire de déplacement d'une fiche à l'autre.
![]()
Lorsqu'on consulte une table, on
dispose des raccourcis suivants :
| navigation | en mode tabulaire | autres modes | |
| Début
de la table
Page précédente Fiche précédente Premier champ Champ précédent Champ suivant Accéder à un champ mémo, OLE ou binaire Quitter un champ mémo Dernier champ Fiche suivante Page suivante Fin de la table |
Ctrl Début
Pg Précédente Flèche du haut Début Maj Tab Tab F9 Ctrl F4 Fin Flèche du bas Pg Suivante Ctrl Fin |
Ctrl Début
Pg Précédente Maj Tab Tab Tab Tab Pg Suivante Ctrl Fin |
|
| Ajouter une fiche
Trouver une fiche Remplacer des données Sauvegarder les changements |
Ctrl a
Ctrl f Ctrl r Ctrl s |
Ctrl a
Ctrl f Ctrl r Ctrl s |
|
Toutes les possibilités qu'offre la Barre d'outils se retrouvent dans le menu Table, disponible lorsque le contenu d'une table est affiché. Si vous comptez utiliser dBASE uniquement à des fins de programmation, rendez-vous directement à la section «Comment fusionner des tables dBASE ?» puisque jamais l'apprentissage du menu Table vous sera utile. Par contre, si vous voulez connaître toutes les facettes de votre logiciel, voyons ensemble les items de ce menu. Pour le bénéfice de ceux qui ne comprennent pas l'anglais, voici à droite une traduction personnelle de ce menu.
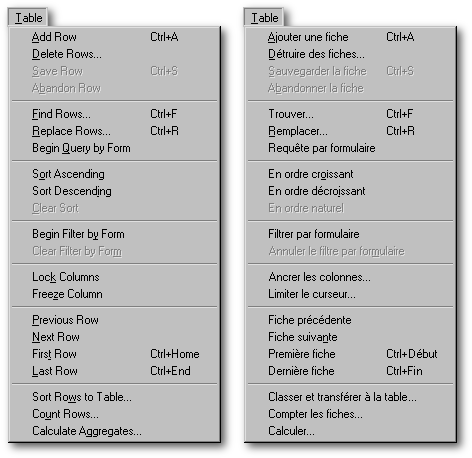
Lorsque vous choisissez l'item Delete Rows , dBASE vous offrira trois choix : Current (pour détruire la fiche courante), Specified (selon le critère ), et All (pour vider le fichier). À l'item Specified, vous avez à préciser le critère selon lequel des fiches seront détruites : il est à noter que le changement ne sera visible qu'après que le pointeur de la table ait été déplacé au début ou à la fin de celle-ci (ou après que vous ayez fermé puis ouvert la table).
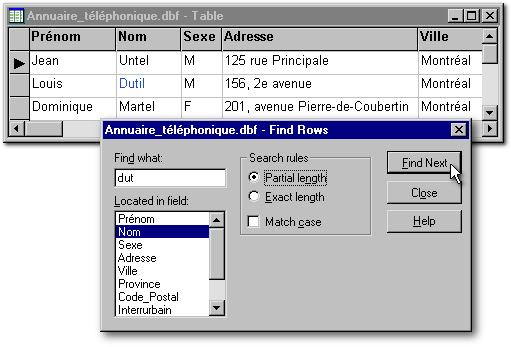
Avec Find Rows (voir l'image ci-dessous), la recherche s'effectue sur les premiers caractères (lettres ou chiffres) de la valeur du champ. Cette recherche s'effectue sur le champ précisé dans la liste Located in field de la boîte de dialogue qui appaît, que ce champ soit indexé ou non. Par défaut, le champ en surbrillance dans la liste Locate in field est le même que le champ dans lequel le curseur se trouve dans la table. Cette recherche n'est rapide que lorsque la table comporte un petit nombre de fiches. Lorsqu'au contraire, la table est de taille importante, cette recherche sera plus lente puis que le dBASE doit passer en revue chaque fiche, les unes après les autres, jusqu'à ce que l'une d'elles corresponde au critère de recherche. Dans la boîte de saisie Find what, on entre les valeurs textuelles telles qu'elles apparaissent dans le champ (en d'autres mots, sans guillemet).
Dans l'exemple ci-dessous, nous effectuons une recherche sur les lettres «dut» ou «Dut» dans le champ «Nom». Si nous cliquons sur le bouton Find Next, le curseur se déplacera de la fiche de Jean Untel à celle de Louis Dutil. La différence entre le bouton radio Partial length et Exact length est que le premier se contente d'avoir comme indice les premières lettres du contenu du champ alors que le second exige, pour trouver une fiche, qu'on lui fournisse la totalité du contenu champ (dans ce cas-ci «dutil», au long). Lorsque la case à cocher Match case est effectivement cochée, la recherche exigera un critère débutant par un «D» majuscule pour trouver «Dutil».
L'item Replace Rows permet de modifier le contenu d'un champ à partir d'un critère de recherche basé sur ce champ ou n'importe quel autre. Dans l'exemple ci-dessous, certains de nos Dutil sont de la ville de Québec et on les a inscrits par erreur comme étant domiciliés à Montréal. Si on désire valider chaque modification à la table, on appuie sur le bouton Find Next pour trouver la première fiche ou la fiche suivante. Une fois le curseur sur cette fiche, vous avez le choix entre effectuer le changement à l'aide du bouton Replace ou sauter au prochain Dutil. Il est à noter que le bouton Replace accomplit deux tâches à la fois ; il remplace et saute à la fiche suivante correspondant au critère de recherche. C'est ce qui explique qu'il provoquera un message d'erreur lorsqu'il effectue le dernier changement possible à la table. Ce message est à l'effet qu'aucune autre fiche correspond au critère de recherche.
Si tous nos Dutil sont de Québec, on peut appliquer le changement globalement en appuyant sur le bouton Replace all (ce qui signifie «Remplacer tous»). Dans ce cas, après avoir fait le décompte du nombre de changements à effectuer, une boîte de dialogue nous demandera de confirmer votre intention. Il est à noter que si vous refusez, l'affichage laisse l'impression que le changement que nous ne souhaitions plus a été effectué quand même : il suffit de fermer la table et de l'ouvrir de nouveau pour constater que cela n'est pas le cas.

L'item Begin Query by Form est très spectaculaire. Il est plus facile à comprendre lorsque la table n'est pas en vue tabulaire. C'est pourquoi je vous demanderais d'appuyer sur F2 jusqu'à ce que vous soyez en mode colonne ou en mode formulaire. Dès que vous choisissez cet item du menu, toutes les données affichées disparaissent. C'est voulu. Vous inscrivez dans un des champs votre critère de sélection (par exemple, «Dutil» au long dans le champ «Nom» «Dut» ne fonctionnera pas). Puis vous revenez au menu pour choisir le même item (qui aura été renommé Apply Query by Form, ce qui signifie «Appliquer la requête par formulaire). Aussitôt la fiche de Louis Dutil s'affichera. Ce mode de recherche est lui aussi relativement lent parce que dBASE doit passer en revue chaque fiche tant qu'il n'aura pas trouvé la première répondant au critère de recherche. De plus, ce mode de recherche est primitif puisqu'il ne permet de trouver que la première fiche correspondante de la table.
L'item Begin Filter by Form permet de combler cette dernière lacune. On procède de la même manière sauf qu'une fois qu'on est retourné choisir l'item devenu Apply Filter by Form, on demeure sous l'effet du filtre tant qu'on n'est pas retourné au menu pour annuler l'effet du filtre (Clear Filter by Form). Tant que le filtre s'applique, on ne se déplace dans la table que parmi les fiches répondant au critère du filtre. Le seul inconvénient, c'est qu'on ne peut pas, par exemple, choisir les fiches des personnes domiciliées hors de Montréal, ou dont le numéro de téléphone est plus grand que tel nombre. De plus, lorsque vous choisissez un critère qui n'existe pas, dBASE affiche un message d'erreur puis vous offre de nouveau l'ensemble des champs vides afin que vous puissiez choisir un autre critère. Si vous y renoncez (en choisissant l'item Clear Filter by Form), les champs demeurent vides comme si vous étiez en train de créer une nouvelle fiche. Il suffit de naviguer dans la table à l'aide du menu ou de la Barre d'outils pour constater que cela n'est pas le cas.
On peut recourir au préalable à l'item Begin Filter by Form afin de filtrer les fiches à détruire (si elles ont une caractéristique commune et exclusive). De cette manière, on y limite la navigation ce qui permet de passer en revue les fiches qui seront détruites. En choisissant l'option All à l'item Delete Rows du menu, on détruira l'ensemble les fiches «filtrées» et seulement celles-ci. En éliminant le filtre, on retrouvera intactes les autres fiches de la table.
Les items Sort Ascending et Sort Descending ne fonctionnent que lorsque le curseur se trouve dans un champ indexé. De plus il doit s'agir d'un index simple. Si vous créez une index complexe. comme nous le verrons plus loin, celui-ci ne sera pas reconnu.
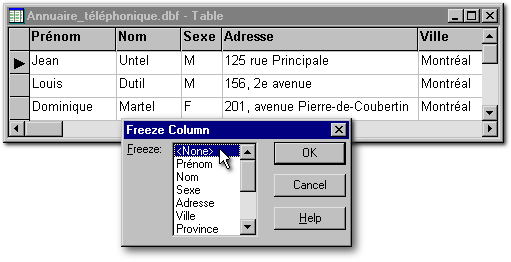
L'item Lock Columns est disponible seulement lorsque la table est affichée en mode tabulaire. Il permet d'ancrer un certain nombre de colonnes à gauche de la vue tabulaire et d'éviter qu'elles ne disparaissent de vue lorsqu'on utilise la barre de défilement horizontal. Lorsque la fenêtre de la vue tabulaire est occupée totalement par les champs que vous venez d'ancrer, il ne suffit pas d'élargir cette fenêtre pour apercevoir les autres champs : vous devez rétrécir les colonnes ancrées jusqu'à ce qu'elles n'occupent plus la totalité de la fenêtre. Ce problème n'existe pas lorsqu'au moins une partie des autres champs étaient déjà visibles au moment de l'ancrage. Pour annuler l'ancrage, on remet à zéro le nombre des colonnes ancrées ou on quitte la vue tabulaire.
L'item Freeze Column limite le déplacement du curseur à l'intérieur d'une colonne. Cet item n'est disponible qu'en mode tabulaire et son effet est annulé dès qu'on quitte ce mode ou qu'on ferme la table. Pour annuler son effet sans cesser de consulter la table, on clique sur cet item du menu à la différence qu'on choisi <None> (ce qui signifie «Aucun») pour libérer le curseur. On peut limiter le curseur de concert avec d'autres choix du menu : cela pourrait être utile sur certains de nos Dutil étaient en réalité des Duteuil dont on aurait mal épelé le nom. Il suffirait alors de limiter la consultation de la table aux Dutil et en plus, de limiter les changements aux noms de famille pour empêcher d'endommager l'information inscrite aux autres champs.
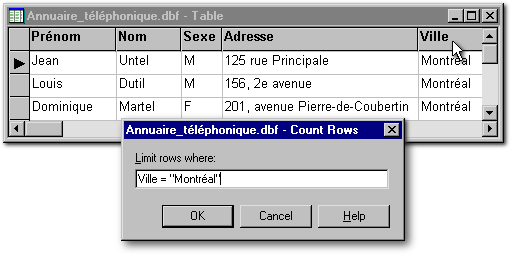
L'item Count Rows dénombre les fiches répondant à un critère. Dans l'exemple ci-dessous, on cherche à savoir combien de personnes dans notre annuaire demeurent à Montréal. Si le nom du champ sur lequel s'applique notre critère avait renfermé un espace, il aurait fallu mettre ce nom entre des guillemets anglais. À l'opposé s'il s'agit d'un champ numérique, la valeur du champ, à droite, s'écrirait sans guillemet.
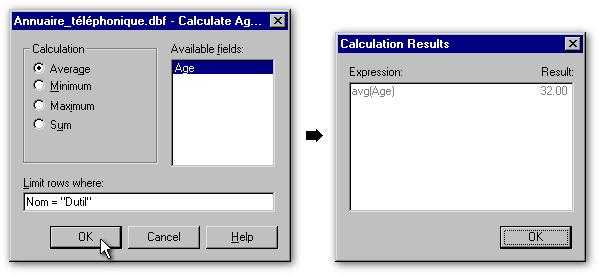
L'item Calculate Aggregates ne fonctionne que sur des champs numériques. Pour les besoins de la cause, nous avons ajouté à notre annuaire un champ pour inscrire l'âge des personnes. On peut alors trouver l'âge moyen (Average), celui de la personne la plus jeune (Minimum), ou de la plus âgée (Maximum) ou faire la somme (Sum) des âges. De plus, on a également la possibilité d'effectuer ces calculs sur l'ensemble de la table ou de les restreindre aux seules personnes répondant au critère précisé dans la boîte de saisie Limit rows where (ce qui signifie «Limiter aux fiches dans lesquelles :»). Dans l'exemple ci-dessus, les Dutil ont 32 ans, en moyenne.
Puisque le menu Table ne
vous offre pas la possibilité de renommer une table, on utilisera
donc la Fenêtre de commande. Pour ce faire, la table en question
doit être fermée. La ligne de code sera :
|
en xDML : rename table "Ancien_nom" to "Nouveau_Nom" en OODML :
|
|
Comment fusionner des tables dBASE ?
Imaginez que trois personnes aient
à colliger des données, chacune de son côté,
et qu'il vous faille combiner les données recueillies en une seule
table. Si chacune de ces tables a la même structure et que vous les
copiez dans le répertoire courant, il suffit de taper dans la fenêtre
de commande :
|
use Table_Principale exclusive append from MiniTable_1 reindex append from MiniTable_2 reindex append from MiniTable_3 reindex |
|
Vous serez sans doute intrigué par le reindex. N'a-t-on pas dit que dBASE mettait à jour les index d'une table dès qu'une fiche est ajoutée et qu'il était donc superflu de demander à dBASE de réindexer une table en pareil cas ? Si, justement. En précisant reindex, on donne l'ordre à dBASE de ne rafraîchir les index que lorsque la totalité des fiches ont été copiées, ce qui accélère le processus.
Comment créer un index complexe ?
Dans la table de notre annuaire téléphonique, l'index basé sur le nom permet de classer les fiches selon le nom de famille mais ne permet pas d'avoir un sous-index qui nous permettrait de classer les membres d'une même famille par leurs prénoms. Même si nous créons un index basé sur les prénoms, il nous faudra choisir entre un classement par nom ou par prénom.
Une première manière de créer des index complexes se fait par le Concepteur d'index. Ce Concepteur n'est disponible que lorsque le Concepteur de table est déjà ouvert. On l'appelle par l'item Structure|Manage Indexes Dans la fenêtre Manage Indexes, on doit cliquer sur le nom de l'index à modifier avant de d'appuyer sur le bouton Modify
Dans la fenêtre Define Index, le bouton radio Ascending order précise que les fiches seront classées en ordre croissant. Le bouton radio Allow duplicates permet les doublons dans le champ indexé (par exemple, permet que deux personnes puissent porter le même nom). Le bouton radio Specify from field list (ce qui signifie «Spécifier à partir de la liste des champs») correspond également à un choix approprié puisque notre index sera créé à partir de deux champs de la table. Dans la liste des champs disponibles, au centre, on ajoutera le champ «Prénom» à la liste de droite où est déjà choisi le champ «Nom». Cette liste, Fields of index key, est la liste des champs sur lesquels est basé l'index que nous sommes en train de créer. Cela fait en sorte que l'index «Nom» passe d'un index simple basé sur le nom de famille seulement, à un index complexe qui classera les personnes par nom de famille, puis par prénom à l'intérieur de chaque famille. Puisque nous modifions un index existant, nous n'avons pas à lui donner un nom. Si nous étions en train de créer un nouvel index, il nous resterait à le nommer dans la dans la boîte de saisie Index name (qui serait alors disponible). Le nom d'un nouvel index peut être celui d'un champ existant.
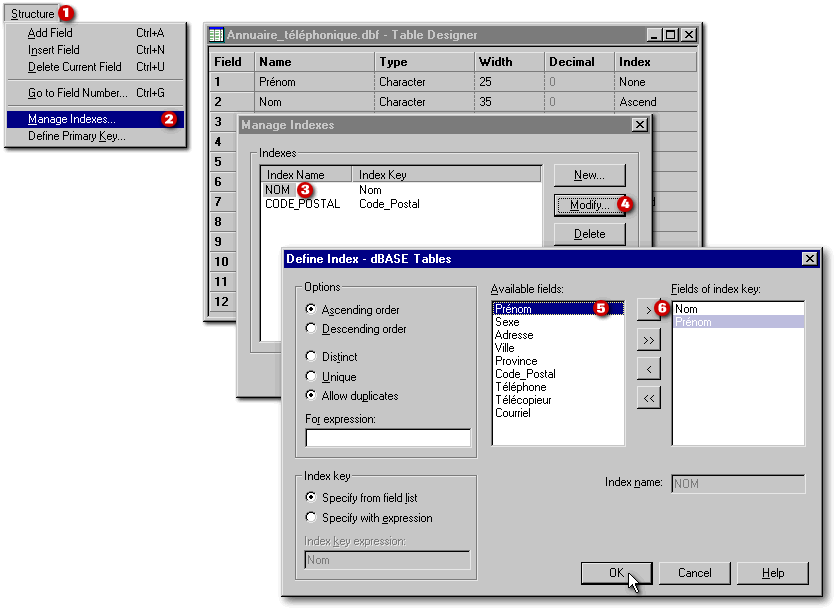
Plus tôt, nous avons vu qu'un index ne peut avoir plus de cent caractères de large. Dans ce cas-ci, la taille cumulative des champs Nom et Prénom fait 70 espaces. Même en deçà de la limite du BDE, la mise à jour des index dBASE s'exécutera plus rapidement si on évite de créer des index volumineux. Lorsqu'on termine l'ajout d'une nouvelle fiche, dès qu'on sauvegarde la table ou au moment précis où va s'amorcer la navigation dans une table (pour créer une autre fiche ou pour consulter une fiche existante), dBASE rafraîchit ses index. Pour optimiser l'exécution de vos programmes, vous pourriez limiter les caractères pris en considération par l'index aux dix ou quinze premiers d'un champ. Dans ce cas, vous choisiriez le bouton radio Specify with expression, en bas à gauche, et dans la boîte de saisie Index key expression(qui deviendrait alors disponible), vous préciseriez left(Nom, 15) + left(Prénom, 10) Note : ne pas mettre d'espace entre left et l'ouverture de la parenthèse. Ici la fonction left() sélectionne les caractères de gauche d'un champ. À l'intérieur de la parenthèse, il y a deux paramètres : le champ concerné et le nombre de caractères à sélectionner.
La boîte de saisie For expression, au centre, permet de créer un index partiel, c'est-à-dire un index où seulement une partie des fiches seront pris en considération. Par exemple, si dans cette boîte de saisie on écrit TRIM(Nom) = "Martel", seules les fiches dont le contenu du champ Nom est «Martel» seront affichées lorsqu'on consultera cette table classée par cet index. Il est à noter que la commande TRIM() enlève les espaces libres à droite d'une valeur. Sans TRIM(), cette même ligne de commande devrait tenir compte du fait que le champ Nom occupe 35 espaces. Il faudrait alors écrire Nom = "Martel " ou Nom = "Martel" + space(29).
Lorsqu'on utilise commande trim() pour créer un index partiel, celle-ci n'est prise en considération que lors de la création de l'index (pour distinguer les fiches pouvant faire partie de l'index). Au sein même de l'index, la taille des entrées en n'est pas affectée et est rigoureusement la même. Dans l'exemple plus haut, toujours dans le but de diminuer la taille de l'index, si on remplaçait left(Nom, 15) + left(Prénom, 10) par trim(Nom) + trim(Prénom) dans l'expression de l'index, cela serait une grave erreur puisqu'il ne faut jamais créer un index de taille variable. En effet, puisque la longueur du nom et celle du prénom varient d'une personne à l'autre, les entrées au sein de l'index varieraient d'une fiche à l'autre. Cela conduit inévitablement à la corruption de l'index lors de l'ajout de nouvelles fiches. Jamais, jamais, jamais, on ne doit créer d'index de taille variable.
De la Fenêtre Manage Indexes (ci-dessus), les boutons New, Modify et Delete permettent respectivement de créer, modifier et détruire un index.
De la Fenêtre de commande,
on crée un index de la manière suivante. Ici on ajoute la
commande upper()
sans espace entre upper et l'ouverture de la parenthèse pour que
dans l'index tous les noms et prénoms soient en majuscules, afin
d'éviter que «DUTIL» soit classé différemment
de «Dutil». Cela n'affecte pas les noms et prénoms dans
la table : seulement leur entrée correspondante dans l'index.
|
use "Annuaire_téléphonique" exclusive index on upper(Nom + Prénom) tag Nom use // ou use "Annuaire_téléphonique" exclusive
// ou use "Annuaire_téléphonique" exclusive
// ou Index1
= new DBFIndex()
|
|
La première ligne ci-dessus ouvre la table en mode exclusif. Il est impossible de modifier la structure d'une table sans l'ouvrir en mode exclusif. Pendant que la table est ouverte dans ce mode, aucun autre poste de travail sur le réseau ne peut modifier la table (y ajouter des fiches, par exemple). À la deuxième ligne, order on crée l'index, tandis que tag précise le nom que portera l'index. La commande use (sans rien d'autre) permet de refermer la table. Le dernier exemple, en OODML, ne fonctionne que si la table est située dans le répertoire courant : il ne nécessite pas l'ouverture préalable de cette table.
Lorsqu'une table est ouverte à partir de la Fenêtre de commande, seuls les index simples, basés sur un seul champ, apparaissent dans le panneau des résultats lorsqu'on appuie sur la touche F5 (display structure) alors qu'on peut voir tous ses index en appuyant sur F6 (display status).
Les propriétés des champs
Plusieurs des concepteurs de dBASE s'accompagnent de palettes flottantes. C'est le cas du Concepteur de table. Ce dernier possède une seule palette flottante : il s'agit de l'Inspecteur de propriétés. Alors que le Concepteur de table est déjà ouvert, si cet inspecteur n'est pas visible on appuiera sur la touche F11 pour le faire apparaître. Retenez bien cette touche de raccourci : c'est une de celles que vous utiliserez le plus souvent. Parce qu'en programmation orientée objet, on travaille essentiellement sur des propriétés d'objet, sur leurs fonctions et les événements qui les affectent. Or tout cela est disponible par le biais de l'Inspecteur de propriétés.
Si on ouvre la table Annuaire_téléphonique et on appelle le Concepteur de table comme si nous voulions modifier sa structure, l'Inspecteur nous apparaîtra comme ci-dessous. La liste déroulante affiche le nom du champ dans le quel le curseur se trouve dans le Concepteur de table. Si on ouvre cette liste déroulante, on y verra l'ensemble des champs de la table. On peut se déplacer d'un champ à l'autre par le biais de cette liste (ou en cliquant sur le nom du champ dans le Concepteur de table). Comme tous les champs textuels, le champ Province possède quatre propriétés.
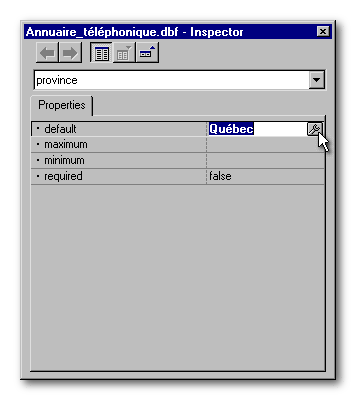
La propriété default permet de préciser, par exemple, un nom de province qui apparaîtra par défaut chaque fois qu'une nouvelle fiche sera créée. Ce nom pourra être modifié lors de la saisie des données ou être accepté tel quel. Les propriétés maximum et minimum limitent la saisie des données aux valeurs comprises entre les deux. Quant à la propriété required, elle empêche qu'à la saisie des données, on puisse quitter une fiche si ce champ possède une valeur nulle.
Les propriétés standards
diffèrent selon le type de champ.
| Type |
|
|
|
|
|
| Character |
|
|
|
|
|
| Numeric |
|
|
|
|
|
| Memo |
|
||||
| Logical |
|
|
|||
| Date |
|
|
|
|
|
| Float |
|
|
|
|
|
| OLE |
|
||||
| Binary |
|
||||
| Long |
|
|
|
|
|
| TimeStamp |
|
|
|
|
|
| Double |
|
|
|
|
|
| AutoIncrement | |||||
| _dbaselock | |||||
Il est à noter que dans le cas des champs de type date, si la propriété default vaut today (ce qui signifie «aujourd'hui»), la date de la création de la fiche apparaîtra par défaut. Quant aux champs TimeStamp, la valeur par défaut now inscrira le moment du début de la création de la fiche.
Mais attendez : il y a mieux. On peut également créer des propriétés personnalisées. Pour ce faire, on clique avec le bouton droit de la souris sur l'Inspecteur. Dans le menu contextuel, on choisit l'item New Custom Field Property Ce choix fait apparaître la fenêtre Custom Field Property Builder (ou Concepteur de propriété personnalisé d'un champ). Cette boîte de dialogue possède une liste déroulante dans laquelle vous pouvez choisir parmi les 56 propriétés ci-dessous, que vous propose Visual dBASE7 ou dB2K.
Une fois que vous avez choisi le nom d'une propriété, il ne vous reste plus qu'à préciser dans la boîte de saisie Value, la valeur que vous voulez lui donner. Il est à noter que vous pourriez refuser d'être limité aux propriétés que vous suggère le logiciel et en créer une nouvelle de toute pièce. Toutefois dans ce dernier cas, cette propriété sera l'équivalent d'une variable attachée à ce champ.
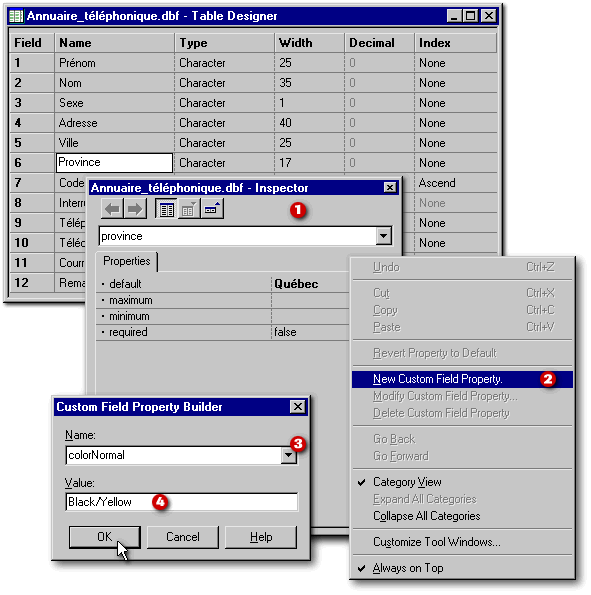
Dès que vous fermerez cette boîte de dialogue, l'Inspecteur aura créé une nouvelle catégorie de propriétés appelée Custom dans laquelle votre propriété personnalisée et sa valeur apparaîtront. Pour n'importe quel champ, vous pouvez créer autant de propriétés personnalisées que vous le souhaitez. Dans l'exemple ci-dessus, les données relatives au champ «Province» seront dorénavant affichées en caractères noirs sur fond jaune partout où la table Annuaire_téléphonique sera utilisée.
Créer une table par programmation
Au début de la section «Comment créer une table ?», nous avions annoncé qu'on pouvait créer une table par programmation. En effet, l'interface de Visual dBASE ou de dB2K n'est pas essentiel à la création d'une table. Vous pourriez créer une application qui nécessite l'existence d'une table et prévoir que si l'utilisateur l'a détruite par mégarde, votre application recréera la table dont l'application a besoin plutôt que d'afficher un message d'erreur. D'autre part, lorsque vous demandez de l'aide dans les forums de discussion de dBASE Inc., il peut être utile de publier un exemple de ce vous tentez d'accomplir. Or l'inclusion d'une table est parfois nécessaire à la compréhension de votre problème.
Pour ce faire, nous allons utiliser
le SQL (soit
Structured Query Language, ce qui signifie «Langage
de requêtes structurées»). Le SQL est un langage de
gestion de base de données mis au point par IBM et qui est devenu
au fil des années un standard incontournable. Nous allons créer
une table identique à Annuaire_téléphonique,
que nous appellerons Annuaire2.
En premier lieu, notre code va vérifier si cette table existe déjà
et ne la créer que si elle est inexistante. La création se
fera donc à l'intérieur d'un bloc d'instruction conditionnelle.
|
en xDML : if not file('Annuaire2.dbf') // Si la table n'existe pas // code de création de la table endif en OODML :
|
|
La commande en SQL qui créera
la structure de la table sera create table
Nom_de_la_Table (nom_du_champ, type_SQL).
Les types de champ SQL correspondant aux types de champ dBASE sont illustrés
dans le tableau qui suit (note : dans ce tableau,
n est la taille du champ
tandis que d est
le nombre de décimales).
| Type SQL |
|
|
|
| Character(n) |
|
|
|
| Numeric(n,d) |
|
|
|
| Blob(10,1) |
|
|
|
| Boolean |
|
|
|
| Date |
|
|
|
| Char(n,d) |
|
|
|
| Blob(10,4) |
|
|
|
| Blob(10,2) |
|
|
|
| Integer |
|
|
|
| TimeStamp |
|
|
|
| Float(n,d) |
|
|
|
| AutoInc |
|
|
|
| (pas d'équivalent) |
|
|
|
À titre de rappel, revoyons la structure de la table Annuaire_téléphonique.dbf.
Le code SQL pour créer la
structure de la table Annuaire2 sera
donc le suivant. Il est à noter que si nous avions eu un espace
dans le nom du champ Code_postal,
le SQL refuserait de créer la table. Si vous désirez passer
outre à notre suggestion de ne pas créer de champ dont le
nom renferme un espace, et créer par exemple un champ appelé
Code postal, on remplacerait la ligne de code SQL relative à Code_postal
par la suivante : Annuaire2."Code postal"
char(7),;
|
create table Annuaire2 (; Prénom char(25),; Nom char(35),; Sexe char(1),; Adresse char(40),; Ville char(25),; Province char(17),; Code_postal char(7),; Interurbain boolean,; Téléphone char(10),; Télécopieur char(10),; Courriel char(40),; Remarques blob(10,1)) |
|
Une fois la table créée,
il ne reste plus qu'à créer les deux index.
|
en xDML : use Annuaire2 exclusive index on upper(left(Nom, 20)) + upper(left(Prénom, 15)) tag Nom index on Code_postal tag Code_postal use en OODML :
|
|
Le programme destiné à
créer
la table Annuaire2.dbf se
lira donc comme suit :
|
if not _app.databases[1].tableExists('Phonebook2.dbf') // Si la table n'existe pas create table Annuaire2 (;
index1
= new DBFIndex()
endif
|
Dans la Fenêtre de commande,
on tapera modify command "Créer
annuaire2.prg" pour appeler
l'Éditeur de code et y entrer les instructions ci-dessus. Pour les
exécuter, il suffira de taper dans la Fenêtre de commande
: do "Créer Annuaire2.prg".
Ici les guillemets sont nécessaires parce que le nom du programme
à créer contient un espace. Autrement, ils seraient superflus
(tout comme l'extension .prg que
nous précisons ici pour des raisons didactiques.
Pour modifier la table Annuaire2.dbf
sans utiliser l'interface de Visual dBASE 7 ou de dB2K, on utilisera de
nouveau un peu de SQL. Ainsi pour enlever les champs
Interurbain et
Télécopieur,
puis ajouter un nouveau champ de 30 espaces appelé
Titre, on écrira
(sans avoir à ouvrir la table au préalable) :
|
Alter table "Annuaire2.dbf" drop Interurbain, drop Télécopieur, add Titre char(30) |
|
À retenir
Le GIF animé utilisé au début de présent texte est une gracieuseté de M. Ronnie MacGregor.
Visual dBASE et dBASE et dB2K sont des marques de commerce de dBASE Inc. Windows est une marque de commerce de Microsoft.
©
2001 MGA Communications. Le présent document peut être reproduit
librement à la condition expresse que le texte et ses illustrations
ne subissent aucune modification sans le consentement de l'auteur.