The roots of regular expressions are found in UNIX systems and in particular in the Perl programming language. At its most basic level Perl is a text-manipulation language. It provides powerful features that allow the user to easily do some operations that are more complex in dBL. (It also complicates some other things that are easy in dBL!) Regular expressions are one of the foundations of the Perl programming language and they are built-into the compiler itself. Although each language that supports regular expressions implements them in slightly different ways, all are quite similar to the Perl implementation.
A regular expression is a pattern (or a template) to be matched against a string. Or, to put it another way, a regular expression is a way to search a string for a pattern. In dBL, you may have used a filename skeleton in the getFile() or dir() methods. The online help notes that, a filename skeleton is a character string used as a template to search for matching filenames. The template can contain a mix of required characters plus the wildcard, or placeholder, characters ? and *. This is exactly the way regular expressions work, but the wildcards are much more robust.
Regular expressions are powerful because the pattern is a way of describing a string without having to list each of the possible strings that could match. They are used in several ways. First, theyre used in conditional statements to determine whether a string matches a particular pattern. For many programming languages this is the primary method used to validate user input. Second, theyre used to locate a pattern within a string and replace the matches with something else. There are many uses of a regular expression, like formatting data for readability and parsing HTML pages. Finally, patterns can be used to specify where something is within a string and extract that part of the string.
dBL, of course, includes a number
of string functions that can be used to solve searching, extracting, or
replacing problems. Regular expressions are a powerful tool not because
they can match a pattern, but because they can match patterns that depend
on exactly how and where a pattern exists within a string. Their power
is found when you have complex matching problems or when you have large
amounts of text to process. This is quite a claim, I know, but the purpose
of this paper is to give you some idea why it is made.
VBScripting
and dBL
dBASE does not have built-in support for regular expressions. Nevertheless, a robust regular expression implementation is available to a dBL program through the VBScripting Engine. Regular expression support was added to Version 5 of the VBScripting Engine. It is very likely that you have this software already installed on your computer. Version 5, or a later version of the engine, is installed with the following Microsoft products1:
|
^.+@[^\.].*\.[a-z]{2,}$ |
|
Dont worry if this makes no sense
right now. The following mathematical expression would look just as bizarre
if you didnt know the meaning of the symbols like
* / ^ + () [].
|
p = [m*(1+r)]/[x-(1+r)*a]^2 |
|
VBScript encloses a regular expression
with double quotes, while most other programming languages that support
regular expressions enclose them with forward slashes. The following expression
is formatted for VBScript:
In Perl or JavaScript the same
expression would be formatted like this:
The internet contains quit a lot
of information about regular expressions. Most of the examples, however,
are written for languages other than VBScript. Adapting an examples from
JavaScript or Perl to VBScript is easy when you understand a bit about
the small variations among the languages.
|
||||||||||
The Second component for working with regular expressions through the VBScripting Engine is the RegExp object. This is used for actually processing the expression or pattern. Here the VBScripting Engine is rather different from other languages that support regular expressions. Perl processes regular expressions with commands and command line parameters. There are no objects, properties, or methods involved. JavaScript, on the other hand, processes regular expressions with objects, but the object model is quite different from the one found in the VBScripting Engine. If you are familiar with the JavaScript regular expression objects, you will find some similarities, but also some differences with the VBScripting Engine.
This paper begins with a discussion
of the VBScripting Engines RegExp object.
That discussion will be followed by a discussion of the regular expression
metacharacters and their syntax. The paper will next discuss a number of
examples for using regular expression in a dBL program. Finally, I will
review a few regular expression tools that you may wish to use.
The
RegExp Object
The VBScripting Engine is one of the components of the Microsoft Windows Scripts. The other components include JScript, Windows Script Components, Windows Script Host, and Windows Script Runtime. The most recent versions of this software can be downloaded from Microsofts web site free of charge.
The regular expression support
that we are interested in using is found in the file
vbscript.dll. When you
deploy an application that exploits regular expressions, you will need
to include a copy the file vbscript.dll
on
the target computer and register it with the following command line:
|
regsvr32 vbscript.dll |
|
If you use the Microsoft Windows Scripts installation package, the DLL will be registered for you. You should also note that many versions of Microsoft Windows and Internet Explorer include these scripting engines, so it is very likely that you will not need to install them.
The VBScripting Engine provides
regular expressions as an object to developers. The VBScript RegExp object
is similar to JScripts RegExp and
String objects but it also has some important differences. Lets begin
with a simple program and use it to describe the properties and methods
of the RegExp object.
The simplest use of a regular expression is to match a literal pattern.
In the following example, we will look for a pattern (a) in a string
(aoAoa). When the test() method
finds a match, the replace() method
is used to substitute an x for the a.
|
cString = "aoAoa" cPattern = "a" oRegExp = new OLEAutoClient("VBScript.RegExp") oRegExp.global = true oRegExp.ignoreCase = true oRegExp.pattern = cPattern if oRegExp.test( cString ) newString = oRegExp.replace(cString,"x") endif ? "newString = " + newString // result is "xoxox" |
|
In dBL, the
RegExp object is accessed
with the OleAutoClient() method.
|
oRegExp = new OleAutoClient("VBScript.RegExp") |
|
After this is done, the above code sets three properties. In fact, these are the only properties provided by the VBScript RegExp object. The following is a description of each properties.
|
cString = "Is it better to be; or is it better not to be?" cPattern = "be" oRegExp = new OleAutoClient("VBScript.RegExp")
// create a matches collection
? aMatch.count
|
|
The Match object provides access
to the properties of a regular expression match. The only way a Match object
can be created is by using the Execute()
method
of the RegExp object.
All Match object properties are read-only.
|
aMatches = oRegExp.Execute( cString ) |
|
When a regular expression is executed, zero or more Match objects can result. Each Match object provides access to the string found by the regular expression, the length of the string, and an index to where the match was found.
A match found for a pattern may be called a full match. It is possible to divide the pattern into so-called subpatterns. A search with a pattern containing subpatterns will result in a full match. From this full match it is possible to identify the matches resulting from each subpattern, such matches are called submatches.
The concept of submatches was introduced with version 5.5 of VBScript. The properties of the individual submatches are contained in a SubMatches collection which is created by using the Execute() method of the RegExp object. The SubMatches collections properties are read-only.
If you havent worked with Microsoft collections they can be a bit confusing at first. The following diagram illustrates the relationship between the matches collection and the submatches collections.
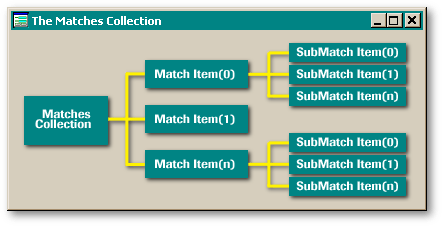
When a regular expression search
is executed against a string, zero or more submatches can result when parts
of the pattern are enclosed in capturing parentheses. For example, the
following pattern will match any number of word characters followed by
a comma, a space and then any number of word characters. The two sets of
word characters are enclosed within parentheses, and are therefore captured
as submatches.
|
cPattern = "(\w+)\,\s+(\w+)" cString = "Nuwer, Michael" |
|
The first submatch captures whatever
is found inside the first set of parentheses and the second submatch captures
whatever is found inside the second set of parentheses. In this example,
therefore, the first submatch is Nuwer and the second is Michael. Among
other things, submatches enable you to rearrange parts of the full or master
match. For example, I can rearrange the contents of cString into Michael
Nuwer with the following:
|
cFullName = oMatch.item(0).SubMatches.item(1) + ; space(1) + ; oMatch.item(0).SubMatches.item(0) |
|
There are only two properties of
a submatches item. First is the value, which contains the captured text.
However, for some reason you do not read this with the name of the property.
In other words, this does not work:
|
oMatch.item(0).SubMatches.item(0).value |
|
While this does:
|
oMatch.item(0).SubMatches.item(0) |
|
The second property is the length
of the submatch:
|
oMatch.item(0).SubMatches.item(0).length |
|
This property is useful when you want to manipulate text using other string methods or functions.
Submatches are very closely associated with the concept of backreference as it is used in regular expressions. I will have more to say about backreferences in the next section of this paper.
Now I will consider the syntax
of a regular expression.
Writing
Regular Expressions
An expression used to construct a pattern consists of ordinary characters (for example, letters a through z) and special characters, known as metacharacters. The expression serves as a template for matching a pattern against a string. Regular expressions are constructed in the same way that arithmetic expressions are constructed. That is, small expressions are combined using a variety of metacharacters and operators to create a larger expression.
Significant programming power comes
from the way regular expressions allow you to include specifications for
such things as the type of characters to accept in a match, how the characters
are surrounded within the string, and how often a type of character can
appear in the string. A series of metacharacters handle most of the issues
regarding character types, while punctuation and grouping symbols help
define issues regarding frequency and range. By creating patterns to match
against specific strings, a developer can gain considerable control over
searching, extracting, or replacing data.
Character
Matching
Most characters in a pattern template simply match themselves. If you string several characters in a row, they must match in order. Some characters however, are metacharacters, and do not match themselves. To match these characters literally you must place a backslash in front of them. The backslash when used in this way is called an Escape character. For example, \\ matches a backslash and \$ matches a dollar-sign. Heres the list of metacharacters used in regular expressions. The escape character must be used to match any of these: \ | ( ) [ ] { } ^ $ * + ? .
A backslash also turns an alphanumeric character into a metacharacter. So whenever you see a backslash followed by an alphanumeric character, \d \D \w \W \t \s \3, youll know that the sequence matches something strange.
In addition to literal matches,
you can use a variety of symbols to represent a pattern. The following
table contains a list of symbols that can be used in patterns.
| Character | Description |
|---|---|
| . | Matches any single character except a newline character. |
| [xyz] | A character set. Matches any one of the enclosed characters. For example, "[abc]" matches the "a" in "plain". |
| [^xyz] | A negative character set. Matches any character not enclosed. For example, "[^abc]" matches the "p" in "plain". |
| [a-z] | A range of characters. Matches any character in the specified range. For example, "[a-z]" matches any lowercase alphabetic character in the range "a" through "z". |
| [^m-z] | A negative range characters. Matches any character not in the specified range. For example, "[m-z]" matches any character not in the range "m" through "z". |
| \d | Matches a digit character. Equivalent to [0-9]. |
| \D | Matches a non-digit character. Equivalent to [^0-9]. |
| \w | Matches any word character including underscore. Equivalent to "[A-Za-z0-9_]". |
| \W | Matches any non-word character. Equivalent to "[^A-Za-z0-9_]". |
| Non-Printable Characters | |
| \f | Matches a form-feed character. |
| \n | Matches a newline character. |
| \r | Matches a carriage return character. |
| \t | Matches a tab character. |
| \v | Matches a vertical tab character. |
| \s | Matches any white space including space, tab, form-feed, etc. Equivalent to "[ \f\n\r\t\v]". |
| \S | Matches any nonwhite space character. Equivalent to "[^ \f\n\r\t\v]". |
| \cx | Matches the control character indicated by x. For example, \cM matches a Control-M or carriage return character. The value of x must be in the range of A-Z or a-z. If not, c is assumed to be a literal c character. |
| \n | Matches n, where n is an octal escape value. Octal escape values must be 1, 2, or 3 digits long. For example, "\11" and "\011" both match a tab character. "\0011" is the equivalent of "\001" & "1". Octal escape values must not exceed 256. If they do, only the first two digits comprise the expression. Allows ASCII codes to be used in regular expressions. |
| \xn | Matches n, where n is a hexadecimal escape value. Hexadecimal escape values must be exactly two digits long. For example, "\x41" matches "A". "\x041" is equivalent to "\x04" & "1". Allows ASCII codes to be used in regular expressions. |
| Quantifiers | |
| * | Matches the preceding character zero or more times. For example, "zo*" matches either "z" or "zoo". |
| + | Matches the preceding character one or more times. For example, "zo+" matches "zoo" but not "z". |
| ? | Matches the preceding character zero or one time. For example, "a?ve?" matches the "ve" in "never". |
| {n} | n is a nonnegative integer. Matches exactly n times. For example, "o{2}" does not match the "o" in "Bob," but matches the first two os in "foooood". |
| {n,} | n is a nonnegative integer. Matches at least n times. For example, "o{2,}" does not match the "o" in "Bob" and matches all the os in "foooood." "o{1,}" is equivalent to "o+". "o{0,}" is equivalent to "o*". |
| {n,m} | m and n are nonnegative integers. Matches at least n and at most m times. For example, "o{1,3}" matches the first three os in "fooooood." "o{0,1}" is equivalent to "o?". |
| Anchors | |
| \b | Matches a word boundary, that is, the position between a word and a space. For example, "er\b" matches the "er" in "never" but not the "er" in "verb". |
| \B | Matches a non-word boundary. "ea*r\B" matches the "ear" in "never early". |
| ^ | Matches the beginning of input. |
| $ | Matches the end of input. |
| (pattern) | Matches pattern and remembers the match. The matched substring can be retrieved from the resulting Matches collection. To match parentheses characters ( ), use "\(" or "\)". |
| x|y | Matches either x or y. For example, "z|wood" matches "z" or "wood". "(z|w)oo" matches "zoo" or "wood". |
| \num |
Matches
num,
where num is a positive integer. A reference back to remembered
matches. For example, "(.)\1" matches two consecutive identical characters. |
The period . (period or dot) is the most versatile of the metacharacters. It matches any single printing or non-printing character in a string, except a newline character \n. For example, b.t matches bat, bit, bet and so on. If you are trying to match a string containing a period, like a file name (plus.exe) or an internet address (dbase.com), you do so by preceding the period in the regular expression with a backslash \. character.
You can create a list of matching characters by placing one or more individual characters within square brackets []. When characters are enclosed in brackets, the list is called a Character Class. Within brackets, as anywhere else, ordinary characters represent themselves, that is, they match an occurrence of themselves in the input text. So [AN]BC matches ABC and NBC but not BBC since the leading B is not in the set. Most special characters lose their meaning when they occur inside a character class.
If you want to express the matching characters using a range instead of the characters themselves, you can separate the beginning and ending characters in the range using the hyphen - character. For example, [abc] or [a-c] matches a, b, or c; while [a-zA-Z0-9] matches all alphanumeric characters when used with an English alphabet. For other alphabets having alphanumric characters at codepoints above 122 you will have to construct your own pattern to achive the same purpose.
You can also find all the characters
not in the list or range by placing the caret ^ character at the beginning
of the list. If the caret character appears in any other position within
the list, it matches itself, that is, it has no special meaning. For example,
[^AN]BC will match BBC or CBC but not ABC or NBC. The caret used
within a character class should not be confused with the caret that denotes
the beginning of a string (to be discussed below). Negation is only performed
within the square brackets.
Quantifiers
Sometimes, you dont know how many characters there are to match. In order to accommodate that kind of uncertainty, regular expressions support the concept of quantifiers. These quantifiers let you specify how many times a given component of your regular expression must occur for your match to be true.
Quantifiers say how many of the previous substring should match in a row. For example, the + matches one or more occurrences of the previous character or substring. Thus, fe+d matches both fed and feed but not fd. The * matches zero or more occurrences of the previous character or substring. In this case, fe*d matches fed, feed and fd. Then there is the ? quantifier, which matches zero or one occurrence of the previous character or substring. fe?d matches fd or fed but not feed.
Users of regular expressions find that the most common usage of these quantifiers +*? are in combination with word symbol. For example, \w+ means one or more occurrence of any alphanumeric character, while \d* means zero or more occurrences of a numeric digit. \D+[-._]\D+ one or more alphabetic characters (\D means not numeric characters), a dash or a period or an underline, then one or more alphabetic characters.
Quantifiers can also specify exactly how many of the previous character or substring you want to match. For example, \d{5} matches exactly five digits, while \s{2,} matches at least two white space characters. Thus if you want to match a North American phone number you might use \d{3}-\d{4}; or if you want to exclude the 555 prefix (nobody really has a phone number with this prefix) from the number you might use [1-46-9]{3}-\d{4}
Parentheses may be used to group strings together to apply ?, +, or * to them as a whole. ba(na)+na for example, matches banana and banananana, but not bana or banaana. Additionally, (abc){2} will match abcabc.
Quantifiers can be tricky to use when a string contains two possible matches. Say the string is The food is under the bar in the barn and your pattern is foo.*bar. In this case the match will be food is under the bar in the bar. This is because the * and ? quantifiers are what is called greedy, which means they match as much text as possible. So you get everything between the first foo and the last bar. Sometimes, however, thats not what you want to happen.
Sometimes, you just want a minimal
match, and thus its more effective to use minimal matching to make sure
you get the text between a foo and the first bar. Minimal matching
is done by combining the *? so foo.*?bar will match food is under
the bar.2
Anchors
Anchors are used when you need to match characters based on their position in a string. Normally when a pattern is matched against a string, the beginning of the pattern is dragged through the string from left to right. Anchors allow you to ensure that parts of the pattern line up with particular parts of the string. Anchors allow you to fix a regular expression to either the beginning or end of a line. They also allow you to create regular expressions that occur either within a word or at the beginning or end of a word.
The first type of anchors require that a particular part of the pattern be at the start or the end of the string. The caret ^ matches the beginning of the string. For example, ^The matches The in The night but not In The Night. However, The^ matches this literal pattern anywhere in the string because the caret has lost its special meaning. If you need the caret to be a literal caret at the beginning of the pattern, you must use the backslash like this: \^The
The dollar sign $ anchors the pattern to the end of the string. For example, and$ matches and in Land but not landing. A dollar sign anywhere else in the pattern will be interpreted as a literal value. Anchors do not exist as characters themselves, but exist as a property of the surroundings. For example, using $ to match the end of a line does not match a carriage return or new line. It matches that special nothing that indicates the end of a line.
The next anchor type requires that a particular part of the pattern be located at the beginning or end of a word, which is known as a word boundary. The position of the \b operator is critical here. If its positioned at the beginning of a string to be matched, it looks for the match at the beginning of the word; if its positioned at the end of the string, it looks for the match at the end of the word. For example, \bor matches or in origami but not normal and al\b matches al in normal by not all.
You cannot use a quantifier with an anchor. Since you cannot have more than one position immediately before or after a newline or word boundary, expressions such as ^* are not permitted.
| The VBScripting
RegExp object includes
an undocumented property that can influence the way anchors work. The
multiline property is
a Boolean value.
The multiline flag allows the search to be performed on multiline strings. This can be useful when the string is a large memofield or a complete text file. In these cases, the expression is tested against each line as if each line is a separate string. If
multiline is
false, ^ matches the
position at the beginning of a string, and $ matches the position at
the end of a string. If multiline is
true, ^ matches the
position at the beginning of a string as well as the position following
a \n (chr(10)) or \r (chr(13)), and $ matches the position at the
end of a string and the position preceding \n or \r.3
|
||
When constructing regular expressions you will often wish to group characters so that they are considered as a single entity. This is done with the use of parentheses. Grouping characters together creates a clause in much the same way parentheses are used in a mathematical expression. Also like a mathematical expression, a regular expression clause may be nested within another clause.
The following expression contains two grouping clauses: (abc)+(def) The expression matches one or more occurrences of abc followed by one occurrence of def. Notice that the plus sign quantifier applies to the whole clause. That is, without the parentheses, abc+ will match abccc, while (abc)+ will match abcabc.
The other reason for grouping characters is to add an OR logic to your pattern matching.
Alternation uses the pipe | character to allow a choice between two or more alternatives. Alternation combines clauses into one regular expression and then matches any of the individual clauses. It is similar to an OR statement. For example, Mike|Michael will match either of these two names.
Often you need to use parentheses
to limit the scope of the alternation. For example, w|food will match
w or food but (w|f)ood will match wood or food. This next expression
(ab)|(cd)|(ef) will match ab or cd or ef.
Parentheses
as memory
Parentheses have another important function in a regular expression. The match inside the parentheses is stored in special memory variables so that it can be used by other parts of the regular expression engine. This means that an expression like (\w)+\sFlintstone will match Fred Flintstone and Wilma Flintstone, and it also means that the first name in the match is stored in memory.
Most regular expression implementation store up to nine submatches in variables $1, $2, $9. The actual values are determined by counting opening parentheses from left to right in the expression. For example, the following expression (a(bc))(ef) will store abc in $1, bc in $2 and ef in $3.
The following code, for example,
uses capturing parentheses to reverse a last name and first name:
|
cString = "Flintstone, Fred" cPattern = "(\w+),\s*(\w+)" oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.pattern = cPattern ? oRegExp.replace(cString, "$2 $1") // Fred Flintstone |
|
In the VBScript regular expression object the parenthesized memory variables are recognized only within the object. They cannot be referred to elsewhere in your code. However, the submatches collection contains the same values and these are accessible outside the RegExp object. This was discussed earlier in this paper.
Other useful read-only variables are:
When a regular expression
is processed by a scripting engine, grouping and anchoring patterns have
precedence just like operators. The following table gives the precedence
of patterns used in regular expressions from highest to lowest.
According to this table, the expression \d|[a-z]* will evaluate to a single digit or any number of alphabetic characters. This is because the quantifier is evaluated before the alternation (i.e. * before | ). If, however, parentheses are added such that the expression becomes: (\d|[a-z])*, then it evaluates to any digits or alphabetic characters zero or more times. In this case the expression inside the parentheses is evaluated before the quantifier.
|
||||||||||
When a parenthesized portion of a pattern is matched and stored in memory it can also be used to complete a search. This is called backreference. Backreferencing lets you reuse a parenthesized match inside the regular expression. This is useful when you need to refer back to a subexpression in the same regular expression. You would do this when one match is based on the result of an earlier match.
A simple example of a backreference is when you need to find a word that is repeated twice in a row. (\w+)\s+\1 matches such a pattern, for example, hubba hubba. The \1 denotes that the first word after the space must match the portion of the string that matched the pattern in the parentheses. If there were more than one set of parentheses in the pattern string you would use \2 or \3 to match the appropriate grouping to the left of the backreference. Up to nine backreferences can be used in a pattern string.
Because backreference can be a
bit confusing at first, a few examples may be helpful. First, suppose you
want to match the opening and closing pair of an HTML tag but that you
dont necessary know the tag name.
|
cString = "<strong>Help</strong>" cPattern = "<([a-z][a-z0-9]*)[^>]*>(.*?)</\1>" |
|
When the above expression is dragged across the contents of cString, the opening HTML tag is matched and strong is stored in the first backreference. The expression processing engine then substitutes this backreference for the metacharacter \1 to find the close of the tag. (note: This regular expression will not match tags nested in themselves.)
Heres another example. Say you
are willing to accept a date in either of two formats, dd-mm-yy or dd/mm/yy,
but you do not want to accept dd-mm/yy. In this case the separating character
must be the same between dd and mm as it is between mm and yy. To check
this, we can use the following regular expression
|
"\d{2}([\.\-\/])\d{2}\1\d{2}" /*
|
|
Notice that although the separator is the second pattern match (the first being the two digits), we select \1 because the separator was the first pattern matched inside of the parentheses.
Sometimes you need to use parentheses
for grouping the parts of an expression but you do not want the contents
captured. To prevent the match from being saved for later use, place ?:
before the regular expression pattern inside the parentheses.
The following expression for a simple email address will ensure that the
last three characters are anchored to the end of the string without saving
the submatch:
|
\w+\@\w+\.(?:edu|org|net|com)$ |
|
The foregoing review of the regular
expression syntax should give you some idea of the power and flexibility
of this tool. The next part of this paper will discuss a series of coding
examples. These examples are intended to give you an idea of the type of
problems regular expression can address. They also will provide examples
of actual expressions with multiple clauses.
Is
there a match?
The first set of examples focus on testing whether a regular expression (or pattern) matches a string. This question returns a value of true if the match is found or false if the match is not found. In many development languages such a test is used to validate user input. In a dBL program input validation is not particularly problematic. For this reason, a dBL developer may choose not to use regular expressions for this purpose. I will, nevertheless, provide an example because there are some situations where using a regular expression is an efficient way to validate user input.
Another use for testing a regular expression match is when you need to search large amounts of text. This could be the text in a memofield or it could be the contents of plain text or HTML files. In this section I provide example code that searches a memo field for specific text.
Example No. 1
For the first example I will test whether a set of numbers is properly formatted as a North American telephone number. For some developers, one of the desirabilities of regular expressions is that multiple patterns can be tested. In this example any of the following telephone number formats will pass the validation test:
|
clear // create an array with some data to process a = new array() // valid formats a.add("234 555-1234") a.add("(121) 555-2123") a.add("(112)555-0101") a.add("(123) 555 1234") a.add("123 5551234") a.add("1235551234") // not valid formats a.add("034 555-1234") a.add("(121) 055-2123") a.add("(112) 5555-0101") a.add("(1234) 555 1234") a.add("123 55512345") a.add("12355512345") // define the regular expression
for i = 1 to a.size
|
|
To help you see what the regular
expression is doing, the following table explains each part of the regular
expression.
| Regular Expression | Description |
| ^ | allow no whitespace at front |
| \(? | the open parenthesis"(" is escaped by the backslash "\"; the question mark "?" means it is optional |
| ([1-9]\d{2}) | the parentheses define the first subpattern. In that pattern we are looking for one digit character from 1 to 9 (a 0 will not match) followed by two digit characters. |
| \)? | optional end parenthesis |
| \s? | optional white space |
| ([1-9]\d{2}) | second subpattern one digit char from 1-9 and two others |
| [-\s]? | a hyphen or a space, also optional |
| (\d{4}) | third subpattern is a digit character exactly four time. |
| $ |
allow no white space
at end |
This expression requires that the pattern match is made at the beginning of the input string (by using the caret ^). Im doing this to ensure that there are no leading spaces in the string, but its useful only when the entire string is being evaluated. The same point can be made about the ending anchor ($). If you want to find one of these phone number patterns in a memo field, the expression would never find a match. A better approach when searching a memofield is to remove the two anchoring metacharacters4.
Example No. 2
This example creates a query object
for the Fish table included with dBASE PLUS in
Samples folder. After
the query is active, the regular expression object will be used to find
all records in which Mexico or Indo-Pacific is present in the memo
field.
|
d = new database() d.databasename = "dbasesamples" d.active = true q = new query() q.database = d q.sql = 'select * from fish' q.active = true cPattern = "(Mexico|Indo-Pacific)"
aFound = new Array()
for i = 1 to aFound.size
|
|
Example No. 3
My next example will use a regular
expression to set a filter on a memo field. For many situations a SQL select
clause like the following will make a nice filter.
|
select * from "myTable.dbf" where mymemo like '%search_string%' |
|
However, if you need a rowset that can be edited, or if the case of the search_string is problematic, or if the search_string could have odd punctuation, then a regular expression might be helpful. A message thread in dataBased Intelligence newsgroups, for example, notes the complexity of searching a memo field for income tax, which could be entered as Income Tax or income tax or Income-tax or Income-Tax and so on. The expression income[ -]tax, along with the ignoreCase property, will match all of these possibilities.
The following code example uses
the rowsets canGetRow() event
handler to set a filter on the memo field of the Fish table.
|
d = new database() d.databasename = "dbasesamples" d.active = true q = new query() q.database = d q.sql = 'select * from fish' q.active = true cPattern = "(Mexico|Indo-Pacific)"
q.rowset.canGetRow = rsCanGetRow
Function rsCanGetRow
|
|
Comment: The above code runs fine from within a program file, however, you may need to make some modifications to run a similar routine within a form. Id suggest creating the RegExp object (oRegExp) in the onOpen() event handler of the query object and assigning it as a property of the query object. [See FishSample1.wfm in the file archive for a working example.]
In the preceding three examples,
a regular expression was used to test whether a pattern exists within a
string. That string might be a small amount of form data or it might be
a much larger amount of text contained in a memo field. The examples demonstrate
how using a regular expression might validate user input and search or
filter a memo field.
Getting
information about a match
Using a regular expression to test for a match barely scratches the surface of their functionality. When the regular expression object finds one or more matches in a test string, it stores information about the match. Different regular expression implementations do this differently. The Microsoft RegExp class stores the information in the Matches collection. In the next few examples, I will get and use information about the match.
Example No. 1
The next example will open a source
code file for a dBL form (specifically, the
Scheduler.wfm which is
included in the Contax sample application), and find all instances of a
Text, Entryfield, or Pushbutton object. The matches will be stored in the
matches collection. The example will then loop through that collection
to count the number of times each of the three object types is created,
streaming the results to the Command window.
|
cFile = _dbwinhome + "Samples\Contax\Scheduler.wfm" f = new file() f.open(cFile, "R") cString = f.read(f.size(cfile)) oRegExp = new OleAutoClient("VBScript.RegExp")
// create a matches collection
// create and initialize a counts array
// display results
|
|
Example No. 2
The next example uses a regular
expression to construct a calculated field. The code will search a memo
field for a pattern and store the match in a calculated field. The example
uses the Fish table from the dBASE PLUS samples folder. The memofield in
that table includes information about the edibility of a fish in the database.
The regular expression will be used to extract that information and add
it to the calculated field.
|
d = new database() d.databasename = "dbasesamples" d.active = true q = new query() q.database = d q.sql = 'select * from fish' q.onOpen = qOnOpen q.active = true cPattern = "Edibility.*\."
do
Function qOnOpen
Function fBeforeGetValue
|
|
Comment: I noted in the example regarding the canGetRow() filter that modifications would be needed to made to the above code if you want to run a similar routine within a form. The file archive includes FishSample2.wfm which is a working example of creating a calculated file in a form.
Example No. 3
In the next example we use the
firstIndex and
length properties to manipulate
a string. The string contains internet URLs, but without the appropriate
protocol. For the example string, the regular expression will find two
different internet addresses. The code will then loop through the matches
collection and insert the protocol in front of each address. Notice that
the FOR loop
steps backwards through the matches collection. This has the effect of
manipulating the string from right to left, which is necessary in order
to preserve the true position of the firstIndex
values.
|
oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.Global = true oRegExp.IgnoreCase = true cString = "If you comply with regular expression, " cString += "go to www.regexp.com or www.re.com." oRegExp.Pattern = "www.\w+\.\w+" aMatches = oRegExp.Execute(cString)
/*
cString = cTemp
|
|
The find and replace abilities of regular expressions are both powerful and flexible. In the next few examples I will use some rather straight forward find and replace operations. That is, when a match is found, it is replaced with a pre-determined value. For example, all instances of Mike would be replaced with Michael.
Example No. 1
The first example will clean unwanted
characters from a string. The expression used in this example states that
the acceptable characters are alphabetic, digits, white space, underscore,
dash, or dot. The replacements are accomplished by matching the negation
of these characters. In other words, anything other than an acceptable
character will match the expression and be replaced with an empty string.
The example then uses the replace() method
to substitute an empty string for all matches.
|
cString = "are: we' in; the [correct] pla*ce?" oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.global := true oRegExp.Pattern := "[^\w\d\s\_\-\.]" ? oRegExp.Replace(cString , "" ) |
|
Example No. 2
The second example is a common
problem for web applications. It will URL-encode any non-alphanumeric character
found in a string, that is it will replace all non-word characters with
a % sign followed by the hexadecimal value of the respective character.
Notice that the FOR loop
is stepping from high to low. As noted above, this is to preserve the positions
of the firstIndex property.
|
cString = "the_at-sign@&The Question Mark?" oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.global := true oRegExp.pattern := "[^\w\d]" oMatches = oRegExp.execute( cString )
|
|
Example No. 3
Some times you might want to retrieve
an HTML file and display its content without the HTML tags. The third example
will strip all HTML tags from a string of text. It will also replace any
excessive white space in the file.
|
cPattern = "<[^>]+>" cString = '<B>This <I>is</I> <TT style="background-color: rgb(0,255,255)">; some</TT> <FONT COLOR=#FF00FF> HTML</FONT></B>' oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.global = true oRegExp.pattern = cPattern cString = oRegExp.replace(cString , "" ) // remove extra spaces oRegExp.pattern = "\s\s+" ? oRegExp.replace(cString , " " ) |
|
For some developers the most powerful feature of regular expressions is their ability to make submatches (or capturing parenthesized matches). With this feature a developer can match patterns and rearrange their parts to produce a new string.
Example No. 1
The first example of this feature
will return to the Scheduler form. In an earlier example I showed how to
find all the occurrences of three pre-defined objects. In that case I looked
for Text or Entryfield or Pushbutton. However there are cases where the
class name is not known in advance and there would be no way to pre-define
the objects. The following example will find and count all the class names
in the Scheduler form. The regular expression uses a set of capturing parentheses
to store the class name as a submatch. It is that name which is added to
the aCount array.
|
cFile = _dbwinhome + "Samples\Contax\Scheduler.wfm" f = new file() f.open(cFile, "R") cString = f.read(f.size(cfile)) oRegExp = new OleAutoClient("VBScript.RegExp")
// create a matches collection
aCount = new AssocArray()
|
|
Example No. 2
The next example will test a date
and extract its component parts. In addition the parts are rearranged.
This example assumes the data format is MDY.
|
cString = "01/21/2004" cPattern = ; "\b(1[0-2]|0?[1-9])[-/](0?[1-9]|[12][0-9]|3[01])[-/]((19|20)\d{2})" oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.global = true oRegExp.pattern = cPattern if oRegExp.test( cString )
|
|
The expression used in the above example is intended to accept any date that is in one of the following formats:
|
"\d{1,2}[-/]\d{1,2}[-/]\d{4}" /* Where a string contains: At least one and no more than two digits "\d{1,2}"; followed by a dash or a slash "[\-\/]"; followed by one or two digits (again); followed by a dash or a slash (again); followed by exactly four digits. */ |
|
Although that expression will match
any date just fine, it will also match (20/40/4000) as if it were a valid
date. This is an example of the tradeoff between simplicity and exactness.
Whether this is a problem depends on the data you intend to compare against
this expression. A more exact, but also more complex expression for the
date is:
|
"\b(1[0-2]|0?[1-9])[-/](0?[1-9]|[12][0-9]|3[01])[-/]((19|20)\d{2})" /*
(1[0-2]|0?[1-9])
[-/] A dash or a slash (0?[1-9]|[12][0-9]|3[01])
[-/] Same as above, a dash or a slash. ((19|20)\d{2})
|
|
Example No. 3
The next example will take the
foregoing one more step and add code to evaluate whether the date is actually
valid. In addition, this example is written as a function since that is
often the way one would validate user input.
|
? isValidDate("02/29/2004") Function isValidDate( cDate )
|
|
Example No. 4
The next example will use multiple
patterns to format an email address and extract the account and the host
server name.
|
oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.ignoreCase = true oRegExp.global = true cString = "< michael.nuwer@mail.potsdam.edu>" // Remove Brackets
// Trim leading and trailing white space
oRegExp.pattern = "^(.+?)\@(.+?)$"
cAccount = oRegExp.replace( cString, "$1" )
|
|
Example No 5
The last example of extracting
information from a match looks for an email address in a string and captures
three components of the address.
|
cString = "Please send mail to dragon.me@home.xyzzy.com. Thanks!" oRegExp = New OleAutoClient("VBScript.RegExp") oRegExp.Pattern = "(\w[-._\w]*\w)@(\w[-._\w]*\w)\.(\w{2,3})" oMatches = oRegExp.Execute(cString) // make a reference to the first item in
the Matches collection
// The Match object is the entire match
|
|
SubMatches are also useful for
formatting matches or parts of a match. The first example will add comma-separators
to a very large number. This example uses a loop to test whether a string
of digits is greater than three. If there are more than three consecutive
digits, the string is formatted by adding a comma. The test is continued
in the loop until the the pattern does not match.
|
cString = "1000000000" cPattern = "(-?\d+)(\d{3})" oRegExp = new OleAutoClient("VBScript.RegExp")
|
|
The next example formats a list
of international phone numbers.
|
a = new array() a.add("+1234 1234 12345-1234") // maximum digits a.add("+12 12 123") // minimum digits a.add("012 12-0") // national format a.add("+49 9131 12345") a.add("+49 89 12345-99") a.add("09131 12345-9898") a.add("+244 131 12345-9898") a.add("089 12345") cPattern = "(\+\d{2,4}|0)\s?(\d{2,4})\s?(\d{2,7})(-| )?(\d{4})?"
? "Before"
|
|
The archive file contains a file named RegExpString.cc. This is a custom class which extends the dBL string class by adding four methods that support regular expressions. The methods are modeled after four JavaScript methods by the same names.
Each of the four methods take a regular expression as a parameter. The expression must be formatted as a string enclosed in quote marks. In JavaScript a regular expression can be instructed to apply a global match or a case-insensitive match by adding a modifier to the end of the expression. Modifiers are considered part of the regular expression and are placed at the end of pattern preceded with a forward slash. Thus to/g is a global search for the pattern to; to/i is a case-insensitive search for the pattern to; and to/gi is a global, case-insensitve search for the pattern to. A leading slash is not necessary in the parameters and, if included in the expression, it will be treated as part of the search pattern.
Executes
a search for a match within a string based on a regular expression (or
pattern). Returns an array when at least one match is found, otherwise
the return value is null.
Each element in the array is a copy of the string segment that matches
the specification of the regular expression. You can use this method to
uncover how many times a substring or sequence of characters appears in
a larger string.
|
oStr = new RegExpString( ) oStr.String = "IS1 is2 IS3 is4" x = oStr.match( "is./gi" ) for i = 1 to x.size ? x[i] next |
|
Replaces
the matched part of the string with a new string. If no match is found
the string remains unchanged. Returns the changed string.
|
x = "be" oStr = new RegExpString( ) oStr.String = "To be, or not to be: That is the question:" oStr.String += "Whether 'tis nobler [better] in the mind to suffer" ? oStr.replace( x+"\b/gi", "%"+ x +"%" ) |
|
Returns an offset integer for
the start of the matched text in the string. Returns
-1 if no match is found.
The second parameter, nIndex,
specifies which occurrence of the match to find. If no value is specified,
the search looks for the first occurrence of the regular expression. You
can search for other occurrences by specifying a number greater than zero.
Note: the value of nIndex is
zero based; the first index is 0,
the second is 1 and
so on.
|
oStr = new RegExpString( ) oStr.String = "To be, or not to be: That is the question:" oStr.String += "Whether 'tis nobler [ better ] in the mind to suffer"// 0 based index ? oStr.search( "\bbe/gi", 2 ) |
|
By combining the match and the
search methods you can obtain the basic information about each match in
the search string. This example also illustrates the danger of applying
a pattern containing \w* uncritically to a string containing accented
characters. If the word better is replaced with bettér, then
the third match will be bett instead of better and have a length of
four instead of six.
|
cRegExp = "\bbe\w*\b/gi" oStr = new RegExpString( ) oStr.String = "To be, or not to be: That is the question:" oStr.String += "Whether 'tis nobler [better] in the mind to suffer" x = oStr.match( cRegExp ) for i = 1 to x.size ? x[i] ?? "offset: " + oStr.search( cRegExp, i-1 ) at 10 ?? "length: " + x[i].length at 25 next |
|
Splits a long string into pieces
(or fields) delimited by a specific pattern. Returns an array with the
pieces or field values. The regular expression defines the separator.
|
oStr = new RegExpString( ) oStr.String = "1.John,2.Paul,3.George,4.Ringo" x = oStr.split( ",*\d.\b/gi" ) for i = 1 to x.size ? x[i] next |
|
A second custom class included
in the archive file that accompanies this paper is the Validator Class.
It is contained in the file archive that accumpanies this paper. The class
can be used to test whether a string matches a pattern. The patterns are
included in the validator object. You can use the predefined set of patterns
and you can add new patterns as needed. The following code illustrates
the use of the validator class.
|
set procedure to ValidatorClass.cc additive oValid = new Validator() oValid.validate(cString, cType) |
|
The first parameter passed to the validate() method, cString, is the string to be validated. The second parameter is cType. This parameter identifies the validation pattern to be used by the Validator object. The following table enumerates the values for cType and an example of the format.
| cType | Example |
| zipcode | 13676-2376 |
| currency | $1,000.80 |
| time | 09:45 |
| emailaddress | nuwermj@potsdam.edu |
| phonenumber | 123-555-2077 |
| date | 01/01/2004 |
| ssn | 555-00-1234 |
|
ipaddress |
192.168.0.1 |
If you would like to create additional
cTypes to the Validator
class, you can do so by including something similar to the following:
|
cPattern = "^\(?\d{3}\)?\s|-\d{3}-\d{4}$" cPicture = "###-###-####" this[ cType ] = this.createObject(cPattern, cPicture) |
|
cPattern is
the regular expression pattern that will be used to validate the string.
The cPicture parameter
is used when a validation test fails. In that case a message box appears
and this parameter shows the user the correct format.
cType is the name of an
array element and it is the same value that is passed in the
validate() method.
Conclusion
dBL offers a wide array of string functions and contains an integrated string class. Function like AT(), STUFF(), SUBSTR() and LIKE() make it possible to search, replace, and extract information for text and data. But the documentation for these four dBL function is about two pages. Regular expressions are a little more complex. Mastering Regular Expressions, the definitive book on the subject, is 316 pages long and makes references to many magazine articles for more details. Although seemingly daunting to the uninitiated, there are plenty of articles about using regular expressions.
Constructing regular expressions is as much an art as it is a rule. Solutions will be as varied as the problems which they confront. Practice, test with small chunks of data, make small changes to the expression so you can see the result.
This paper was intended as an introduction to using regular expression in dBL programs. It relies on the Microsofts VBScripting Engine, but we also offered a custom class which simulates the JavaScript support for regular expressions. We tried to show a range of possible uses and we endeavored to provide many examples.
Sources
| Host Application | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 5.1 | 5.5 | 5.6 |
| Microsoft Internet Explorer 3.0 |
|
|||||||
| Microsoft Internet Information Server 3.0 |
|
|||||||
| Microsoft Internet Explorer 4.0 |
|
|||||||
| Microsoft Internet Information Server 4.0 |
|
|||||||
| Microsoft Visual Studio 6.0 |
|
|||||||
| Microsoft Internet Explorer 5.0 |
|
|||||||
| Microsoft Internet Explorer 5.01 |
|
|||||||
| Microsoft Windows 2000 |
|
|||||||
| Microsoft Internet Explorer 5.5 |
|
|||||||
| Microsoft Windows Millennium Edition |
|
|||||||
| Microsoft Internet Explorer 6.0 |
|
|||||||
| Microsoft
Windows XP |
|
|
|
|
|
|
|
|
cString = "The food is under the bar in the barn." oRegExp = new OleAutoClient("VBScript.RegExp") oRegExp.global = true ? [The "greedy" pattern]
|
|
|
f = new file() f.create("testFile.txt") c = replicate("abc ", 10) + chr(13)+ chr(10) c = replicate( c , 4) c += chr(13) + chr(10) + chr(13) +chr(10) c = replicate( c , 2) c = left(c,c.length-6) f.write( c ) f.close() run(true, "notepad.exe testFile.txt") f.open("testFile.txt")
f.close()
|
|
Ivar B. Jessen pointed out that the regular expression used in the foregoing example will not reject the following inputs:
|
a.add("121) 555-2123") a.add("112)555-0101") a.add("(121 555-2123") a.add("(112555-0101") |
|
Whether these invalid formats are problematic
depends on how the expression is used. In my case, after the user inputs the data,
unwanted characters like "(- )" are stripped before storing the data. (Stripping
unwanted characters will be demonstrated later in this paper.) Therefore,
the above inputs would not cause a problem. If, however, the above formats will
cause a problem, then the following regular expression should do the job of invalidating them:
|
cPattern = "^((\()([1-9]\d{2})(\))|(\s?)([1-9]\d{2})(\s?))\s?([1-9]\d{2})[-\s]?(\d{4})$" |
|
|
(it is a 11 Kb zipped file) |