Fire. Stone tools. The wheel. Metal tools. The printing press. Electricity. Sliced bread. Computers. And now XML! Thus completes the evolution of mankind. XML represents the pinacle of human achievement. It will revolutionize the world as we know it, preparing the way for the peaceful society predicted in Star Trek.
Actually, you can forget the hype about XML. Its a nice way to pass information between computer systems and to store data but its a pretty simple idea overall. Theres no need to fret that your co-workers and competitors have progressed and have left you in the technological stone age. Theres no need to go back to college or to buy the latest massive tome that teaches XML in 13.5 days.
XML stands for Extensible Markup Language. (Yes, we realize that its not a proper TLA.) Its a normal text file with text data, encapsulated by tags that describe what the data is. The beauty of XML is that it is simple to create, easy for humans to read and can be easily used by disparate software. An XML file can store any text data at all, from the contents of database tables to parameters for a software program.
Simple XML
Play along with me for a moment
while I demonstrate the simplicity of XML. Tell me, dear reader,
what is the name of the character that appears on almost every cover of
MAD magazine? Ill give you one hint: His name starts with Alfred
E. Neuman. Lets create a small xml file to store that information.
Open Notepad and save the following as a
*.xml file:
|
<xml> <name>Alfred E. Neuman</name> </xml> |
|
Congratulations, weve just created an xml file that can store the names of people. Want to store a second name? Just add another line identical to the second line and change the middle part. If you have coded HTML files before then the XML syntax will seem quite familiar.
Tip: You can open an XML file in Internet Explorer to review the data and to make sure its properly formatted.
Now then, XML files can get more
complex than this. For example, lets say that we want to track how
many hours this character has worked today. Well need three pieces
of information: His name, the date and the total hours worked. That
could look something like this:
|
<xml> <name>Alfred E. Neuman</name> <date>2004-01-01</date> <hours-worked>0</hours-worked> </xml> |
|
What do we notice, other than the
fact that Alfred doesnt work very hard? We can add more information
as we need it because XML is a very flexible format for information.
We just need to make sure that each piece of information has a tag before
and after it (even if theyre not on the same line) that clearly describes
it. Well try one more example. This time, I want to track
how many hours Alfred worked compared to how well I worked. That
could look something like this:
|
<xml> <employee> <name>Alfred E. Neuman</name> <date>2004-01-01</date> <hours-worked>0</hours-worked> </employee> <employee> <name>Jamie A. Grant</name> <date>2004-01-01</date> <hours-worked>8</hours-worked> </employee> </xml> |
|
In this case we needed to group the three basic pieces of information together. This was easily accomplished by adding a new employee tag around each section. XML data can be as complex as required if we create new sections and tags for each new group or each new piece of information.
Syntax of XML
XML files should be formatted according to certain standards. What, you didnt think there wouldnt be strings attached, did you? Ill try to summarize the major parts of it.
Tag Names
These are not a rules for XML files but they are generally accepted standards. All of the tags should be in lower case, though the data itself (like Alfreds name) can still be in upper case. Tag names should not include spaces and should instead use dashes to separate multiple words inside a tag.
Open/Close Tags: An XML file should have one opening tab and one closing tag for the entire file, like the <xml> tag in the above examples. Every opening tag should have a corresponding closing tag. There is one twist for this rule and thats that the opening and closing tag can be one tag. For example: <xmltag></xmltag> can also be written as <xmltag/>, although that variation may be less useful.
Special Characters
XML relies on certain characters for the syntax, so XML expects these restricted characters to be represented by codes instead.
These are additions to the normal
open/close tags but anyone familiar with HTML syntax should recognize this.
Simple propeties of a XML tags can be stored within the XML tag itself.
For example:
|
<employee><id>0001</id></employee> |
|
With an attribute this can be written as: <employee id="0001"></employee>
As noted above, the closing tab does not have to be a separate tag, so this could also be written as: <employee id="0001"/>
Comments and CData
Comments can be added to an XML file and work the same way as comments in dBL code. The beginning of a comment section is marked with <!-- and ends with --> . The benefit of these sections is that the regular rules for XML syntax and special characters are ignored within these sections. Special characters can be included in these sections and normal XML tags within these sections are not included when the XML file is read. Likewise, the CData section is marked with <![CDATA[ and ends with ]]> . This section is necessary if code is required for a particular program and it needs to written without consideration for XML rules.
XML Schema
We wont delve into this aspect of XML in this article but suffice it to say that XML Schemas can be created that can be used to validate the contents of an XML file. An XML schema file usually has a *.xsd file extension. With the proper software, an XML Schema file can help create new XML files or validate existing ones, ensuring that the data is the correct type and is in the correct format. This is not a requirement for XML files.
DOM vs SAX
Again, we wont delve too deeply into this aspect of XML theory. These two terms represent two approaches to parsing XML files for use in programs. The DOM (Document Object Model) approach will parse an entire XML file at once, creating the necessary object hierarchy in memory for the entire file. The SAX (Simple API for XML) approach loads the top of the XML hierachy into memory and provides various ways to access specific sections of an XML file. The DOM approach is useful if the XML file is fairly small and all of the contents are needed. The SAX apparoach is more useful when the XML file becomes fairly large or only certain sections of the contents are required. In the case of the sample project included with this article, both of the code samples demonstrated use the DOM approach.
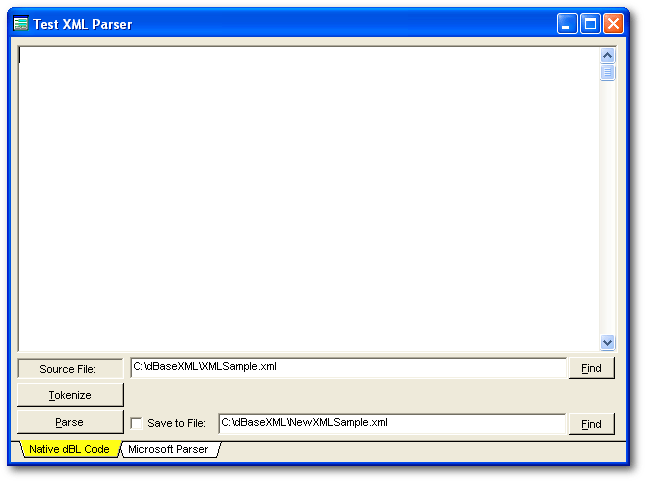
Sample Project
Conceptually, XML often represent a hierachy of data, something like a treeview of information. This article includes a link that demonstrates how to use two different methods to parse an XML file for use in a dBase program. One example demonstrates how to use the XML Parser provided by Microsoft. The second example demonstrates how to use an XML Parser that was written entirely with dBL code.
The Microsoft Parser uses an OleAutoClient object with Msxml2.DOMDocument.4.0 . This parser is distributed along with Internet Explorer so most Windows users will have the necessary software installed on their computers, though the availability of the file may differ between workstations. There are other similar parsers supplied by Microsoft and there are other third-party XML parsers that can be used in dBASE. The object model it creates is fairly complex but the code samples provided should help demonstrate how to use it.
The Native dBL Code uses XMLParser.cc, which is an XML Parser written entirely with dBL code. The Tokenize option reads in an entire XML file and breaks the file into an array of tokens. Each XML tag and each piece of XML data is broken down and each one is stored in the array. From there, the Parse function organizes and groups the tokens into a hierarchy of objects, each with properties that allow the programmer to travel up and down the object tree as needed.
The benefit of the XMLParser.cc class is that it creates a simpler dBASE object that relies on indexed AssocArrays, so it may be easier to understand and use within a dBASE application. It does not rely on external code, which can be difficult to rely upon across different versions of Windows. The benefit of the Microsoft parser is that it is noticeably faster than the native dBL parser, though they both run in sub-second times for smaller XML files. And while the dBL Parser was built to handle most aspects of XML files and many kinds of invalid XML structures, it is certainly not as robust as the Microsoft parser.
XMLSample.xml has been provided with this project but any XML file can be used for testing purposes. This sample project includes a Save to File option that will demonstrate how to save these different XML models to another file, along with a demonstration about how the XML may be subtly changed during the process. The main editor field on this screen uses different methods to display the results of each button that is used, displaying the XML structures according to their respective hierarchies. Note that the logic uses a series of Do Loops to traverse the XML hierachy. It does not use recursive functions (which would be easier to write) because dBASE gets an error if a function is called recursively more than twenty times.
Purposes for XML in dBase Applications
As discussed in the beginning of this article, XML is quite useful for transferring data between two different software systems. Most recently, our company has used XML as an intermediate point between two separate database systems. Users for one of our clients enter part of their information into an inhouse software system. Rather than requiring users to duplicate the work and enter the same data into our software, we provided a way to import XML files. Now our customers inhouse software can export the information by creating XML files that our software in turn can import with ease.
The dBASE newsgroups have plenty of examples in which dBL programmers allow their dBASE application to communicate back and forth with a web service via XML. XML files are also useful as property files for applications that need to store information locally, similar to an ini file but with the advantages of XML.
As another example, our companys flagship software is written in dBL but we have various supporting applications written in Java. It is difficult to use and update Level 7 dBASE tables using Java so XML allows us to pass some information between the dBL and Java applications. This facilitates the compatiblity between our applications.
While there are many uses for XML in dBL applications, do not make the mistake of assuming that an XML file can replace a database even though they are similar in several respects. dBASE databases and other relational databases still provide numerous advantages that a plain XML file cannot match, such as indexing and table relationships. Technically, it is possible to use an XML file as a pseudo-database file but this is not recommended.
Conclusion
While the dBASE programming software
does not supply inherent methods for using XML, dBASE certainly has various
excellent solutions that can be used. XML is easy to create, easy
to read, easy to use with the right tools and it can provide easy compatibility
between software systems. XML may not be the greatest thing since
sliced bread but its certainly one more step in the evolution of great
software.
|
(it is a 9 Kb zipped file) |
 |
Jamie A. Grant has been a dBASE programmer with AV-Base Systems, Inc. since 1999. AV-Base Systems has been providing Aviation Maintenance Management Software to the global aviation industry for the past twenty years. Thanks to AV-Base Systems for their continued support of the dBASE community and their key contribution to this article. |