by A. A. Katz
There's a whole bunch of reasons why dBASE programmers might not want to upsize to any remote database server from any company, including InterBase:
There are fewer reasons why you should:
However, if we weigh the pros and cons above according to their impact on applications and users, one of them stands out, heads and shoulders above all the others: data integrity. Nothing - not user-interface, not performance, not even cost - is more important to the user than data integrity. Accurate, accessible data is the raison d'etre - the very reason for the existence of your database application. Without question, Client/Server solutions supply a level of data integrity impossible to achieve with local table engines (.db, .dbf) due to the very nature of their architecture.
Before we get too deeply into "How" to scale a Visual dBASE application to InterBase, perhaps we should consider "Why" we should do it and whether it's the most appropriate solution for any particular application. To make that decision, you'll have to understand the two architectures and weigh the features and limitations of both.
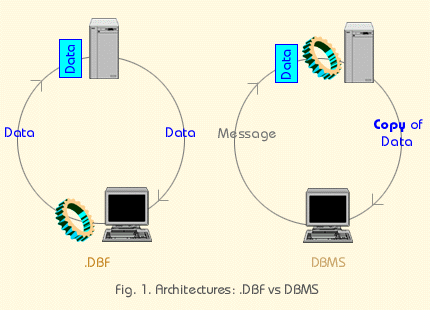
The primary difference between "local engines" and remote server engines is where the data manipulation, processing, storage and retrieval take place. Not the physical location of the table data, but rather, the location at which the processing occurs.
In a traditional dBASE application, the engine runs on the client - the workstation on which the application resides. Each user of the application has his or her own copy of the engine loaded in memory. In Client/Server applications, there's only a single engine running on a remote server, available to any number of workstations running applications.
A subtle distinction? Not at all. With Borland Database Engines saving, retrieving and indexing .dbf tables all over the network, the probability of one of them failing (or one user kicking out the plug on their PC, or one user "experimenting" with an interactive copy of dBASE) is magnified by the number of workstations connected to the shared tables on the server. There has never been a dBASE developer who has not encountered corrupted indexes or blob files that had to be "fixed" by restoring a backup. This kind of corruption is typical of local databases for a simple reason: each user is playing with an assortment of live data, live indexes and live blobs. The very idea of a couple of hundred users each having various 8K pieces of your mission-critical data floating around in the memory of their workstations at any given time should terrify you (I know it does me.).
Client/Server engines, on the other hand, provide true server capability. A server is a computer or software that supplies a service - in this case, managing live data. All of the live data. All on one server. All of it under the control of one single engine (not potentially hundreds, as we have with local tables). Of course, the server might go down, and therein lies the only significant potential for corrupted data. But servers are generally better machines, more fault tolerant, much better maintained, and no one is sitting at the server playing Solitaire (hopefully) or accessing X-rated Web sites that might freeze or crash their computer. Server operating systems are much more robust, their processes much better protected from failure in other processes, and they're optimized specifically to provide services to many users simultaneously.
The key to the Client/Server engine is copies of data, not data. Users
never get your live data in their hands. They may adjust, delete or add to their
copy of the data, but their changes are integrated back into the database by
the database server running on the file server, not by the application
running on the client.
The messaging language of Client/Server is SQL (also known as Structured Query Language). Requests (in SQL) are sent from the client application to the server, a message is returned or, more likely, a copy of a selected subset of database records (an answer set, return set, dataset or rowset) is sent back for the application to modify, display or report.
Tip: One of the nice benefits of having a separate and remote engine processing data is that they are usually multi-platform (unless, of course, they come from Microsoft), running at least on Windows NT and Unix. And, taking into consideration that they generally have no native application development tools, they embrace "open" standards and can be accessed by applications written in almost any language. Client/Server has standardized on SQL as the common language for remote database access. In a market-driven move over the last few years, almost all languages have also embraced the ANSI SQL standard - meaning that "open" systems (like InterBase) can share their data with an almost unlimited number of applications, written in a host of languages on a variety of platforms. Neat.
In part because of its Client/Server model, DBMS engines are built significantly differently from the traditional local .dbf engine. The .dbf table format has always been row-oriented, resulting in a very fast, but very limited, scheme for aggregating records. Decent performance has always been predicated on highly-designed, rigidly-enforced compound index structures and many, many indexes. Even with the Speedfilter technology of the Borland Database Engine, unstructured data retrieval, by comparison, is simply terrible. DBMS engines are intentionally optimized to perform unstructured queries against large numbers of table records (even across tables) with blinding speed. Which means that you gain the freedom, as developer, to assemble your client's diverse data in any format and any combination of selected rows without the huge performance penalty of dBASE filters - leading to infinitely more informative reports, unrestricted ad-hoc runtime queries - in general, the ability to assemble data into information however your client needs it.
The InterBase engine still uses pre-defined indexes, but once defined, you should never have to "set order" again - InterBase finds the best way to optimize your request, including building temporary indexes on-the-fly. And they're really, really fast. InterBase may be thought of as "the promise of SpeedFilter fulfilled". Among other reasons, InterBase's query performance is so much better because its indexes are binary. Binary indexes use bits to represent data as opposed to the bytes that represent data in dBASE index files. The result of using such a compact unit to represent ordered fields is that indexes are much smaller and significantly faster.
There's one particular area in which the "local table" engines have always failed miserably: quantitative or comparative queries. dBASE indexes are designed for "find first, skip through the rest" - queries based on alphabetically ordered index files. What they can't do is quickly assemble data that's "greater than this value and less than that value". Yet, this kind of quantitative aggregation goes to the core of business reporting. dBASE and Paradox tables have no mechanism for returning a high-performance response to: "Give me all the customers who spent more than $100 but less than $ 1000 over the last six months". They almost grind to a halt when you add: "And operate in New York, Pennsylvania and New Jersey and have bought Widget # 1003 at least once in the last five years". For applications using dBASE tables, it's time for a coffee break - or perhaps even lunch - while you wait for results. InterBase, as a DBMS is specifically designed from the ground up to support complex, quantitative queries like these.
dBASE tables are superb for lists and grids. DBMS engines are superb at delivering business information in a meaningful form.
Each architecture provides its advantages and disadvantages in utilization of network bandwidth. dBASE tables send only small chunks of data (table buffers) back and forth across the wire. They're reasonably efficient. Today's DBMS servers (including InterBase) do the same - buffering their answer sets in pages. On the other hand, they can be much slower getting to the first row in a fresh query involving lots of records. The tradeoff is between constant access to refresh tiny buffers (.dbf tables) and the time it takes to "grab" a rowset from a query. But there are some significant bandwidth improvements to be had from DBMS engines:
You don't have to bring all the fields of your table over the wire - just the ones you need for the current query.
Aggregate totals (like Sum, Count, Average) return only their result values over the wire. Using dBASE tables, the entire table has to travel over the network in order for the local engine to extract the information needed to calculate totals. Aggregates are much faster in DBMS than dBASE tables and put a lot less pressure on the network.
You can configure an InterBase database, defining "page size" and other paramaters to optimize the engine to the demands of specific applications. If you're doing lots of single-transactions, you tune the engine one way. If you're doing mostly "data mining", where you retrieve large chunks of historic data, you might want to tune it another way. No such "tuning" exists in .dbf or .db engines.
There's a downside, as well, to Client/Server engines: the load on the server. When Client/Server first came out for the PC LAN, its biggest selling point was that it "cleared up the network bottleneck", moving much less data across the wire, much less often than traditional databases. This was offset , unfortunately, by the fact that the Client/Server architecture doesn't leverage the distributed processing power of the workstations connected to the server. All the work that used to be spread out across the network is now concentrated on a single machine - the database server. This load factor is one of the driving forces behind the recent phenomenal improvements in server architectures (symmetric multi-processors, particularly) and PC operating systems (Windows NT).
So, does this sound like a return to the old "mainframe" days, with a huge central processor spewing out data in response to commands from stupid terminals? It shouldn't, because it's not - the terminals (workstations) are anything but dumb. It is however, a major redistribution of work.
One of the ways in which Client/Server has evolved in recent years has a lot to do with the distribution of work. The huge security and integrity advantages of a centralized data engine can be seriously compromised by local applications running all over a network. Each applicationr may have its own validation, transaction, business and update rules. To address this disparity, today's Client/Server database architecture is moving toward a multi-tier solution. Assuming the data server as the top tier and the client application as the bottom tier, there's a world of possibilities for distributing some of the tasks in any number of tiers inbetween the two. The most popular is three-tier Client/Server. In a three-tier architecture, the applications still run on the workstation (if not, it's not really Client/Server-- where's the client?) but they are "served" from another server: the application server.
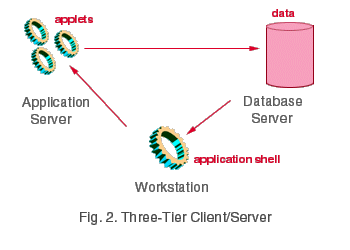
The software on the application server is not neccessarily an actual program. It might be an object in which you encapsulate the business rules of your organization. For example, you may post an ActiveX object on the application server that validates posting transactions before they're approved for update on the database server. Why bother? Remember that Client/Server specifically supports the use of multiple, multi-platform applications running against the DBMS engine. Imagine the chaos if ten different programmers write ten different programs all of which post to the General Ledger - with ten different sets of rules. Posting a mission-critical module on the Application Server through which all client applications must post ensures data integrity in your General Ledger tables, regardless of who wrote the end-user app or what language it was written in.
In this object-based three-tier topology, the client application can be as minimal as a navigation shell that "grabs" pre-defined objects off the application server to do its work. Or it might be a robust Windows application that address the application server only when it posts.
Note:
Lest
you think that this is really abstruse stuff and unconnected to the real world,
let me assure you that this stuff is a problem every day. This year I seem to
have a rash of new clients all of whom need diverse applications (some third-party,
some written by me) that have to access and update a single central database.
For example, one grocery chain for whom I'm consulting, has a warehouse package
running on an AS/400, a front-end management system that brings back cash register
data from the stores running on an Informix box, multiple legacy DOS applications
(asset management), a purchasing package, and.... well you get the point. My
job is to make all this stuff work together and automatically update a central
database to eliminate all the double- and triple-data-entry they're suffering
through now. This one HAS to have centralized business rules or the whole thing
will fall apart. Our solution is an InterBase central data repository
with rules-based import and export apps on an Application Server. The only "portal"
to the data is through the objects on the App Server.
Multi-Tier Client/Server has worked reasonably well - but not well enough. There is still too much risk in the middle layer falling apart under heavy loads and out-of-control users. If the app server goes down, both the other tiers fall apart. A far more granular approach (smaller pieces) is just coming into vogue: distributed applications. Distributed applications use very small pieces of code wrapped in objects which can be Active X (Microsoft), JavaBeans (Sun) or CORBA (the rest of the world). They can be on any server or number of servers on the network with a single "control panel" monitoring performance, load balancing (passing the next request to the least-busy object) and failover (if one copy fails, there may be seven more available on the network). Distributed computing is a huge insurance policy on applications. The business rules on which mission-critical programs rely so heavily are still centrally maintained and upgraded, but not neccessarily in one physical location. The middleware (essentially an Object Server) knows where all the pieces and copies are - so that access is transparent to the user and administrator.
If you followed the torturous path from local tables to Distributed Database Applications in the sections above, you may have noticed that the driving force behind these new architectures is to get important applications as far away from the user as possible. The reason for this should be obvious to any experienced programmer - make that any programmer who has ever had ANY users.
Another way of doing that using InterBase is through the use of Stored Procedures. Stored procedures are small applications that live on the database server - as part of the database itself (hence the name "stored"). A stored procedure can be called by any application that supports SQL. So, assume the case we discussed earlier of a business-critical general-ledger application. You might store the "rules" code right on the database server as a stored procedure and force every application to make SQL calls to process the posting.
Each SQL engine that supports Stored Procedures has its own language in which to write them. Some engines use a C-like language, some are now adopting Java. InterBase has an extended SQL language that sometimes looks suspiciously like dBASE code, sometimes like C, sometimes like SQL:
CREATE PROCEDURE GET_EMP_PRJ (emp_no SMALLINT)
RETURNS (emp_proj SMALLINT) AS
BEGIN
FOR SELECT PROJ_ID
FROM EMPLOYEE_PROJECT
WHERE EMP_NO = :emp_no
INTO :emp_proj
DO
SUSPEND
END !!
Now, this is not quite dBASE code - it's a combination of SQL statements and control statements (like Begin...end) and hard-typed variables (note the SMALLINT in the first line and in the RETURN value). On the other hand, this is very, very simple and should pose no obstacle to the experienced dBASE programmer.
InterBase also provides DSQL, a dynamic run-time SQL language that will be dear to the heart of the macro-spoiled dBASE programmer. The difference between the native language and DSQL is that the native language is compiled - it has to know all its information at compile time, while DSQL works more like a macro or codeblock, evaluating its expressions at runtime.
InterBase has an interesting event-handling strategy. Stored Procedures can notify the server of their "interest in an event". An event might be an Insert, Update or Delete, for example. When the event occurs, the Stored Procedure "registered" for that event gets a message and fires its event handler. Think of it as remote-control procedures on a remote server.
The Visual dBASE developer is somewhat limited by the lack of Access and Assign methods - functions used to create from-scratch events. In Visual dBASE, event handlers get attached to pre-defined events. You can create your own, but only by calling existing ones.
The InterBase procedure language supports triggers - user-defined events that call other triggers or stored procedures. Using triggers, you can define an event such as "a change in the checkbook amount field" and automatically call a stored procedure or another trigger to update totals, for example, or post events (such as a global warning that this table has been changed) to applications listening for them.
InterBase is not just "another" data engine - an equal alternative to dBASE tables. It's a true server, with all that word implies. It's expected to run around-the-clock and sports a host of features to manage the database and ensure that the server runs flawlessly and, in the event of catastrophe, to recover with the absolute mimimum loss of data. Some of the features of InterBase that distinguish it from dBASE are:
Multi-Generational InterBase keeps multiple copies of rows and transactions - multiple generations that allow a) transactions to be rolled back without the spurious empty records that dBASE accumulates and b) the restoration of data in case of failure
Data Dictionary (meta data) The dBASE table header is a relatively inscrutable binary section of the .dbf file that takes a fair amount of experience to interpret - and even more to change. The InterBase engine uses metadata - system tables that comprise a real, dynamic data dictionary, including field definitions, stored procedures (which may include business rules) and referential integrity. The meta-data is all stored in accessible InterBase tables. In case of disaster, being able to get into the system tables can be invaluable.
Generators Visual dBASE 7 is the first version of dBASE to feature "autoincrement" fields. InterBase has a totally portable autoincrement technology called "generators". Generators turn any field into an autoincrement field and guarantee unique values in each row.
Statistics In the dBASE world, logging and statistics on table access and usage is strictly up to the programmer. InterBase keeps a variety of statistics on its use and data which can be used to tune applications for better performance.
Backup InterBase has built-in backup and restore capabilities.
Domains A side benefit of the "meta-data" system tables is that table fields are defined externally to the table itself, which gives InterBase the opportunity to offer inheritable field definitions. You might create Firstname, Lastname and CompanyName domains which are available to all tables in the database. Once a domain's properties are defined (including "must enter value" - not null) you may create unlimited fields within your tables based on the pre-defined domains.
Joins - Updateable Joins SQL Select statements can return data spanning a number of tables. Under certain circumstances, these Joins are updateable in Visual dBASE 7 - meaning that changes to fields get sent back to the appropriate tables when the rowset is updated.
True Transaction Management InterBase supports true transactions - no data is saved to the table until the transaction is complete and validiated. Therefore, there are no empty records hanging around where data was deleted. Triggers and events occur only when the transaction has been successfully committed.
Security Password access to the database is not optional in InterBase - it's required. Security is at the database level and InterBase provides simple graphic tools to manage users, access and passwords.
Split InterBase databases can be split among multiple folders, or even drives as long as they're on the same network node.
Sweep Believe it or not, InterBase does its own housekeeping on tables, including garbage collection. This feature does not require exclusive use of the table, runs automatically and is configurable as to the interval between sweeps (based on the number of transactions).
Reindex without Exclusive Unlike dBASE, InterBase leverages its multi-generational architecture to allow a number of global operations, such as reindexing, while other users are currently online and the table being indexed is open.
Shadow InterBase Server allows you to keep multiple, synchronous copies of your tables or part of your tables to prevent against corruption and data loss.
Array Data InterBase supports arrays as a column type in tables. However, since Visual dBASE 7 has no capability of referencing these arrays (all it sees is a handle), they're only accessible from InterBase stored procedures.
Repair InterBase supplies a built-in validation and repair facility to fix errors that may have been caused by server system failures, bad disk writes and similar problems. It uses a checksum and other parameters to validate both pages and records.
Small footprint. Of all the major DBMS engines, InterBase requires the least disk space.
Small price None of the popular DBMS servers follows the "no-royalty" policy of Visual dBASE deployment. When you ship an executable dBASE application, it's your code that's running on the client's machine. When you deploy a DBMS server, it's theirs. Database servers can be very expensive, depending on the size of the organization using them and the number of workstations attached at any given time. MS SQL server is one of the least expensive at approximately $1500 per server, Oracle can cost in the tens of thousands on the server-side alone. Per-seat prices can escalate your client's cost dramatically. InterBase costs only a couple of hundred dollars on the server and a little over a hundred per seat, making it the most cost-effective, full-featured database server engine available today.
BDE Support Visual dBASE 7 and InterBase are a most obvious match. Inprise's BDE includes native support for InterBase through its SQL links drivers (Client/Server version) and local support for InterBase in the Professional Editional. No ODBC drivers required to establish a connection to the database.
Speed InterBase is one of the fastest DBMS engines on the market for networks of fewer than 200 or so workstations.
Low Maintenance The automatic Sweep, gFix, plus other cleanup operations run when you backup and restore result in a near-0-maintenance database.
Self-sizing Believe it or not, most of the competing database engines require that you pre-size your tables, allocating disk space in advance. If you exceed your original estimates, the only way to expand is to back up the database, create a new larger one and then restore the data from the original. Just like dBASE, InterBase sizes tables dynamically, growing files as needed.
Row Locking DBMS engines appear to be pretty primitive, in some ways, when compared with dBASE. That's because they were designed for handling industrial strength queries with speed, accuracy and integrity, not for ease of programming or user-interface. MS SQL Server 6.5 (among others) offers only page locking. All rows on a page are locked if any row on the page is locked. InterBase supports both optimistic and pessimistic row-level locking.
User-interface "Picture" formatting saved in the data dictionary. How many of us are using this feature? Heavens, as though there weren't enough places in Visual dBASE to format data - from user-interfacecontrols to beforeGetValue. To be honest, I haven't even once availed myself of this engine-level data-dictionary capability.
Several of the fast filtering and relational methods of the new Data Classes such as MasterRowset/MasterFields and rowset.setRange(). These are a big deal, as they represent the fastest rowset operations possible in the new Visual dBASE 7 OODML. But though they're stellar performers, they only work under one very specific circumstance - that your SQL statement uses
'select * from "mytable"'
with no qualifications whatever. Add "Where Firstname='ALAN'" and MasterRowset and setRange() no longer work. Why? Because they get their speed from being indexed operations. Rowsets don't have indexes, tables have indexes! So how can they possibly work - aren't they rowset methods? Not really. Though attached to the Rowset class, they only work on fully-selected dBASE tables. It just so happens that a dBASE table queried with "Select *" and having no qualifiers, executes a "USE", just like the old dBASE DML command. Which leaves the table open and the index available. In this one case only, the table and the rowset are the same.
Tip: To be honest, this breaks every rule of SQL and OODML, but was included to give us dBASE programmers equivalent functionality in OODML to what we had in DML, but only when working with dBASE tables.
And while we're at it, let's be realistic - how often do you need to show parent-child related grids on a single form without a page change or modal dialog between? Not all that often. And when you do, you may be pleasantly surprised to see how fast MasterSource can be using InterBase tables.
MasterSource is a specialized Query class property designed to automate parameterized queries. A parameterized query is one that requeries whenever it sees a change in a variable included in its select statement.
Assume a parent Customer1 rowset with a "CustNo" field.
Assume a child rowset (Invoices1) with a "CustomerNumber" field.
Assume the two tables are linked together with Custno/CustomerNumber.
Using MasterSource, you can define a SQL string in the child query that triggers an automatic requery whenever the parent "CustNo" value changes - whether due to programmatic changes, user-input or rowset navigation.
The properties in the child look something like this:
With (this.Invoices1)
sql = 'Select * from Invoices '+;
'Where CustomerNumber == :Custno'masterSource = this.parent.Customer1.rowset
endWith
Each time the row pointer moves in "Customer1" , the "Invoices1" query substitutes the value of Customer1->CustNo into the parameter :Custno and gets a new set of rows to match the new value. All that's required is that the paramter (the one with the colon) matches the linking field name of the parent. The rest is automatic.
Running MasterSource against dBASE tables is, quite frankly, a disaster. It's staggeringly slow. Each "requery" is essentially a new "SET FILTER" on the child table, and we all know how slow filters are (though they've improved somewhat in recent years).
InterBase is optimized for excellent performance in exactly this kind of situation. What's unusable in dBASE tables become de riguer in InterBase tables. Admittedly, nothing is as fast as an indexed filter or relation, but I think you'll find InterBase parameterized queries to run a very close second.
The Visual dBASE 7 data-access objects surface a huge amount of control over the disposition of your data when using InterBase tables. You can decide whether a rowset is live (updateable) or read-only. You can cache your updates (keep your updates in memory) and write them as a batch. When you cache updates, you turn off the automatic table updates that normally occur on row-pointer movements and set your own criteria for writing back to the table. The updateWhere property is used with the SQL UPDATE command to batch process changes back to the table. You can select the changes that trigger updating:
0 All fields
1 Key fields
2 Key fields and changed fields:
You can make queries Unidirectional, for much improved performance when the row cursor only needs to move from top to bottom of the rowset - as it does, for instance, in reports. Excellent for optimizing performance on server-side Web applications, as well.
InterBase supports true transaction processing. The dBASE implementation is more like "transaction emulation". If you rollback() a transaction in dBASE, it empties and deletes all records written to tables since beginTrans(). InterBase, on the other hand, supports true transactions - nothing is written to the table until the transaction is checked and commited. You may also define the isolation level for transactions:
0 Read
uncommitted
1 Read committed
2 Repeatable read
Tip: The transaction has more serious implications in InterBase than in dBASE since events are transaction-related, and won't fire until the transaction is completed.
InterBase uses a simple Installshield-style Windows setup. But there are some issues that you should be aware of before installing.
First is that there is more than one flavor of the InterBase engine. Local InterBase is the InterBase server running on the same node as the application runs. Local InterBase is shipped with the Client/Server version of Visual dBASE 7 and is intended for use as a "test" environment for development. It provides two licenses so that you may test multi-user issues prior to deployment.
InterBase server, on the other hand, is the remote server, intended to run on a network node other than the one on which the application is running.
Licenses Installing InterBase as Local InterBase or InterBase Server depends on the license information you provide during installation. If you're setting up a remote server, be sure to provide the license "Server Capability (S)", which allows remote connections.
Tip: The InterBase "Client Capability (R)" license is not for end-users, it's to allow the server on which InterBase resides to act as a client to another InterBase server. This license is only used for configurations in which there's more than one InterBase server operating on more than one server node.
Running InterBase Server InterBase Server can be set up to start manually or load automatically as a Windows NT service. For those of you who haven't worked extensively with NT, an NT Service is an application that can be started and shut down, monitored and logged by Windows NT. Win NT services have much better fault protection than a normal application, so you'll definitely want to set up InterBase server as a Win NT service. In addtion, InterBase provides Guardian mode. When in Guardian mode, InterBase reloads itself automatically if it should be brought down by another application, temporary power outage or the like. It is recommended that InterBase be run at all times in Guardian mode.
Tip: InterBase Windows Client. The InterBase installation includes an option for client-side installation. Visual dBASE programmers may ignore this - the BDE provides all the drivers you need in its Client/Server version. If you don't have the Client/Server version of Visual dBASE 7, you may want to go ahead and install, but you'll need to set up an ODBC connection in Control Panel using the included InterBase ODBC driver.
The optimal approach to upsizing Visual dBASE applications depends upon your starting place and your goals. If you're starting from scratch, and your application will only run against InterBase tables, the process is realitively straightforward. If you're upsizing from an existing Visual dBASE app that's going to run from this point on only against InterBase tables, you've got some recoding to do to optimize your program, but it's certainly not a major project. If you're writing an application that needs to be run interchangeably against dBASE tables and InterBase tables, you've got some serious strategy issues to resolve.
Let's start with some rules that apply to all scalable Visual dBASE 7 applications:
Always use a BDE alias, even if you don't know that an application is likely to be scaled up at a future date. Once the decision is made to upsize and existing application, it's really too late to benefit from the commonality of BDE aliases. A BDE alias is an engine-level pointer to your data. It can be used against dBASE tables or InterBase tables at will. It defines the language driver, configuration criteria and the database driver to be used when accessing tables through this alias. DBase aliases point to folders where tables are stored. InterBase aliases point to the actual database file (.gdb) on the server.
Always Use OODML. The object-oriented data manipulation language in Visual dBASE 7 was designed specifically to support scalable database access. The old record-oriented procedural DML was not.
Always Use a DataBase Object. The Database class in Visual dBASE 7 can be used with any BDE alias, whether the alias represents dBASE tables or a remote client/server engine.
Always Share The Database class "share" property allows an application to re-use the current database login. If you don't "share", another user will be logged on to the InterBase server every time you instantiate a new database object, chewing up your licenses each time a form opens.
Subclass Use OOP to minimize the work required to upscale a Visual dBASE application. Create a custom DataModule class that contains a pre-designed database object pointing to your database. If you do, you'll only have to change aliases and database login properties in a single location in a single custom class.
The next are rules to apply when upscaling an existing Visual dBASE application
to InterBase:
Index-Bound Methods Replace dBASE-specific OODML Methods. Methods that require a "USE MYFILE" equivalent in the Visual dBASE 7 data objects, such as MasterRowset/MasterFields and SetRange() must be removed before running against any DBMS server. They will fail and produce unwanted and inaccurate results. These methods (as mentioned earlier) depend on the in-place dBASE indexes, which are not surfaced if you qualify a Query's SQL statement or use a Query against a non-dBASE table.
Remove Set Filter except against small rowsets. You'll do better with an initial SQL Select (see following).
SQL Statements Optimize your Queries' SQL statements. SQL is pretty robust, offering "Where", "Like", "In" and other operators that give a wide range of selection criteria. When writing apps against remote servers, your best performance always comes from grabbing the smallest, most accurate rowset on the first try.
Cached Updates Consider using Cached Updates to improve performance, but not for small transactions on critical data, which you'll want to write to the database as quickly as possible.
Generators Replace your autoincrement fields with InterBase Generators.
Stored Procedures. Check your code to see if there are any validation or calculation operations that would execute better, faster, and with more security on the InterBase server as a stored procedure.
There are two basic ways to design Visual dBASE 7 applications for scaling: Codeless and Multi-Version. Codeless scalability means writing a single application that will run equally well under local dBASE tables and the InterBase DBMS. You can achieve excellent results, but you have to be very careful when designing Codeless scaling applications not to employ Visual dBASE 7 features not supported either by local tables or InterBase. Alternatively, you may wish to optimize your application - which require two separate codebases, with each version is optimized for the particular engine against which it will run.
The choice of approach can be difficult since you'll most likely be trading off performance for coding and code maintenance convenience. Here's some thoughts that might help when weighing the alternatives:
When we talk about optimization, we're usally talking about user-interface issues, not true database performance. Let's face it, the two basic database operations are: entering data and retrieving data. Both the dBASE and InterBase engines will execute these operations just fine in most cases. There are no performance issues when appending a new row in InterBase or dBASE and the same program code supports both engines.
Retrieving data is a bit stickier, but not at its most basic level. If we want to bring up a single row to edit, either engine will do that without problem. Reporting is another kind of retrieval that's supported well by both engines. Where we get into trouble is forms that feature multiple grids simultaneously moving through parent and multiple child tables. dBASE does this much better than InterBase in that it can link together separate indexed tables. On the other hand, dBASE does this poorly when the link between tables is more than the simplest key field. For instance, I'd hate to have a Customer parent grid linked to a child table grid whose link is: child.Custno=parent.custno and date > date()-90. Performance would be horrific.
So, if you're building an application to scale (or one that may scale), the easiest way to ensure success is to avoid complex user-interface designs that might cause conflicts between the database formats. In our example above, you might, instead use a single grid (no problem for either engines's rowset) and offer the child in a double-click that spawns a modal dialog. That way, you don't run a SQL Select for every single Customer in the parent grid. Less information on screen at the same time? Sure, but it's all just a double-click away. What you've traded off, in fact, is a lot of garbage data. Surely the user didn't really want to see all the invoices for all the customers, just the invoices for the particular customers in which they're interested..
Tip: The more Visual dBASE programs I see (and write), the more convinced I become that sometimes we write fancy forms because we can... not because they necessarily product more, better, usable information. I suspect that the record-based architecture of dBASE has somehow led us to believe that we should show every field of every record that might ever, under any circumstances be required or desired by any user. I'm not sure we're doing our users a favor when we do that. We shouldn't be trying to deliver raw data - we should be trying to give meaning to it and deliver information to the user. You've got to admire InterBase (and SQL, in general) for being information-centric instead of data-centric.
The following is a very sparse guide to some of the criteria that you should take into consideration when you decide how "scalable" to write your next Visual dBASE 7 application:
You don't need InterBase if:
You definitely need InterBase if:
You'll note that most of what you read here is the theory behind client/server computing and the features of the InterBase server despite the fact that the topic was supposed to be "upsizing". There's a good reason for this long digression - Visual dBASE 7 is already built to scale with very little recoding required on your part. What is required is a real understanding of how your applications work with a totally de-bundled remote data engine like InterBase.
dBASE programmers are a bit late to the party. Most of us are not yet using remote engines to power our Visual dBASE applications. Not that we didn't need to or want to. It's just that the dBASE data model has served us so well, and grown so over the years that third-party engines just haven't seemed all that important - even though the rest of the world was moving inexorably into client/server.
The biggest sacrifice when we move to a new data engine is the years of expertise we've accumulated in optimizing our tables, indexes and the user-interface controls that use them. All I can suggest is that you experiment, experiment, experiment. InterBase is optimized radically differently from dBASE, but it's optimized in some ways better - toward delivering information, not records. It's important for the dBASE programmer to add SQL databases to his or her repertoire. It's important for the dBASE programmer to join the rest of the database world, or most assuredly get left behind as the new client/server, Web and distributed object tecnologies take over the business world. There is no easier, less expensive or more effective way to get your client/server feet wet than the wonderful InterBase database server engine.
eof(6-14-1998)