Le but du présent article est de traiter de la conception des bases de données relationnelles. Le sujet n'est pas difficile. L'approche sera pratique. Il n'y a pas de pré-requis.
Les lecteurs qui ont préalablement étudié le sujet seront peut-être surpris de voir que les notions académiques de «normalisation» et de «formulaire normal» sont presque complètement absentes du présent texte. Ceci est voulu. mon expérience de l'enseignement de la conception des bases de données m'a amené à penser qu'une approche pratique est plus efficace.
Introduction
Une base logique de données est un recueil de données. Ainsi, une compagnie pourrait maintenir une base de données du personnel dans laquelle seraient enregistrées les données relatives à ses employés. Cette même compagnie pourrait également maintenir à jour une base de données d'inventaire afin de pouvoir déterminer à tout instant le nombre et le type de marchandise qu'elle possède.
Dans une base de données relationnelle, les données sont conservées dans des tables accessibles par ordinateur. Une base logique de données peut être composée de plusieurs tables liées entre elles. Par exemple, la base de données d'une bibliothèque peut être composée d'une table des livres à emprunter et d'une table d'emprunteurs. Ces deux tables seraient liées de manière à déterminer les emprunts effectués. La conception des bases de données est l'art de déterminer quels types de données devraient être enregistrées et dans quelles tables ces données devraient l'être.
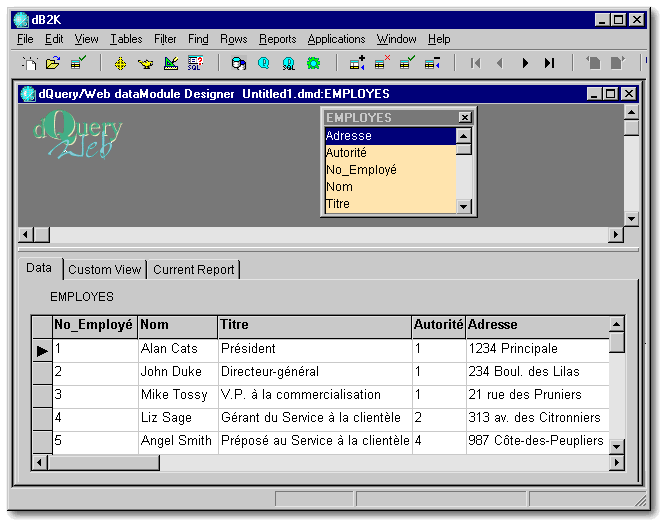
Pour terminer cette introduction, voyons un peu de terminologie. Dans un système de base de données relationnelle, comme dB2K, les données sont conservées dans des tables. Ces tables peuvent être soit des tables conventionnelles de type dBASE (.dbf) ou Paradox (.db), ou à l'opposé, des tables conçues pour des bases de données de type SQL gérées pas des systèmes comme Oracle ou InterBase. Toutes les tables sont constituées de rangées (ou enregistrements) et de colonnes (ou champs).[1] Voici ci-dessous une table typique telle qu'affichée par le module dQuery/Web de dB2K.
On notera que toutes les rangées de cette table ont la même structure ; elles ont toutes le même nombre de colonnes et chacune de celles-ci renferme le même type de données (note : certaines vieilles bases de données non-relationnelles n'avaient pas cette caractéristique).
Une base de données
est une collection de tables utilisées pour enregistrer les données
nécessaires à l'accomplissement d'une tâche ou à
l'exécution d'une application informatique. Ainsi une base de données
de ressources humaines pourrait être constituée d'un certain
nombre de tables nécessaires au fonctionnement d'un service de ressources
humaines : une table d'employés, de leurs aptitudes et de leur famille
(enfants et conjoints). La base de données d'un atelier de réparation
comprendrait probablement des tables de pièces automobiles, des
ventes, des clients et des achats.
| Mise en garde ! |
| La notion de base
de données «relationnelle» est un peu galvaudée en informatique.
Ce ne sont pas toutes les bases de données qui peuvent être
qualifiées de relationnelles et les bases de données qui
ne le sont pas peuvent utiliser autre chose que des tables pour enregistrer
leurs données. Certains systèmes pseudo relationnels
ne le sont pas (on me permettra d'éviter de donner des noms).
Certaines personnes utilisent l'expression «base de données» comme synonyme de table. D'autres l'utilisent pour décrire les tables d'un même répertoire sans que celles-ci ne soit reliées entre elles. Lorsque quelqu'un vous parle de sa «base de données», sachez qu'il ne s'agit peut-être pas de ce que vous pensez. Dans le présent document, lorsqu'on parlera d'une base de données, il s'agira toujours d'une base de données relationnelle, soit une collection d'une ou de plusieurs tables reliées entre elles. L'adjectif «relationnelle» ne vient pas de «relation» (rapport entre des choses) mais d'un ancien concept mathématique désignant une table. Voilà pourquoi une table seule peut être relationnelle. |
Normalisation
La normalisation est le processus qui consiste à décider dans quelle table devrait être enregistré tel type de donnée. Ce processus est inhérent à la conception d'une base de données. Il s'agit même d'un sujet de recherche universitaire. Par exemple, des chercheurs ont défini une série de niveaux de normalisation. Dans une vie antérieure (en fait dans les années '80), j'enseignais la conception des bases de données. Malheureusement, l'approche académique n'est pas très utile pour enseigner aux débutants comment créer leurs bases de données. J'ai donc choisi d'offrir une série de règles et d'exemples de nature à démontrer comment concevoir une base de données normalisée. On recherchera des tables bien normalisées car celles-ci sont plus faciles à mettre-à-jour, les requêtes s'y appliquent plus facilement et offrent le moins de risque d'inconsistance. Ces règles sont :
La règle des noms
La plupart des les tables renferment des noms : des personnes, des lieux ou des choses. Chaque rangée d'une table doit permettre de distinguer une des ces personnes, un lieu précis ou une chose en particulier.
La règle de la Clé primaire
Toutes les tables ont une clé primaire. Celle-ci est formée d'une ou de plusieurs colonnes qui permettent de distinguer une rangée des autres. Pour une table de personnes, ce pourrait être les colonnes du nom de famille et du prénom. Théoriquement, une colonne de numéros d'assurance sociale permettrait de distinguer les homonymes. Dans les faits, il en est autrement.[2]
Certaines tables ont une clé primaire dite «naturelle». Dans de telles tables, on trouve naturellement tout ce qu'il faut pour distinguer un item de l'ensemble. Dans une table de pièces automobiles, par exemple, la colonne des numéros de pièce servira de clé primaire naturelle.
À l'opposé, certaines tables auront besoin d'une clé primaire dite «artificielle». Puisque chaque table au sein d'une base de données doit absolument avoir une clé primaire, on lui créera donc une clé primaire artificielle si elle ne peut être trouvée naturellement. Une entreprise créera des numéros d'employés. Un fabriquant, des numéros de série. Une Régie automobile, des numéros de plaque d'immatriculation. Ce sont tous des exemples de clés primaires artificielles. On pourrait utiliser un champ AutoIncrement à cette fin. Contrairement à un nom marital, qui peut changer avec le temps, une clé primaire doit être unique et inaltérable. Pour des personnes, il est préférable de créer une clé primaire artificielle.[3]
La règle des Attributs
Considérez toutes les colonnes autres que la clé primaire, comme des caractéristiques se rapportant au sujet défini par la clé primaire. Elles contiennent des items descriptifs, des faits ou des attributs se rapportant au sujet. Une colonne doit contenir dans chaque rangée, le même type d'information (statut marital, taille, couleur d'yeux, sexe, etc.). Si un attribut ne s'applique pas à un sujet (ex. : l'adresse d'un itinérant), la case correspondante peut rester vide.
Pour voir si une table respecte les règles ci-dessus, il suffit de lui appliquer une règle, celle de la Définition linéaire.
Le test de la Définition linéaire
Essayez de construire une phrase qui décrit la nature des rangées de votre table. Cette phrase doit être simple. Par exemple : «Chaque rangée correspond à un employé de notre entreprise». Une définition complexe sera suspecte. Par exemple, «Si la valeur de la première colonne est de 1, on a affaire à un employé : si c'est 2, il s'agit d'un enfant d'employé».
En fait, vous devriez re-dessiner votre table si vous ne pouvez appliquer ce principe ou si vous ne pouvez l'appliquer à chaque rangée de votre table. Une définition comme ci-après est à éviter : «Si le champ Segment est vrai, le champ Longueur renferme la longueur de ce segment. Par contre, si le champ Segment est faux, le champ Longueur renferme la taille totale du câble.»[6]
En somme, votre description doit être linéaire, sans «si», sans «peut-être» et sans «mais par contre».
Nous avons deux autres règles à voir. Mais pour l'instant, voici quelques cas où peuvent s'appliquer les règles dont nous avons déjà parlé.
D'abord voici un exemple à éviter.

Placer le nom des enfants d'employés dans la même table que leurs parents est une erreur. Et ce, pour trois raisons :
Le processus qui consistera à scinder la table précédente en deux tables suivantes, mieux structurées, est ce qu'on appelle la normalisation.
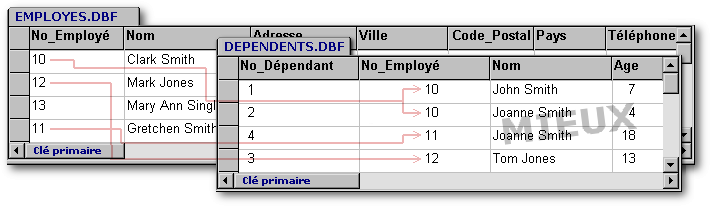
En scindant notre table en deux, nous instaurons une relation (dans ce cas-ci parentale) entre ces tables. Cette relation est appelée lien d'un à multiple (1:M) lorsqu'un employé peut avoir de zéro à plusieurs enfants mais que l'inverse n'est pas vrai, c'est-à-dire lorsque chaque enfant ne peut faire partie de la progéniture que d'un seul employé. Il arrive souvent que cette deuxième condition ne puisse être remplie, par exemple lorsqu'un enfant a pour père et pour mère, deux employés de l'entreprise : dans ce cas, on créera entre ces tables un lien multiple à multiple (M:M).[4]
Les règles précédemment définies sont suffisantes pour nous permettre de concevoir des tables comme des entités distinctes. Lorsqu'il s'agit de tisser des liens entre des tables, nous avons besoin de trois nouvelles règles de bienséance.
La règle des Relations
Soit que des tables qualifient les attributs relatifs à des éléments ou définissent la relation entre les éléments de tables différentes : Qui possède cette voiture ? Qui travaille pour ce service ? Quel produit a été expédié à ce client ?
La règle de la Clé primaire des relations
Lorsqu'une table défini des relations, celle-ci possède toujours une clé primaire naturelle. C'est sur cette clé primaire que se tisse le lien entre deux tables. Dans une table de relations, un champ AutoIncrement ne doit jamais servir à lier cette table de relations à une autre table.
La règle des Attributs (modifiée)
Considérez toutes les colonnes autres que la clé primaire, comme des caractéristiques se rapportant au sujet défini par la clé primaire ou à la relation qu'il entretient avec un élément d'une autre table. Une colonne doit contenir dans chaque rangée, le même type d'information. Si un attribut ne s'applique pas à un sujet la case correspondante peut demeurer vide.
Voyons ci-dessous une table de relations.
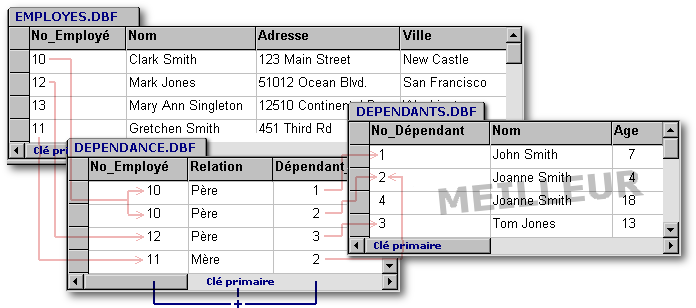
Clark Smith est père de deux enfants (John et Joanne). Son épouse, Gretchen Smith, est la mère de Joanne mais pas de John. Gretchen, est-elle son épouse actuelle ou son ex-conjointe ? L'enfant John est-il né avant ou après sa demi-soeur Johanne ? Voilà des questions auxquelles notre base de données n'offre pas de réponse. Quant à lui, l'employé Mark Jones possède un enfant (Tom) : cet employé, est-il marié, conjoint de fait, divorcé ou veuf ? Là encore nous ne le savons pas : tout ce que nous savons, c'est que le nom de la mère de son enfant n'apparaît pas parmi la liste des employés. Pour terminer, Mary-Ann Singleton n'a pas d'enfant.
La table ci-dessus illustre un lien de multiple à multiple (M:M) parce qu'un employé peut avoir de zéro à plusieurs enfants et qu'en contrepartie, un enfant peut avoir de zéro à plusieurs parents (note : les enfants qui n'auraient aucun parent seraient ceux qu'on aurait oublié d'enlever de la base de données après le congédiement ou le décès de leurs parents). Si vous voulez que chaque enfant ait au moins un parent et un maximum de deux parents (note : de nos jours, il en faut parfois plus lorsqu'il ne s'agit pas des parent biologiques), votre code dBL doit contenir des règles de validation puisque la simple normalisation ne suffit pas à créer de telles limites.
Croyez-le ou non, ces règles simples suffisent à normaliser correctement vos bases de données. Toutefois, voyons quelques exemples supplémentaires pour nous assurer que tout a été bien compris.
Exemple 1 : L'atelier de réparation
Supposons qu'il vous faille établir une base de données afin de consigner et de suivre les réparations effectuées dans un garage. Les éléments à consigner sont les clients, les réparations et le personnel. On créera donc les trois tables suivantes :



Quelles sont les relations à établir ? On devrait être capable de déterminer quel mécanicien a effectué une réparation. Puisqu'un mécanicien effectue généralement plus d'une réparation dans sa carrière (à moins qu'elle n'ait été désastreuse), on devrait prévoir un lien de 1:M à moins que ce ne soit un lien de M:M puisque plusieurs employés pourraient être affectés à l'ensemble des tâches relatives à une réparation (changement d'huile, nouvel alternateur, débosselage, peinture, etc). Il faudra donc prévoir cette possibilité. On pourra toujours empêcher de recourir à cette possibilité ultérieurement mais il sera difficile de s'en prévaloir si la base de données a été mal conçue dès le départ. Ajoutons donc une table de relations appelée Tâches, s'interposant entre la table des réparations et la table du personnel.
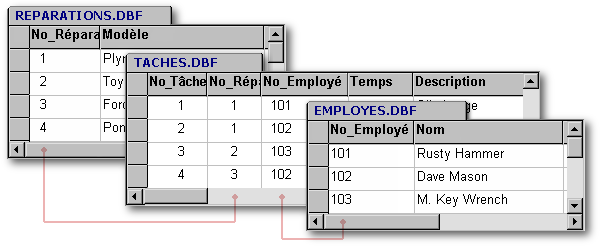
Nous avons maintenant une relation M:M (de multiple à multiple) entre la table des réparations et la table du personnel. En effet, la table des tâches permet d'enregistrer lorsque plusieurs membres du personnel ont été assignés à une réparation et inversement, à enregistrer toutes les réparations auxquelles un employé a contribué.
Par contre, la table des tâches entretient une relation 1:M (de un à multiple) avec chacune des deux autres tables. En effet, chaque tâche est relative à une seule réparation et un seul employé. À l'inverse, un employé peut s'être vu attribué plusieurs voitures à réparer et une réparation peut avoir fait l'objet de plusieurs tâches selon sa complexité.
Mais quelle est la relation entre la table des clients et celle des réparations ? S'agit-il d'une relation 1:M ? Si oui, ajoutez simplement un nouveau champ à la table des réparations qui contiendra la clé primaire de la table des clients, comme suit :
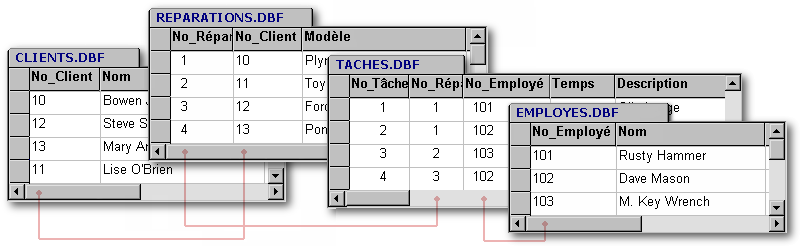
Incidemment, ce nouveau champ sur lequel seront liées les deux tables s'appelle ici une clé externe.[5] Une clé externe est la copie d'une clé primaire d'une autre table. Les relations 1:M des bases de données relationnelles sont toutes basées sur des clés externes.
Si vous voulez permettre une relation M:M entre la table des réparations et la table des clients, il vous faudra alors intercaler une nouvelle table comme celle-ci :

| Mise en garde! |
| On parle souvent de table-parent et de table-enfant pour qualifier les tables liées par une relation 1:M. Cette relation est alors décrite comme un lien parent-enfant. En réalité, sous dB2K, dans ce lien parent-enfant, n'importe quelle table peut occuper le rôle de parent, selon le besoin. C'est pourquoi je suggère d'éviter cette terminologie au sein de la communauté des programmeurs dBASE. En dehors de notre communauté, soyez prévenu que le lien parent-enfant peut être un élément de la conception des bases de données. |
Exemple 2 : Une table de faits historiques
La plupart des bases de données renferment des faits relativement contemporains : on y consigne les salaires actuels versés aux employés ou la dernière commande d'un client.
Plusieurs bases de données
ont des tables de faits historiques. Ces tables renferment des informations
valides à un moment précis (la météo, les cotes
boursières, etc.) et où l'on désire suivre l'évolution
des données avec le temps. On doit faire preuve de prudence lorsqu'on
fait interagir des données contemporaines et des faits historiques.
| Conception déficiente | Conception meilleure |
Clientèle // Nom de la table |
Clientèle // Nom de la table |
La meilleure conception a un champ de plus, soit celui de l'adresse d'expédition. On remarquera donc que ce champ fait duplication puisqu'il est présent à la fois dans la table Clientèle et dans la table des profils d'achats. Pourquoi ? N'est-ce pas redondant ?
Pas vraiment. Le champ Adresse_expédition de la table Clientèle sert à inscrire l'adresse actuelle du client. Le champ analogue de la table Profil_achats renferme l'adresse historique d'expédition. Elle est copiée à partir de la table Clientèle au moment d'un achat. Imaginons la séquence d'événements suivants :
La personne qui a conçu la base de données déficiente a présumé que l'adresse d'expédition était une caractéristique du client. On se rend compte qu'il s'agit d'une donnée qui fait partie intégrante des caractéristiques d'une commande au même titre que la liste des produits commandés.
Exemple 3 : La table de validation
Revenons à notre tout premier exemple.
Comment s'assurer d'obtenir des données cohérentes et de qualité ? Un des moyens est de recourir à une table de validation. Ce moyen permet de faire en sorte que l'utilisateur ne peut entrer des données dans un champ qu'en choisissant parmi une liste de valeurs possibles. Par exemple, à la saisie des données relatives à la table du personnel, pour le champ Titre, au lieu d'une boîte de saisie, l'utilisateur pourrait avoir à choisir une valeur dans une liste déroulante des titres.

Les tables de validation ressemblent aux tables de noms mais n'en sont pas. On les distingue par leur structure rudimentaire. Dans certains cas, une table de validation peut ne pas contenir de nom du tout ; c'est le cas de la table Validation_du_titre qui renferme des attributs qui viennent qualifier le personnel, mais aucun nom de personne, de lieu ou d'objet.
La règle de Validation
Les tables de validation peuvent être utiles afin d'assurer la cohérence des données. Ces tables ne devraient être constituées que d'une seule colonne qui, de ce fait, en devient la clé primaire. Cette colonne contient la liste des valeurs valides.
Quand une table de validation devient une table de noms
Si votre entreprise enregistre dans une table davantage de données que les simples informations nécessaires à la validation, c'est que vous utilisez une table de noms et non une table de validation. Par exemple, on pourrait ajouter l'échelle salariale de l'entreprise à la table Validation_du_titre, et renommer cette table Emplois.dbf. On obtiendrait alors ce qui suit :

Cette table pourrait alors être liée à la table du personnel comme suit :
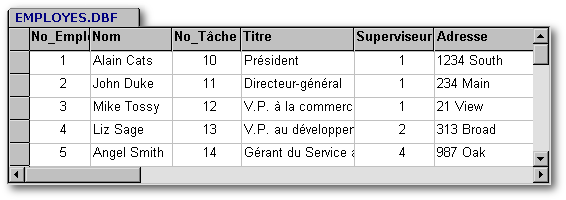
Note relative au champ Titre : Selon l'entreprise, le titre peut être un attribut de l'employé ou du poste qu'il occupe. Dans ce dernier cas, l'exemple ci-dessus est inexact puisque le champ Titre devait plutôt être dans la table du personnel. Dans l'exemple ci-dessus, nous avons présumé que le titre était un attribut de l'employé : c'est pourquoi la colonne Titre est dans la table du personnel. À preuve, le titre des employés 1 et 3 ne concorde pas exactement avec le titre recommandé des postes qu'ils occupent. Les règles d'entreprise déterminent donc quelle est la table qui renfermera les titres.
Pensez aux entreprises pour lesquelles vous avez travaillé. Quelles étaient les règles concernant les titres ? Comment concevoir les tables de manière à refléter ces règles ? L'exemple ci-dessus reflète mes observations personnelles sur la manière avec laquelle les compagnies américaines opèrent dans les faits. Cette conception de la base de données est plus flexible que celle qui requiert que l'employé porte le titre exact du poste qu'il occupe.
À l'aide de règles d'entreprise, il est plus facile d'accroître la rigidité d'une base de données flexible que d'essayer d'assouplir une base de données conçue de manière rigide. Une base de données rigide manquera toujours de souplesse. De plus, il est plus facile de modifier des règles d'entreprise que de changer a posteriori la structure d'une base de données.
Un système établi dure longtemps. Chacun des systèmes que vous concevrez devra tenir compte des divers contextes d'affaires que rencontrera l'entreprise au cours de la durée de vie de ce que vous aurez mise en place. Si possible, assurez-vous de la souplesse d'adaptation de votre base de données, quitte à renforcer sa rigidité par des règles d'entreprise.
Un exemple à éviter : l'encodage
Certaines personnes soutiennent que l'exemple de validation que nous venons de donner est erroné. Selon eux, pour effectuer une normalisation appropriée, le titre ne devrait pas être enregistré directement dans la table du personnel mais devrait plutôt se trouver dans une table liée à la table du personnel de la manière suivante.

Quant à elle, la table du personnel devrait être comme suit :
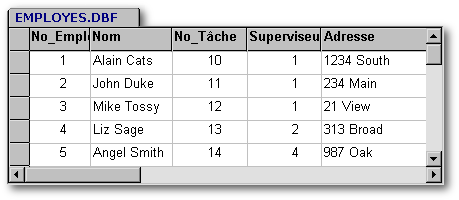
À mon avis, il s'agit d'un cas d'encodage et non de normalisation. Comment peut-on distinguer entre les deux ? L'encodage ne fournit aucune information supplémentaire. Il ne dit rien de plus de ce que nous savions déjà. Il possède l'avantage de réduire la taille de la base de données (le chiffre 12 prend moins de place que «Vice-Président») mais il nécessite la création d'un lien entre deux tables. Dans la plupart des cas, il est recommandé de recourir à la validation plutôt qu'à l'encodage.
Résumé
Concevoir de manière appropriée une base de données améliore la performance de votre application en faisant en sorte que chaque accès au disque soit plus fructueux et en réduisant le gaspillage d'espace disque. Cela permet également d'effectuer plus facilement des requêtes. Même si le présent article n'en fournit pas d'exemple, cela réduit aussi le nombre de doublons et évite de créer des données conflictuelles. Finalement, sous leur forme définitive, les règles régissant la création des bases de données sont les suivantes :
La règle des noms
La plupart des tables renferment des noms : des personnes, des lieux ou des choses. Chaque rangée d'une table doit permettre de distinguer une des ces personnes, un lieu précis ou une chose en particulier.
La règle des Relations
Soit que des tables qualifient les attributs relatifs à des éléments ou définissent la relation entre les éléments de tables différentes : Qui possède cette voiture ? Qui travaille pour ce service ? Quel produit a été expédié à ce client ?
La règle de la Clé primaire
Toutes les tables ont une clé primaire. Celle-ci est formée d'une ou de plusieurs colonnes qui permettent de distinguer une rangée des autres.
Certaines tables ont une clé primaire dite «naturelle». À l'opposé, certaines tables auront besoin d'une clé primaire dite «artificielle». Puisque chaque table au sein d'une base de données doit absolument avoir une clé primaire, on lui créera donc une clé primaire artificielle si elle ne peut être trouvée naturellement. On pourrait utiliser un champ AutoIncrement à cette fin. Une clé primaire doit être unique et inaltérable. Pour des personnes, il est préférable de créer une clé primaire artificielle.[3]
Lorsqu'une table définie des relations, celle-ci possède toujours une clé primaire naturelle. C'est sur cette clé primaire que se tisse le lien entre deux tables. Dans une table de relations, un champ AutoIncrement ne doit jamais servir à lier cette table de relations à une autre table.
La règle des Attributs
Considérez toutes les colonnes autres que la clé primaire, comme des caractéristiques se rapportant au sujet défini par la clé primaire. Elles contiennent des items descriptifs, des faits ou des attributs se rapportant au sujet. Une colonne doit contenir dans chaque rangée, le même type d'information. Si un attribut ne s'applique pas à un sujet, la case correspondante peut rester vide.
La règle de Validation
Les tables de validation peuvent être utiles afin d'assurer la cohérence des données. Ces tables ne devraient être constituées que d'une seule colonne qui, de ce fait, en devient la clé primaire. Cette colonne contient la liste des valeurs valides.
Le test de la Définition linéaire
Essayez de construire une phrase qui décrit la nature des rangées de votre table. Cette phrase doit être simple. Par exemple : «Chaque rangée correspond à un employé de notre entreprise». Une définition complexe sera suspecte. Par exemple, «Si la valeur de la première colonne est de 1, on a affaire à un employé : si c'est 2, il s'agit d'un enfant d'employé». En somme, votre description doit être linéaire, sans «si», sans «peut-être» et sans «mais par contre».