
Current Downloads
Archived Downloads
Articles
Tips and Tricks
Future Releases
Bug Reports
Update Your Info
Suggestions
dBASE.com Home

Exception Handling
by Ken Chan, 1998
Print Friendly Version
This article is an excerpt from Exploiting the Power of the Visual dBASE 7 Language, presented at the 1998 Borland Developers Conference in Denver, Colorado.
An exception is an interruption in the normal flow of your code. Errors are the main kind of exception that you will encounter, but there are others, as you will see later. The idea behind exception handling is to provide a structured, localized, and flexible way of dealing with exceptions; not just things that you hope never happen (like errors), but also to deal with situations that are likely to happen, and even to use exceptions to your advantage to control the execution of your code.
For example, suppose you want to open a table exclusively. The usual technique is to actually try it, and then determine if it worked. This is a bit more complicated than it used to be.
To digress for a moment: before Visual dBASE 7, a USE <table> EXCLUSIVE would fail and generate an error if the table was already open elsewhere. But now the USE will work, but the table will be opened normally in shared mode, not exclusively, without any error. In most cases you can work around thiswhich really is intended as an interactive convenience featureby then attempting to delete a non-existent index tag. This action requires exclusive use, and you can then check the error: is it the "Tag not found" error, which indicates the table is opened exclusively; or the "Operation requires exclusive use of table" error, which indicates that the exclusive USE failed? (A third possibility is that the table is not indexed at all, in which case you will always get a "Table is not indexed" error, regardless of whether the USE EXCLUSIVE worked. This example covers the vast majority of cases where the table has at least one index.) So, even with an older version of dBASE, the idea was to try something that might cause an error; but because you didn't really want the error to handled like an unexpected and usually fatal error, you need to temporarily change the way errors are handled.
Now back to the real topic: without structured exception handling, you would need to save your global ON ERROR handler, set a temporary local ON ERROR, attempt to delete the non-existent tag, and then restore the ON ERROR handler. This old-style code would look something like this:
#define ERR_TAG_NOT_FOUND 53 #define ERR_REQUIRES_EXCL_USE 110 PROCEDURE UseExcl( cTable ) private cOnError, nErrCode cOnError = set( "ON ERROR" ) && Get the global ON ERROR handler nErrCode = 0 && No error to start with use (cTable) exclusive on error nErrCode = error() && Assign the error code to the variable to be tested delete tag X__Y__Z__ && Attempt to delete non-existent tag on error &cOnError && Restore global ON ERROR return ( nErrCode == ERR_TAG_NOT_FOUND )
If the error is the expected "Tag not found" error, that means the appropriate table was found and opened for exclusive use; the function would return true. Anything else would return false, indicating something is wrong. But notice how cluttered the code is with the saving, setting, and resetting of the ON ERROR handler. The code is much simpler with structured exception handling:
function UseExcl( cTable )
use (cTable) exclusive
TRY
delete tag X__Y__Z__ // Attempt to delete non-existent tag
CATCH ( Exception e )
return ( e.code == ERR_TAG_NOT_FOUND )
ENDTRY
The keywords TRY, CATCH, and ENDTRY are the building blocks of the exception handling structure. The TRY and ENDTRY mark the beginning and end, just like IF and ENDIF mark the beginning and end of a conditional structure. After the TRY statement is any code that may, or definitely will, cause an exception. A CATCH marks the end of that code. If an exception occurs, execution jumps to that CATCH. In the parlance of exception handling, dBASE will "try" the code. Any code that fails, "throws" an exception. The exception is "caught" by the CATCH.
Catching exceptions
In keeping with Visual dBASE's object-oriented architecture, an exception is represented by an object. The simplest kind of exception is an instance of the class Exception. There is also a stock DbException class, which is a subclass of the Exception class specifically for data access errors. You can also subclass the Exception class to create your own exception classes, which you will see later.
Each CATCH statement declares a class name and a variable name inside parentheses. The class name is not case-sensitive. You may use any variable name you want; the variable is automatically considered to be local to the function. (If you use the name of a local variable that already exists in the function, the variable will be overwritten if that CATCH is executed.) When an exception occurs, the class in each CATCH statement is checked against the class of the exception that occurred.
The declared class name matches the exception object by either being the exact same class as the object, or by being a superclass of the exception. Because the class Exception is the base class for all exception classes, it will match all exception objects. Most exception handling structures are designed to handle plain dBASE errors, which are represented by Exception objects. Therefore, there is often only one CATCH, with the class Exception.
If the declared class matches the class of the exception, then the exception object is assigned to the declared variable name, and the statements in that CATCH block are executed.
Handling exceptions
Once inside the CATCH block, you can do whatever you want, including nothing (if you have no executable statements between the CATCH and the ENDTRY). In that case, the exception is simply ignored, as if it did not happen. In any case, after the CATCH block is complete, execution continues with the statement after the ENDTRY.
A CATCH block is not a subroutine. You cannot go back to the line that caused the error, or the line after the error, as you can with RETRY and RETURN with ON ERROR handling. Execution jumps to the CATCH block, and continues from there.
When taking an action in a CATCH block, it often involves some aspects of the exception, which are reflected in its properties. The two main properties of interest in an Exception object are the code and message properties. These correspond to the error code and message that you would get with the ERROR( ) and MESSAGE( ) functions in the old-style error handling system. There are also lineNo and filename properties, which contain the line number and name of the file where the exception occurred. All four properties are set by Visual dBASE when an error occurs. If you create your own exception objects, these properties are zero and blank by default.
In the example, the exception's code property is examined to see which error occured. Note that the way the example is structured, it assumes that the DELETE TAG line will always cause an error; otherwise, the function simply ends, and does not RETURN a value. Also, the USE statement is before the TRY. If you specify a bad file name for example, an error will occur outside the exception handling structure, which would cause the standard error dialog to appear.
Nesting TRY blocks
What happens if there is an error while executing the CATCH? That error generates another exception, but it does not execute the same CATCH recursively. No, the code in the CATCH is outside the code that is being "tried", so the current CATCH does not apply.
What happens if there is no CATCH statement that declares a matching exception class? (Or what if there's no CATCH at all, which you will see later?) In this case, what you end up with an "uncaught" exception.
There are two mechanisms for handling these problems. The primary one is nesting TRY blocks. Whenever an exception occurs, it goes "up" the hierarchy of nested TRYs to find a suitable CATCH. For example, you can nest TRYs in the same routine:
try
try
// Some code that might throw an exception
catch ( Exception e )
// Catch exceptions here
// If there are exceptions in this CATCH
endtry
catch ( Exception e )
// they get caught here
endtry
But if you're concerned about an exception occurring in your CATCH, you could handle the exception inside its own TRY block:
try
// Some code that might throw an exception
catch ( Exception e )
try
// Handle the exception here
// If this code fails, then
catch ( Exception e )
// It gets caught here and goes no further
// (But if you get an error here, you will have an uncaught exception)
endtry
endtry
TRY blocks also nest into separate routines, because the subroutine you are executing is being "tried". Examine how exceptions would be handled in the following code:
try
someFunction() // Tries calling another routine
catch ( Exception e )
// Any uncaught exceptions in someFunction() come here
endtry
function someFunction
// An exception here will go the CATCH in the caller
try
// If an exception occurs here
catch ( Exception e )
// it gets caught here.
// But if an exception occurs during this CATCH,
// it causes its own exception, which will go back
// to the CATCH in the caller
endtry
// Outside the TRY again, an exception here will go to
// the CATCH in the caller
nestedFunction() // Call another nested routine
return
function nestedFunction
// An exception here will go all the way back to the first CATCH
return
ON ERROR and exceptions
So far, you've seen exception handling as a replacement for the global ON ERROR mechanism. But ON ERROR can still serve a purpose.
If an exception occurs that is not caught by a CATCH, it eventually causes a system error: "No CATCH for exception," with the class name of the exception, and the exception object's message property. Try it:
try ? xyz // No such variable catch ( DbException e ) // Exception class does not match // Exception is not caught endtry
Running this code in a program produces the standard error dialog:
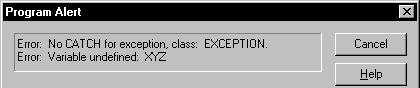
You can use ON ERROR as a "global" catch, a final catch-all for exceptions that are not properly handled. As with most errors handled by a global ON ERROR handler, this is probably a fatal error in your application, something you want to handle more gracefully than with the standard error dialog. The following stripped-down example is just slightly less abrupt:
// In your application startup, assign ON ERROR handler
on error do GlobalErrorHandler with program(), line()
// Code that fails
try
? xyz // No such variable
catch ( DbException e )
// Exception class does not match
// Exception is not caught
endtry
// Handler in procedure or LIBRARY file
#define ERR_NO_CATCH 22
function GlobalErrorHandler
if error() == ERR_NO_CATCH
// Log error here
msgbox( "A serious problem has occurred", "Bye!", 16 )
quit
endif
(Warning: in v7.01, dBASE may crash when the ON ERROR handler is finished handling the "No CATCH for exception" error, which makes the explicit QUIT all the more necessary.)
Throwing exceptions
Nested TRY blocks let you localize and focus your exception handling as needed. But what if you want to handle certain exceptions differently? Remember that an exception is considered a failure in the code that is tried, and there is no way to go back. Suppose you want to ignore or handle some expected exceptions, but cancel the process and generate an error message for the rest. You can do this with the THROW command.
THROW will generate an exception at that statement. Most often you will THROW exceptions that you have caught with CATCH. For example:
try
// A multi-step process
try
// Step 1
catch ( Exception e )
if e.code # ERR_THATS_OK // Is it the error you want to ignore?
throw e // If not, re-throw exception up a level
endif // Otherwise, exception is ignored and
endtry // execution continues
try
// Step 2
catch ( Exception e )
if e.code == ERR_YOU_EXPECT // Is it an error you can handle?
// Handle error (and then execution continues)
else
throw e // If not, re-throw exception up a level
endif
endtry
// etc
catch ( Exception e ) // THROWn execeptions caught here
msgbox( e.message, "Process failed", 16 )
endtry
Note that if you THROW an exception in the CATCH for Step 1, it does not get caught by the CATCH in Step 2, because that CATCH is for the code inside Step 2's TRY. By re-throwing all unhandled exceptions, they can be caught and handled by the same CATCH at a higher level, streamlining your code.
Simulating exceptions
You can also use THROW to simulate exceptions to test your exception handling code. For example:
fakeException = new Exception()
fakeException.code := 5000 // Code for whatever error you want to test
fakeException.message := "Test error"
try
// Normal code
throw fakeException // Statement inserted to simulate failure
// More normal code
catch ( Exception e )
if e.code == 5000
// Do whatever
endif
endtry
Using FINALLY
Many types of operations require some kind of cleanup, even if the operation fails. For example, if you have a process that creates temp files, you always want to delete those files, even if an error prevents the process from completing. Visual dBASE 7 provides a very easy and powerful way of implementing this type of behavior: with FINALLY.
FINALLY is another keyword like CATCH. It must be inside a TRY...ENDTRY block. Every TRY...ENDTRY must have at least one CATCH, or a FINALLY; or it can have both. Although a TRY can have more than one CATCH, it can only have one FINALLY. When a TRY has both a CATCH and a FINALLY, the FINALLY is usually placed at the end.
The code in the FINALLY block is always executed, whether the code in the TRY completes successfully or not. For example:
try fTemp = new File() fTemp.create( "TEMP.$$$" ) // Do some processing, which might fail msgbox( "Finished at " + time(), "Process complete", 64 ) catch ( Exception e ) msgbox( e.message, "Process failed", 16 ) finally fTemp.close() erase TEMP.$$$ endtry
What can happen with this code?
- If the processing finishes successfully, then
- The "Process complete" message is displayed. The code in the TRY block is done.
- The CATCH block is skipped, because no exeception occurred.
- The FINALLY block is executed.
- If the processing fails at some point, then
- Execution jumps to the CATCH. The declared class matches the exception object, so
- The "Process failed" message is displayed. The CATCH is done, so
- The FINALLY block is executed.
Now, although the FINALLY block clearly indicates to anyone reading the code that the file cleanup is an important final step in the process, in this case, the code would have worked just as well if you had put the file close and delete after the ENDTRY, without a FINALLY at all. If there was an exception, it would be handled by the CATCH, and execution would continue after the ENDTRY regardless. But suppose you want to return a value to indicate whether the process completed successfully. With FINALLY, you can do this:
try fTemp = new File() fTemp.create( "TEMP.$$$" ) // Do some processing, which might fail msgbox( "Finished at " + time(), "Process complete", 64 ) catch ( Exception e ) msgbox( e.message, "Process failed", 16 ) return false // Didn't work finally fTemp.close() erase TEMP.$$$ endtry return true // All done, finished successfully
Here, the CATCH has a RETURN statement, which would normally cause execution to return back to the caller. But a FINALLY guarantees that the code will be executed. So before this code returns, the FINALLY is executed, closing and deleting the file. In fact, you can even do this:
try fTemp = new File() fTemp.create( "TEMP.$$$" ) // Do some processing, which might fail msgbox( "Finished at " + time(), "Process complete", 64 ) return true // All done, finished successfully catch ( Exception e ) msgbox( e.message, "Process failed", 16 ) return false // Didn't work finally fTemp.close() erase TEMP.$$$ endtry
What happens is:
- If the processing finishes successfully, then
- The "Process complete" message is displayed.
- The function attempts to RETURN the value true to its caller.
- But because the RETURN is inside a TRY that has a FINALLY, the FINALLY block is executed.
- Inside the FINALLY block, the file is closed and deleted.
- The function returns true.
- If the processing fails at some point, then
- Execution jumps to the CATCH. The declared class matches the exception object, so
- The "Process failed" message is displayed.
- The function attempts to RETURN the value false to its caller.
- But because the RETURN is inside a CATCH for a TRY that has a FINALLY, the FINALLY block is executed.
- Inside the FINALLY block, the file is closed and deleted.
- The function returns false.
With FINALLY, you avoid having to create a temporary variable to store the return value while you do the cleanup. The code is easier to write and easier to read, and clearly indicates the intent of the program flow.
If there is a RETURN statement inside the FINALLY block, then it takes precedence. If it returns a value, that value supercedes the value (if any) returned by the original RETURN that caused the FINALLY to be executed. The RETURN is acted upon immediately, skipping any other statements in that FINALLY block. Execution will return to the caller, unless of course that TRY structure is nested inside another TRY with its own FINALLY.
Using FINALLY with loops
FINALLY also works for code deviations inside loops; namely the EXIT and LOOP commands. For example, suppose you have a deeply nested set of IF...ENDIF structures inside a loop. The loop uses an associative array, so it must increment the key value using the nextKey( ) method. If you want to get out of a deeply nested IF to skip that particular element, you can put the LOOP command inside a TRY, and in the FINALLY, increment the key value:
cKey = aAssoc.firstKey
do while not cKey == false
try
if someCondition
// Some processing
if someOtherCondition
// More stuff
if etc
// And so on
// At some point, you decide to skip the rest
loop // Go to next element
endif
// If you want to skip the rest, you want to bypass this
endif
// and this
endif
finally
// but always execute this, difficult to do without TRY/FINALLY
cKey := aAssoc.nextKey( cKey )
endtry
enddo
Using FINALLY with no CATCH
In addition to being an example of FINALLY with the LOOP command, that was also an example of a TRY that has a FINALLY, but no CATCH. If there is no CATCH, then the FINALLY marks the end of the code that is "tried".
Another example of when you might have this is a variation on the file processing code above. Suppose it was part of a larger operation, using nested TRY structures to manage any errors:
// Main operation try processFile( someFile ) // Call file processing // Do something else that might cause an exception catch ( Exception e ) // All errors come here msgbox( e.message, "Operation failed", 16 ) endtry function processFile( cFilename ) try fTemp = new File() fTemp.create( "TEMP.$$$" ) // Do some processing, which might fail finally fTemp.close() erase TEMP.$$$ endtry
In this example, if the file processing fails, then the cleanup code in the FINALLY block executes. But because the exception was not caught, the exception "bubbles up" to the previous level, and gets caught by the CATCH in the main operation. The advantage with this kind of structure is that all the exception handling, in this case the display of a message, is handled in a single location.
Creating custom exception classes
You can create your own exception classes to take advantage of the execution flow control provided by exceptions, while differentiating your exceptions from genuine errors. Extending the file processing example, suppose you're translating a file from one format to another. There are many different places where the translation could fail. The file could be missing, it might not appear to be in the correct format, it may be in an older unsupported format, it might have invalid characters, it could fail internal integrity checks, and so on. If any of these conditions occur, all you can do is give up. Exceptions give you an easy and direct way to jump back all the way to a known point in your program.
The first task is to create your own exception class. One convenience you can include is to provide an easy way to assign information to the exception object when you create it, like setting its message property:
class FileProcException( cMsg ) of Exception this.message := cMsg endclass
When creating your own subclasses, you can of course add your own properties. Suppose for an invalid character, you want to store that character as a separate property. You create an even more specific subclass:
class InvalidFileCharException( cChar ) of ;
FileProcException( "Invalid character in file" )
this.invalidChar = cChar // New property
endclass
(Note that in defining this subclass, the parameter cChar is not passed to the subclass; instead, a constant string is passed. While this might seem strange, it is appropriate and perfectly legal. All InvalidFileCharException objects will have the same message.)
Now you have to create separate CATCH blocks for each exception class that you want to handle differently. If you have more than one CATCH statement inside a single TRY...ENDTRY, you must declare the classes from most specific to least specific, because superclasses are considered a match. Suppose you only want to differentiate between your custom exceptions and standard errors:
for n = 1 to fileList.size // Process a list of files
cFilename = fileList[ n ] // Get the filename from the list
try
processFile( cFilename )
catch ( FileProcException e )
msgbox( e.message, "Failed to process: " + cFileName, 48 )
// Display message and continue loop for next file
catch ( Exception e )
msgbox( e.message, "Error on line " + e.line, 16 )
// Stop on system errors
return
endtry
endfor
In the file processing code, you would THROW the exception like this:
// Somewhere in some function, the version number has been // extracted from the file into the variable nVersion if nVersion < 2 throw new FileProcException( "Obsolete file version not supported" ) endif
As shown above, the processFile( ) function should do its work in a TRY with a FINALLY but no CATCH, so that if an exception occurs, the proper cleanup can be done, and the CATCH can be handled at a higher level, inside the main loop in this case.
For the more specific invalid character exception, the code might look like:
// Somewhere in some function, a character has been extracted into the // variable cType that indicates the kind of information that follows. if cType == INDICATOR_CHAR // Some #DEFINEd character constant // Do whatever else // But if that character is not recognized... throw new InvalidFileCharException( cType ) endif
As the main loop stands now, the InvalidFileCharException will be caught in the first CATCH as a FileProcException, which it is. But suppose you want to handle the specific exception differently, like counting how many of each bad character you encounter:
aBadChar = new AssocArray() // For invalid characters encountered
for n = 1 to fileList.size // Process a list of files
cFilename = fileList[ n ] // Get the filename from the list
try
processFile( cFilename )
catch ( InvalidFileCharException e )
if aBadChar.isKey( e.invalidChar ) // If the bad character has been found before
aBadChar[ e.invalidChar ]++ // increment the count
else
aBadChar[ e.invalidChar ] = 1 // Otherwise, create a new array element
endif
// Same code as base class exception
msgbox( e.message, "Failed to process: " + cFileName, 48 )
catch ( FileProcException e )
msgbox( e.message, "Failed to process: " + cFileName, 48 )
// Display message and continue loop for next file
catch ( Exception e )
msgbox( e.message, "Error on line " + e.line, 16 )
// Stop on system errors
return
endtry
endfor
Because the CATCH is for a specific class of exception, you can confidently access custom properties for that exception object. Also note that to duplicate the actions for the base class, the statements must be repeated explicitly. Like in a CASE structure, only one CATCH is executed.
Exceptions in event-driven programming
All this exception handling power has one major caveat: a TRY covers a single "thread" of execution. (The term "thread" is used loosely here because dBASE does not support true multi-threading as some languages do.) For example, if you do this:
try do SomeForm.wfm // Open a form catch ( Exception e ) // Handle any exceptions endtry
Any exceptions that occur while instantiating and opening the form will be caught. But once the form is open, the DO statement is done, which means the TRY block is done, and execution continues with the statement after the ENDTRY. This particular exception handling structure no longer applies. Any exceptions that occur while clicking a button on the form, or adding a row of data, or anything else on that form will not be caught here, because those actions occur in their own separate event.
Currently, there is no general solution for this problem. Ideally, there should be some way to setup exception handling in some form for a given event or set of events. But even without this capability, exception handling is a powerful and flexible way to manage the execution of your application.
Home | Top
Copyright 1999-2004 dBASE Inc.